【python】PythonQQ音乐数据抓取词云可视化(源码+数据集)【独一无二】
python】PythonQQ音乐数据抓取词云可视化(源码+数据集)【独一无二】
·
1. 数据集显示
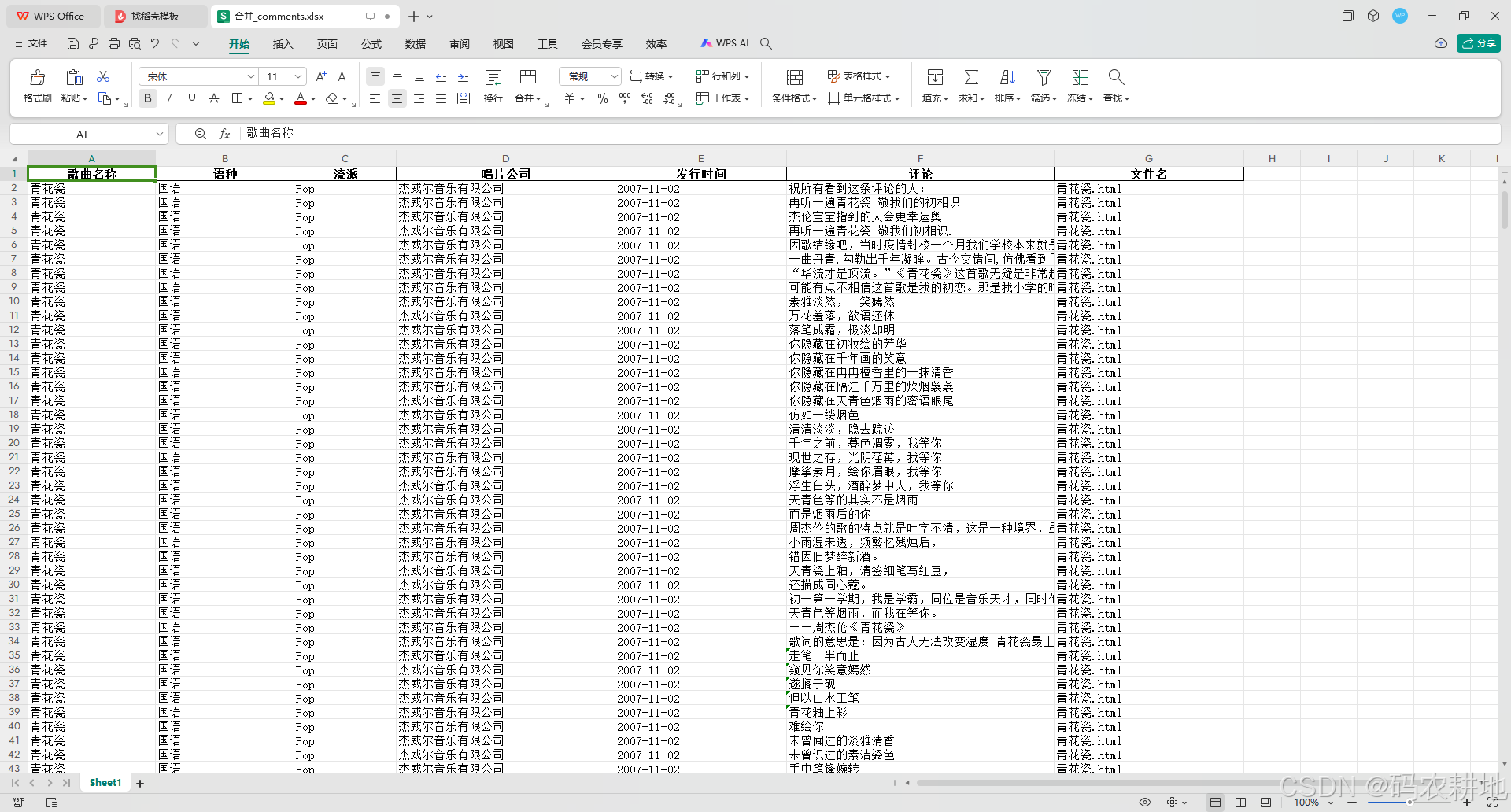
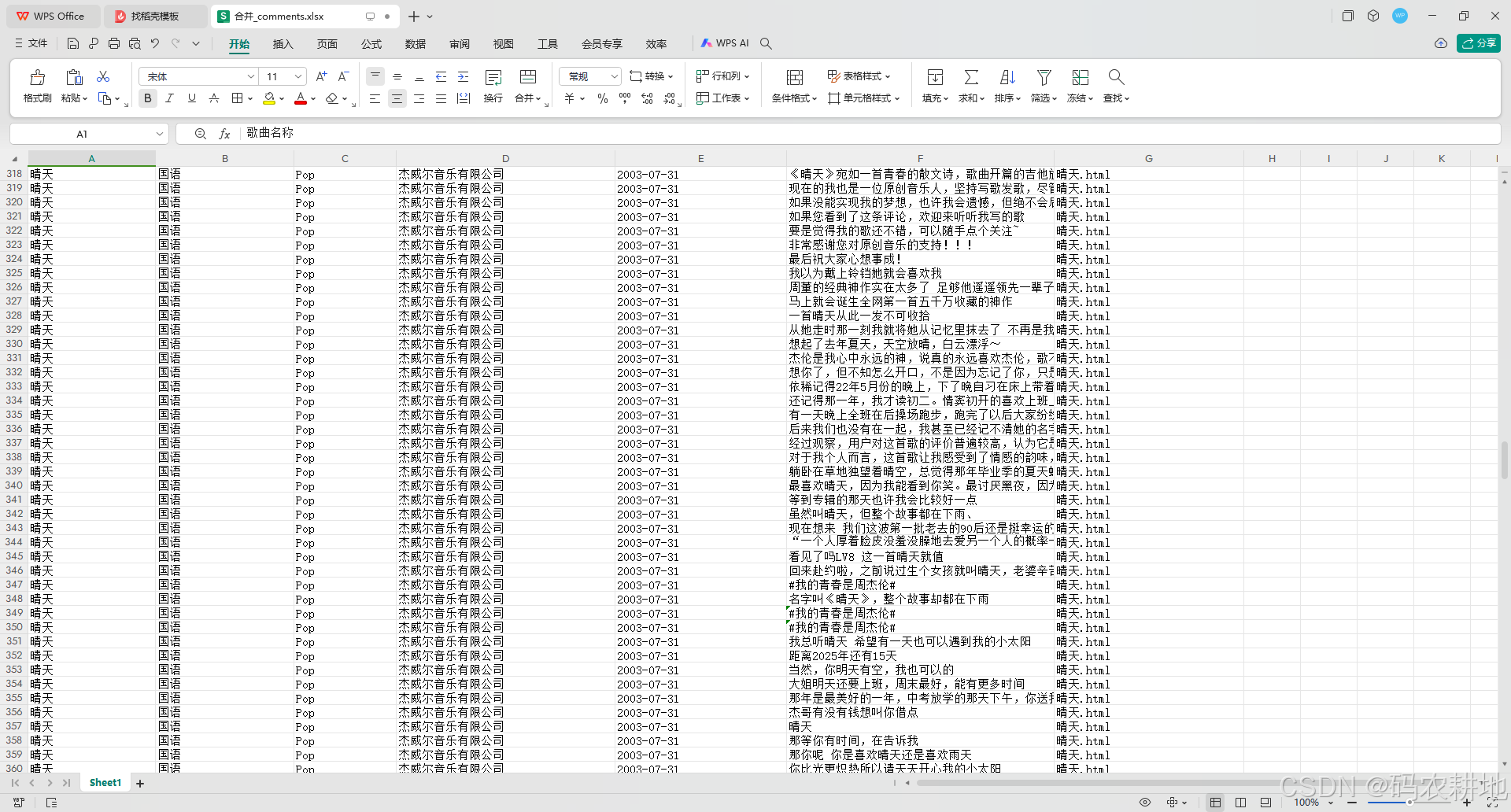
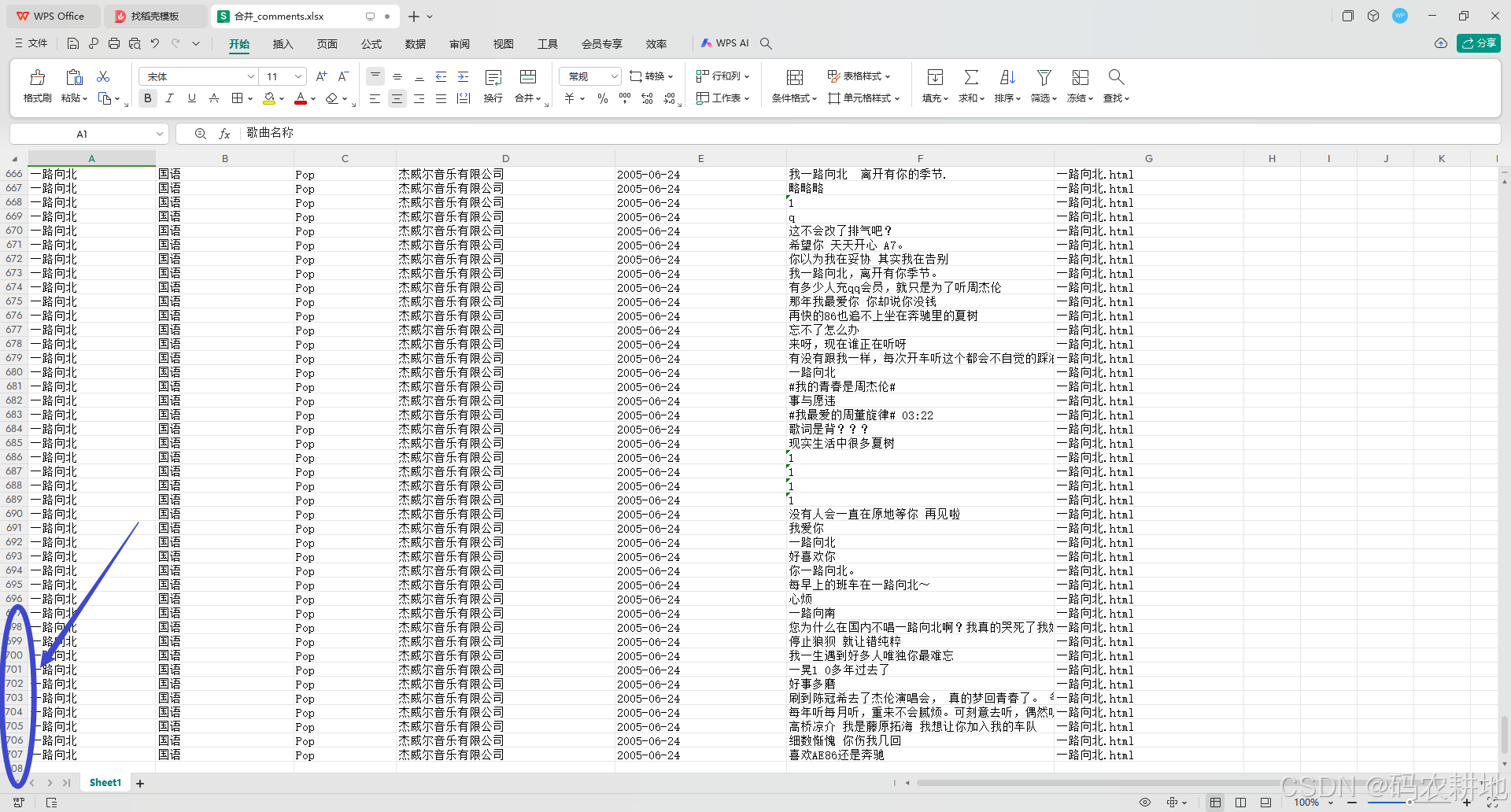

2. 代码结构分析
1. 文件头部与模块引入
from lxml import etree
import pandas as pd
import os
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
-
模块功能:
lxml.etree:解析 HTML 文件。pandas:存储和操作表格数据。os:处理文件路径。jieba:中文分词工具。collections.Counter:统计词频。wordcloud:生成词云。matplotlib.pyplot:可视化工具。
-
全局配置:
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False- 设置字体和负号显示,确保在生成图表时支持中文和符号。
2. HTML 文件解析与评论提取
combined_df = pd.DataFrame()
- 目标文件:指定了多个 HTML 文件作为数据源,文件路径存储在
file_paths列表中。 - 数据合并表:使用
pandas.DataFrame()初始化一个空表,用于存储解析结果。
2.1 文件读取与解析
with open(file_path, 'r', encoding='utf-8') as file:
html_content = file.read()
tree = etree.HTML(html_content)
- 逐一读取文件内容,使用
lxml.etree.HTML解析 HTML 结构。
2.2 信息提取
song_name = tree.xpath('//h1[@class="data__name_txt"]/text()')[0].strip()
language = tree.xpath('//*[@id="app"]//ul/li[@class="data_info__item_song"][2]/text()')[1].split(":")[-1].strip()
...
comments = tree.xpath('//p[@class="comment__text "]/span/text()')
- 使用 XPath 表达式提取特定信息:
- 歌曲详情:如歌曲名称、语种、流派、唱片公司、发行时间等。
- 评论内容:所有评论存储在
comments列表中。
2.3 数据组织与合并
data = {
"歌曲名称": [song_name] * len(comments),
...
"评论": comments,
"文件名": [os.path.basename(file_path)] * len(comments)
}
df = pd.DataFrame(data)
combined_df = pd.concat([combined_df, df], ignore_index=True)
- 将提取的数据组织成字典后转为
DataFrame。 - 通过
pd.concat将每个文件的解析结果合并到combined_df中。
2.4 数据保存
output_file = "合并_comments.xlsx"
combined_df.to_excel(output_file, index=False, encoding='utf-8')
- 将合并后的数据存储为 Excel 文件
合并_comments.xlsx,便于后续分析。
3. 数据分析与可视化
3.1 数据读取
df = pd.read_excel(file_path)
- 从保存的 Excel 文件中读取评论数据和歌曲信息。
3.2 基本信息统计
song_info = df[["歌曲名称", "语种", "流派", "唱片公司", "发行时间"]].drop_duplicates()
print(song_info)
- 显示每首歌曲的基本信息(去重)。
3.3 评论词频统计
comments = " ".join(df["评论"].dropna())
words = jieba.lcut(comments)
stop_words = {"的", "了", "是", ...}
filtered_words = [word for word in words if word not in stop_words and len(word) > 1]
word_counts = Counter(filtered_words)
print(word_counts.most_common(20))
- 合并所有评论并使用
jieba.lcut进行中文分词。 - 去除停用词(常用无意义词)和长度为1的词,保留高频词并统计出现次数。
3.4 生成词云
wc = WordCloud(
font_path='simhei.ttf',
width=800,
height=400,
background_color="white"
)
wc.generate_from_frequencies(word_counts)
wc.to_file("周杰伦词云.png")
- 通过
WordCloud将词频数据可视化。 - 保存生成的词云图片为
周杰伦词云.png。
3.5 词云展示
plt.figure(figsize=(10, 6))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.title("青花瓷 评论词云")
plt.show()
- 使用
matplotlib展示生成的词云。
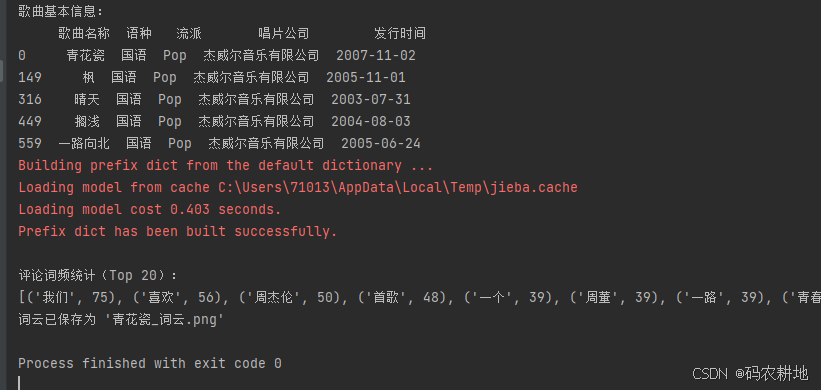
词频统计如下:
[('我们', 75), ('喜欢', 56), ('周杰伦', 50), ('首歌', 48), ('一个', 39), ('周董', 39), ('一路', 39), ('青春', 37), ('向北', 37), ('晴天', 36), ('青花瓷', 34), ('自己', 31), ('没有', 29), ('什么', 28), ('好听', 26), ('杰伦', 25), ('现在', 25), ('知道', 25), ('真的', 24), ('旋律', 24)]



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)