【AI大模型大厂面经】百度一面,上来就问RLHF原理...
大模型训练三步走,pre-training、SFT、RLHF。今天来到了第三步,即基于人工反馈的强化学习(Reinforcement learning from human feedback)。对于 NLP 从业者来说,前两步还是比较熟悉的,无非是模型大点、数据多些,但是整个模型的架构、原理和一些 tricks 还是比较容易理解的。但是对于 RLHF,因为其中涉及到了强化学习,所以对于没有接触过强
前言
大模型训练三步走,pre-training、SFT、RLHF。今天来到了第三步,即基于人工反馈的强化学习(Reinforcement learning from human feedback)。
对于 NLP 从业者来说,前两步还是比较熟悉的,无非是模型大点、数据多些,但是整个模型的架构、原理和一些 tricks 还是比较容易理解的。
但是对于 RLHF,因为其中涉及到了强化学习,所以对于没有接触过强化学习的,理解起来还是比较困难的。下面我们就从 NLPer 的视角,理解 RLHF 的原理。
RLHF
(1)强化学习基础
对于 RLHF 来说,强化学习是其核心,所以要想理解 RLHF,必须对强化学习有一点了解。
强化学习中的几个概念:
-
智能体(Agent): 它是强化学习中与环境交互、并执行策略的主体,跳棋中的棋子,gpt 中的 gpt 模型本身;
-
环境(Environment): 某一时刻的空间状态,跳棋中整个棋盘、规则等,gpt 中的所有上下文以及模型状态;
-
状态(state): 状态空间,当有可选的状态集合,跳棋中的上下左右,gpt 中词表;
-
动作(Action): 下一个选择的状态,跳棋中的动作,gpt 中预测的下一个 token;
-
奖励(Reward): 根据 agent 的动作得到的反馈,跳棋中赢下的概率,gpt中输出好句子的概率;
-
累积奖励(Cumulative Reward): 智能体在一系列连续决策中获得的所有奖励之和,目标是最大化这个值。
在强化学习过程中,智能体通过尝试不同的动作,观察环境对其行为的奖励,并根据获得的奖励进行学习,从而调整其策略以期望在未来获得更高的累积奖励。
通过反复迭代这一过程,智能体能够学会在不同状态下的最优行为策略。
类比跳棋就是,通过大量棋局的学习,跳棋会在当前步骤选出最优的下一个动作;GPT 也是可以在当前上下文状态下,生成最优的 token。
简单介绍完,强化学习的一些概念之后,我们进入 RLHF 中的每个细节,首先 Agent 没什么疑问就是 LLM,状态当前的 context(prompt+前面生成的 token),动作也比较好理解就是预测下一个 Token,那么如何得到奖励那,以及优化策略和算法是什么,下面主要看这两个问题。

(2)RM
RLHF 的 Reward 是通过一个 Reward model 模型生成,Reward model 最好和 agent 的 model 能力相似,能对 agent 的结果进行打分。
模型:奖励模型是对 LLM 的输出做判断,奖励模型决定了 LLM 的上限,所以理论上,奖励模型越大越好。
但是模型太大可能面临资源消耗过大,训练不稳定等(在 instruct-gpt 论文中, 作者提到 175B 的模型训练不稳定因此只使用了 6B 的模型作为 RM, 这里应该是作者当时把 RM 作为 critic 起始点, 使得 PPO 需要同时训练 actor & critic 两个大模型, 从而很不稳定)。
另外,建立模型的主要任务是做判别式排序,任务难度相对较小,所以通常比被评估的语言大模型小一些(deepspeed 的示例中,语言大模型 66B,奖励模型只有 350M)。
所以,Reward model 一般也是一个参数量较小的 transformer 模型(instructGPT 的 Reward_model:GPT-3-6B,deepspeed 中的 OPT-13B 的 Reward_model:OPT-350M)。
数据:数据要求格式是 prompt,LLM 生成 K 个(K 是 4-9,这里可以调节温度系数等输出不同答案)答案,人工对 LLM 的答案进行排序。
这里的 prompt 一般来自问答数据集,比如 Anthropic 的 Prompt,GPT 的数据来自于 OpenAI 自家的 API 用户数据。
没有直接对答案进行打分的原因是 OpenAI 发现由于标注人员的认知和价值观的差异,直接标得分,会有很多脏数据,改成排序会好很多。
虽然数据是排序的,但是,这些不同的排序结果会通过某种归一化的方式变成标量信号(即 point-wise)丢给模型训练。
损失函数:上面说了数据的格式,模型需要做的就是对输入的 prompt 和一好一坏的两个答案进行分类(可以理解成二分类),那么直观的一个损失就是用交叉熵损失(cross entropy loss)。
但是作者发现这么做很容易过拟合;也不高效,因为每比较一次都要重新过一下 reward model。

Reward Model 的初始化:6B 的 GPT-3 模型在多个公开数据((ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, and Winogrande)上 fintune。
不过 Paper 中提到其实从预训练模型或者 SFT 模型开始训练结果也差不多。
(3)PPO 算法
强化学习的优化算法分三大类,这里主要说一下基于基于策略的 PPO 算法(即 ChatGPT 中用到的算法)。
PPO 算法是基于 Actor-Critic 算法做的,Actor-Critic 算法是进阶版的 Policy Gradient 算法。
Policy Gradient(PG)算法:

上面提到,agent 会与环境交互作出动作,和环境交互后是根据什么策略做动作那。
PG 算法的核心是用“Reward”作为权重,最大化策略网络所做出的动作的概率。

虽然在强化学习算法中对每一步都有一个即时的“reward”,但是每一步对后面的可能状态都是有影响的。所以会将未来的奖励累计到当前的奖励上,累计需要乘以一个小于 1 的 r 做折损。
这里需要注意:


Actor-Critic (AC)算法:

上面说了 PG 算法在采样稀疏的情况下,很可能会沿着非最优方向优化(采样成本比较高),所以 AC 算法通过增加一个 Critic 网络来优化这一点。
简单说就是 Critic 网络会需要生成一个期望的奖励,只有获得的 reward 比期望奖励好动作才会被优化,否则抑制它。

关于优势函数——GAE
GAE 是一种用于估计优势函数(Advantage Function)的技术,它通过平衡偏差和方差来提高策略梯度方法的稳定性和效率。
GAE 计算优势函数的原理如下:

PPO

AC 算法存在稳定性问题,特别是深度模型。
为了优化这一点 PPO 算法的做法包括两种,一种是:用拉格朗日乘数法直接将 KL 散度的限制放进了目标函数中,这就变成了一个无约束的优化问题,在迭代的过程中不断更新 KL 散度前的系数:
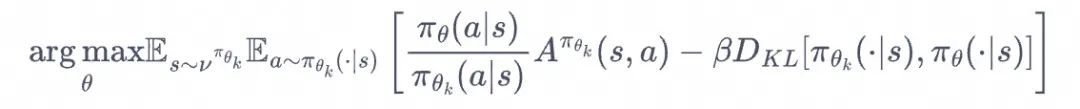
另一种做法比较简单直接,在目标函数中进行限制,以保证新的参数和旧的参数的差距不会太大:
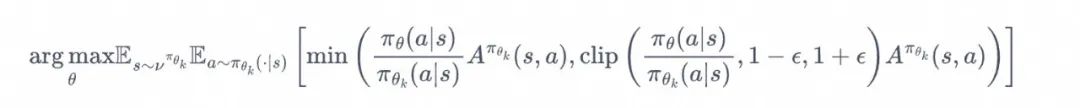
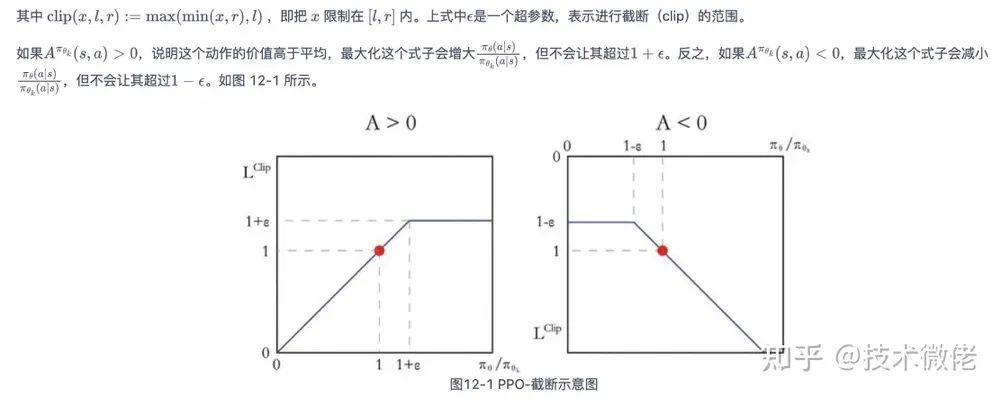
以上就是 PPO 算法的发展和简单的原理介绍。
2、RLHF的PPO
在上面提到的 PPO 算法中我们需要三个模型网络 RM、actor_model(SFT 后的 LLM)、critic_model。
上面提到的 PPO 算法在 LLM 还存在一个问题,就是 LLM 可能会被训练变“废”,LLM 会生成奇怪的文本来骗 RM 得到好的奖励。
为了解决这么问题,引入了一个网络来控制一下 actor_model 让它更新不要太偏离原本的 SFT 后的 LLM,所以通过 KL 散度(作用是控制两个分布之间的差异)。
所以正式的奖励如下:
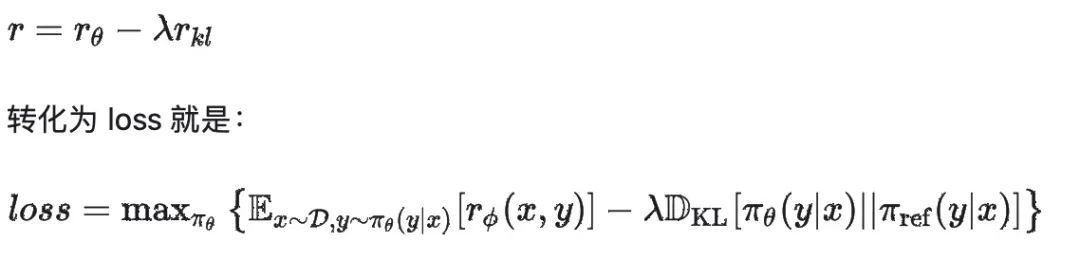
至此 RLHF 中的四个网络就都出现了,分别是:
-
Actor model: SFT 后的 LLM,需要训练的 LLM,参数可变;
-
Ref model: SFT 后的 LLM,用于限制 actor model 的 KL 散度,参数冻结;
-
RM model: 奖励模型,用于强化学习的奖励提供,参数冻结;
-
Critic model: 用于期望奖励生成,参数可变;
RLHF 中有四个模型,这就是为什么它需要显存大了,四个模型中 Actor model 和 Ref model 初始化一致,RM model 和 Critic model 初始化一致。
把这四个网络,结合 reward 的构造,带入到上面提到的 PPO 算法中,整个过程就如下:
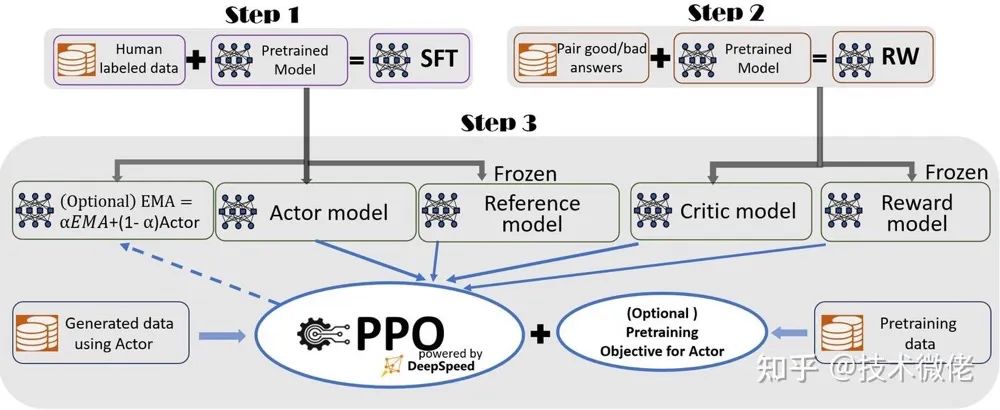
以上我就完成了整个 RLHF 的原理介绍,下面接着跟大家分享代码篇。
3、LLM中的RLHF(代码篇)
对于大模型三部曲的 RLHF,因为其中涉及到 RL 的知识,对于 NLPer 来说相对陌生一点,所以我们重点说一下 RLHF 的原理和代码(以微软的 DeepSpeed-Chat 的代码为例),代码是为了加深原理的了解和里面的细节。
DeepSpeed-RLHF-code
我们主要从代码角度看一下 RLHF 是如何实现的,这里主要介绍一下微软 DeepSpeed 的代码部分。
代码地址:
https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat(DSC)
DSC 代码的特点是:
-
RLHF 阶段的 actor 要在 train (参数更新)和 eval(经验采集)模式中反复切换,不做优化的话整体速度很慢,但是原本 DeepSpeed 的 train 加速和 eval 加速属于是解离的两种方案;
-
DSC 在原本 DeepSpeed 的基础上设计了一个 DeepSpeedHybridEngine 的引擎,使得 actor 在 RLHF 阶段能同时享有 train 和 eval 加速优化,整体提高 RLHF 速度;
DSC 的训练也是分为三个阶段:
-
SFT 阶段
-
RM 阶段
-
PPO 阶段
从以下几个模块介绍一下代码部分会结合原理篇部分。
数据部分
代码位置 dschat/data 下面的 data_utils.py 和 raw_datasets.py,调用逻辑如下:
raw_datasets.py
PromptRawDataset:这是个基类
-
get_train_data:获取train data;
-
get_eval_data:获取eval的data;
-
get_prompt:获取prompt data,数据格式Human: " + 实际prompt + " Assistant,用于PPO阶段;
-
get_chosen:获取chosen data,数据格式:人类接受的回答;
-
get_rejected:获取reject data,数据格式:人类排斥的回答;
-
get_prompt_and_chosen:获取prompt+chosen data数据格式:“Human: {} Assistant: {}”.format(actual_prompt_sentence, actual_response_sentence),用于SFT和RM阶段;
-
get_prompt_and_rejected:获取prompt+reject data数据格式:“Human: {} Assistant: {}”.format(actual_prompt_sentence, actual_response_sentence),用于RM阶段;
其他各数据处理类:其他类包括英文、中文、日语等数据的处理,会继承PromptRawDataset类,对里面的函数重写;
data_utils.py:
-
def get_raw_dataset:根据数据集初始化数据的dataset
-
def get_raw_dataset_split_index:数据集分割,例如8,1,1,就是按照这个比例划分数据集;
-
class PromptDataset:构造阶段1、2、3的数据结构体,是一个类似于torch的Dataset类;
-
def create_dataset_split:将根据不同的阶段(train_phase)对数据集进行处理,主要是调用原先在PromptRawDataset类中定义的实例函数来实现,包括从PromptRawDataset获取数据、tokenizer处理、返回PromptDataset的结果;
-
def create_dataset:构建train和eval的dataset;
-
def create_prompt_dataset: 构建阶段1、2、3的prompt的dataset;
-
class DataCollatorReward:阶段2 batch数据的预处理;
-
class DataCollatorRLHF:阶段3 batch数据的预处理;
-
def get_unsupervised_data: 无监督数据;
-
class MiniDataset:小批次处理数据,防止内存撑爆;
# applications/DeepSpeed-Chat/training/utils/data/data_utils.py
def create_dataset_split(current_dataset, raw_dataset, train_phase, tokenizer,
end_of_conversation_token, max_seq_len):
"""
将根据不同的阶段(train_phase)对数据集进行处理,主要是调用原先在PromptRawDataset类中定义的实例函数来实现。
"""
prompt_dataset = []
chosen_dataset = []
reject_dataset = []
if train_phase == 1:
# 因为phase1只需要用到chosen数据,所以只取chosen进行处理
for i, tmp_data in enumerate(current_dataset):
# 获取chosen_sentence,即是将prompt和chosen拼接起来形成完整对话
chosen_sentence = raw_dataset.get_prompt_and_chosen(
tmp_data)
if chosen_sentence is not None:
# 在对话末尾加入对话终止符
chosen_sentence += end_of_conversation_token
# 使用tokenizer处理chosen_sentence,采取截断truncation
chosen_token = tokenizer(chosen_sentence,
max_length=max_seq_len,
padding="max_length",
truncation=True,
return_tensors="pt")
# 去掉batch维度
chosen_token["input_ids"] = chosen_token["input_ids"].squeeze(
0)
chosen_token["attention_mask"] = chosen_token[
"attention_mask"].squeeze(0)
# 存储tokenize结果至列表chosen_dataset
chosen_dataset.append(chosen_token)
elif train_phase == 2:
# phase2需要用到chosen_sentence和reject_sentence
# 所以需要对两者都进行处理
for i, tmp_data in enumerate(current_dataset):
# 获取chosen_sentence,即是将prompt和chosen拼接起来形成完整对话
chosen_sentence = raw_dataset.get_prompt_and_chosen(
tmp_data) # the accept response
# 获取reject_sentence,即是将prompt和rejeced拼接起来形成完整对话
reject_sentence = raw_dataset.get_prompt_and_rejected(
tmp_data)
if chosen_sentence is not None and reject_sentence is not None:
# 在对话末尾加入对话终止符
chosen_sentence += end_of_conversation_token # the accept response
reject_sentence += end_of_conversation_token
# 使用tokenizer处理,采取截断truncation
chosen_token = tokenizer(chosen_sentence,
max_length=max_seq_len,
padding="max_length",
truncation=True,
return_tensors="pt")
reject_token = tokenizer(reject_sentence,
max_length=max_seq_len,
padding="max_length",
truncation=True,
return_tensors="pt")
chosen_token["input_ids"] = chosen_token["input_ids"]
chosen_token["attention_mask"] = chosen_token["attention_mask"]
# 存储tokenize结果至列表chosen_dataset
chosen_dataset.append(chosen_token)
reject_token["input_ids"] = reject_token["input_ids"]
reject_token["attention_mask"] = reject_token["attention_mask"]
# 存储tokenize结果至列表reject_dataset
reject_dataset.append(reject_token)
elif train_phase == 3:
# phase3用到prompt,prompt将被用来生成经验数据
for i, tmp_data in enumerate(current_dataset):
# 直接获取prompt
prompt = raw_dataset.get_prompt(tmp_data)
if prompt is not None:
prompt_token = tokenizer(prompt, return_tensors="pt")
prompt_token["input_ids"] = prompt_token["input_ids"]
prompt_token["attention_mask"] = prompt_token["attention_mask"]
for key_word in ["input_ids", "attention_mask"]:
# 获取当前文本token的实际长度
length = prompt_token[key_word].size()[-1]
# phase3此处的max_seq_len其实是max_prompt_len,默认只有256
if length > max_seq_len:
# 如果当前文本token长度比max_prompt_len还长
# 那么就截断文本前面的部分,保留后面max_prompt_len长度的部分文本
# 然后将token进行flip(翻转/倒序),之后在data_collator中再将其flip回来
y = prompt_token[key_word].squeeze(0)[length -
(max_seq_len -
1):].flip(0)
else:
# 将token进行flip(翻转/倒序),之后在data_collator中再将其flip回来
y = prompt_token[key_word].squeeze(0).flip(0)
prompt_token[key_word] = y
prompt_dataset.append(prompt_token)
# 返回PromptDataset实例,该实例相当于torch中的Dataset,可供DataLoader调用
return PromptDataset(prompt_dataset, chosen_dataset, reject_dataset,
tokenizer.pad_token_id, train_phase)
模型部分
代码位置 dschat/model 下面的 model_utils.py 和 reward_model.py,调用逻辑如下:
reward_model.py:
import torch
from torch import nn
class RewardModel(nn.Module):
def __init__(self,
base_model, # base模型
tokenizer, # tokenizer
num_padding_at_beginning=0, #开头填充的数量
compute_fp32_loss=False。# fp32计算loss
):
super().__init__()
self.config = base_model.config
self.num_padding_at_beginning = num_padding_at_beginning
# 定义最后一层输出,是将模型的最后一层通过一个linear层,输出一个标量值作为奖励;
if hasattr(self.config, "word_embed_proj_dim"):
# OPT系列模型用word_embed_proj_dim作为最后输出
self.v_head = nn.Linear(self.config.word_embed_proj_dim, 1, bias=False)
else:
# `gpt-neo(x)`模型是用`hidden_size`的`n_embd``
self.config.n_embd = self.config.hidden_size if hasattr(
self.config, "hidden_size") else self.config.n_embd
self.v_head = nn.Linear(self.config.n_embd, 1, bias=False)
self.rwtransformer = base_model
self.PAD_ID = tokenizer.pad_token_id
self.compute_fp32_loss = compute_fp32_loss
# checkpoint的梯度检测点
def gradient_checkpointing_enable(self):
self.rwtransformer.gradient_checkpointing_enable()
def gradient_checkpointing_disable(self):
self.rwtransformer.gradient_checkpointing_disable()
# 前向传播
def forward(self,
input_ids=None, # token id
past_key_values=None, # 控制kv_cache,第一次调用通常是None
attention_mask=None, # 掩码矩阵
position_ids=None, # 位置编码
head_mask=None, # 多头掩码,对多头机制中的某个/某几个头掩码(停止输出),
研究各头的作用,或降低资源消耗
inputs_embeds=None, # 输入特征矩阵,输入额外的信息
use_cache=False):
loss = None
if self.config.model_type == "llama":
kwargs = dict()
else:
kwargs = dict(head_mask=head_mask)
#调用base model
transformer_outputs = self.rwtransformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
**kwargs)
hidden_states = transformer_outputs[0] # size=bs*seq*hd
rewards = self.v_head(hidden_states).squeeze(-1) # size=bs*seq
chosen_mean_scores = []
rejected_mean_scores = []
# 拆分选择和排斥的数据结构,根据DataCollatorReward可以看到数据结构,batch是chosen和reject是拼接的
#batch["input_ids"] = torch.cat([f[0] for f in data] + [f[2] for f in data], dim=0)
#batch["attention_mask"] = torch.cat([f[1] for f in data] +[f[3] for f in data],dim=0)
assert len(input_ids.shape) == 2
bs = input_ids.shape[0] // 2
seq_len = input_ids.shape[1]
chosen_ids = input_ids[:bs] # bs x seq x 1
rejected_ids = input_ids[bs:]
chosen_rewards = rewards[:bs]
rejected_rewards = rewards[bs:]
# 计算pair loss
loss = 0.
for i in range(bs):
chosen_id = chosen_ids[i]
rejected_id = rejected_ids[i]
chosen_reward = chosen_rewards[i]
rejected_reward = rejected_rewards[i]
c_inds = (chosen_id == self.PAD_ID).nonzero() # 查找chosen_id中填充token的索引
# 找到第一个开始填充的位置索引
c_ind = c_inds[self.num_padding_at_beginning].item() if len(
c_inds) > self.num_padding_at_beginning else seq_len
# 查找chosen_id和rejected_id不同的索引,便于分析两个序列
check_divergence = (chosen_id != rejected_id).nonzero()
# 处理定位chosen和reject首次出现不同的和结尾的索引
if len(check_divergence) == 0: # chosen和reject完全一致
end_ind = rejected_reward.size(-1) # 序列长度
divergence_ind = end_ind - 1 # 表示末尾最后一个元素也是相同的元素
r_ind = c_ind
else:
# 确定reject的非填充开始索引
r_inds = (rejected_id == self.PAD_ID).nonzero()
r_ind = r_inds[self.num_padding_at_beginning].item(
) if len(r_inds) > self.num_padding_at_beginning else seq_len
end_ind = max(c_ind, r_ind) # 选择最大的作为结束索引
divergence_ind = check_divergence[0] # 选择第一个不同的位置作为开始索引
assert divergence_ind > 0
c_truncated_reward = chosen_reward[divergence_ind:end_ind] # chosen的截断奖励
r_truncated_reward = rejected_reward[divergence_ind:end_ind] # reject的截断奖励
# 保存最后一个token的位置的奖励
chosen_mean_scores.append(
chosen_reward[c_ind - 1]) #use the end score for reference
rejected_mean_scores.append(rejected_reward[r_ind - 1])
# 计算损失,计算chose奖励减去regect奖励差的对数sigmoid
if self.compute_fp32_loss:
c_truncated_reward = c_truncated_reward.float()
r_truncated_reward = r_truncated_reward.float()
loss += -torch.nn.functional.logsigmoid(c_truncated_reward -
r_truncated_reward).mean()
# 求平均和保存loss和奖励
loss = loss / bs
chosen_mean_scores = torch.stack(chosen_mean_scores)
rejected_mean_scores = torch.stack(rejected_mean_scores)
return {
"loss": loss,
"chosen_mean_scores": chosen_mean_scores,
"rejected_mean_scores": rejected_mean_scores,
}
# 计算单一序列的奖励
def forward_value(self,
input_ids=None,
attention_mask=None,
past_key_values=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
return_value_only=False,
prompt_length=0,
use_cache=False):
if self.config.model_type == "llama":
kwargs = dict()
else:
kwargs = dict(head_mask=head_mask)
transformer_outputs = self.rwtransformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
**kwargs)
hidden_states = transformer_outputs[0]
values = self.v_head(hidden_states).squeeze(-1)
if return_value_only:
return values
else:
assert prompt_length > 1,
bs = values.size(0)
seq_len = input_ids.shape[1]
chosen_end_scores = []
for i in range(bs):
input_id = input_ids[i]
value = values[i]
c_inds = (input_id[prompt_length:] == self.PAD_ID).nonzero()
c_ind = c_inds[0].item() + prompt_length if len(
c_inds) > 0 else seq_len
chosen_end_scores.append(value[c_ind - 1])
return {
"values": values,
"chosen_end_scores": torch.stack(chosen_end_scores),
}
model_utils.py:
-
def causal_lm_model_to_fp32_loss:构建causal——lm的前向传播和计算loss,并且loss一定是以fp32精度计算的;
-
def create_hf_model:加载并创建Hugging Face(HF)模型;
-
create_critic_model:创建奖励模型;
lora
对于资源不足的场景,可以引入 lora 的方式进行轻量级训练:
-
actor model 用 sft model 初始化,在 sft model 的模型基础上增加 lora 分支训练,如果 actor_model 的 lora 部分就不会参与训练。
-
此时 actor_model 等价于原始 sft model,如果 actor model 的主参数部分阴参数固定不变,右边 lora 部分参与训练,得到训练后新的 sft model。
-
critic model 用 rm model 初始化,在 rm model 基础上增加 lora 分支训练。
-
如果 critic_model 的 lora 部分不参与训练,这样 critic model 就可以当作 rm model 进行奖励计算,如果 critic model 的 lora 参与训练,那么,整个训练过程就在训练 critic model;
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇

面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)