2024年最全Python使用Scrapy框架爬取数据存入CSV文件_python scrapy保存csv
注意事项:scrapy和twisted存在兼容性问题,如果安装twisted版本过高,运行scrapy startproject project_name的时候会提示报错,安装twisted==13.1.0即可。

- 安装scrapy

注意事项:scrapy和twisted存在兼容性问题,如果安装twisted版本过高,运行scrapy startproject project_name的时候会提示报错,安装twisted==13.1.0即可。
- 基于Scrapy爬取数据并存入到CSV
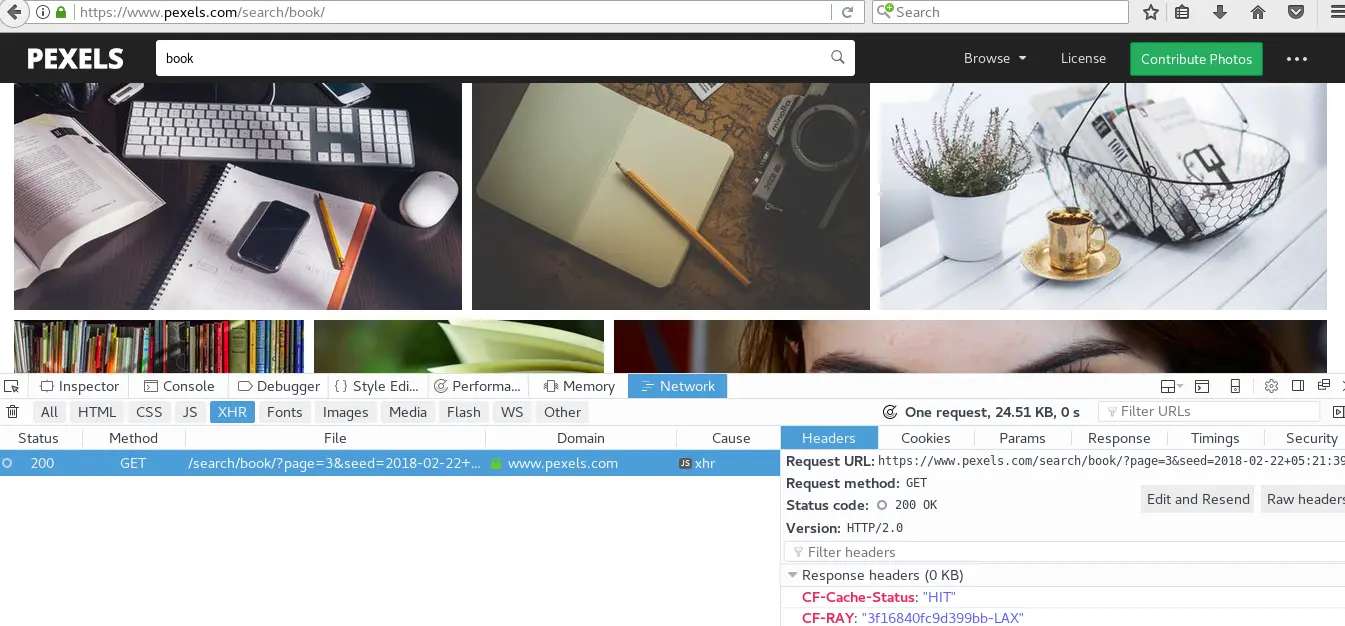
3.1. 爬虫目标,获取简书中热门专题的数据信息,站点为https://www.jianshu.com/recommendations/collections,点击"热门"是我们需要爬取的站点,该站点使用了AJAX异步加载技术,通过F12键——Network——XHR,并翻页获取到页面URL地址为https://www.jianshu.com/recommendations/collections?page=2&order_by=hot,通过修改page=后面的数值即可访问多页的数据,如下图:
3.2. 爬取内容
需要爬取专题的内容包括:专题内容、专题描述、收录文章数、关注人数,Scrapy使用xpath来清洗所需的数据,编写爬虫过程中可以手动通过lxml中的xpath获取数据,确认无误后再将其写入到scrapy代码中,区别点在于,scrapy需要使用extract()函数才能将数据提取出来。
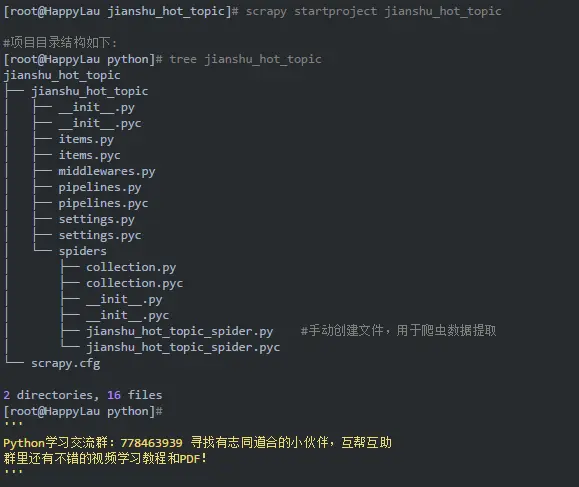
3.3 创建爬虫项目
3.4 代码内容
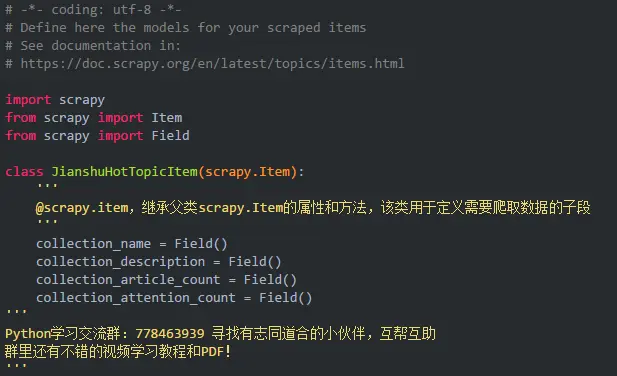
- items.py代码内容,定义需要爬取数据字段
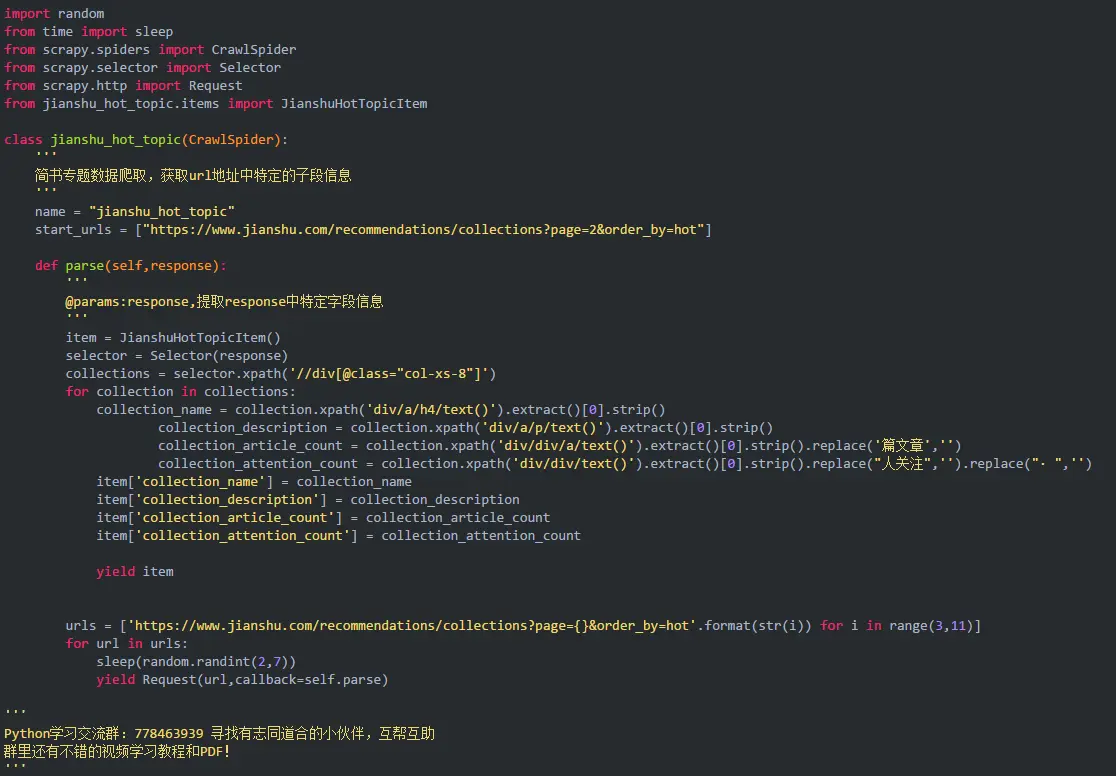
2. piders/jianshu_hot_topic_spider.py代码内容,实现数据获取的代码逻辑,通过xpath实现
3. pipelines文件内容,定义数据存储的方式,此处定义数据存储的逻辑,可以将数据存储载MySQL数据库,MongoDB数据库,文件,CSV,Excel等存储介质中,如下以存储载CSV为例:

4. 修改settings文件,
3.5 运行scrapy爬虫
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ics/618317507)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)