AutoTimes:通过大型语言模型实现的自回归时间序列预测器
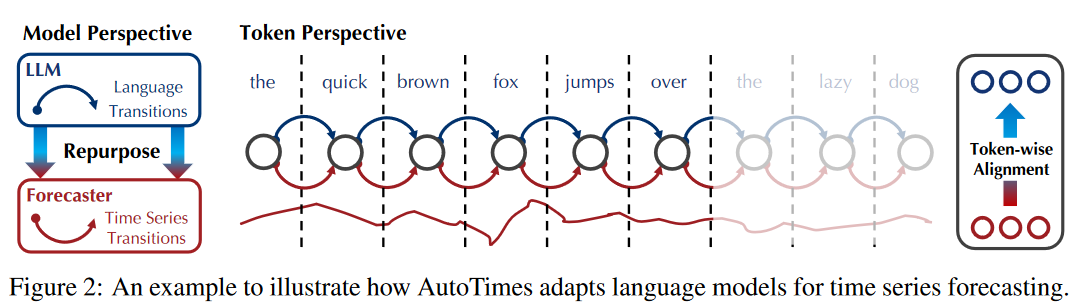
鉴于时间序列与自然语言具有相似的序列结构,越来越多的研究表明,利用大型语言模型(LLM)进行时间序列建模是可行的。如图 3 所示,现有主流的 LLM【6, 36】具备根据前序 token预测下一个 token 的能力,本文在 AutoTimes 中完全复用 LLM 这一特性,以一致的方式迭代生成任意长度的预测。为此,本文将时间序列 token 定义为单一变量上的连续非重叠片段,这被视为 LLM 预

文章信息

论文题目为《AutoTimes: Autoregressive Time Series Forecasters via Large Language Models》,发表于NeurIPS 2024。该工作由清华大学THUML团队提出,旨在探索大型语言模型在时间序列预测中的基础建模能力,并在现有 LLM4TS 研究的基础上进一步推进自回归框架与上下文学习的结合。

摘要

时间序列的基础模型尚未充分发展,其原因在于时间序列语料库的有限可用性以及对可扩展预训练的研究不足。鉴于时间序列与自然语言具有相似的序列结构,越来越多的研究表明,利用大型语言模型(LLM)进行时间序列建模是可行的。然而,LLM固有的自回归特性与仅使用解码器的架构尚未被充分考虑,导致未能充分发挥LLM的能力。
为充分激活大型语言模型在通用 token 转换和多步生成方面的能力,本文提出 AutoTimes:将 LLM 重新用于自回归时间序列预测器。该方法将时间序列投影到语言 token 的嵌入空间中,并以自回归方式生成任意长度的未来预测。AutoTimes 可兼容任何仅解码器结构的 LLM,因而具有灵活的回看窗口长度,并可扩展至更大的 LLM。
此外,该文章将时间序列表述为 prompt,实现超越固定回看窗口的预测上下文扩展,这被称为上下文内预测(in-context forecasting)。通过引入嵌入有时间戳的文本 token,AutoTimes 能够利用时间顺序信息,对多变量时间序列进行对齐。
在实验中,AutoTimes 仅使用 0.1% 的可训练参数,即可达到当前最优性能,并在训练/推理速度上相比先进的 LLM 时间序列预测器快 5 倍以上。

引言

时间序列预测在现实世界中具有极高的需求,广泛应用于气候、经济、能源、运营等领域。随着对通用预测模型的需求增长,即一个模型可适应不同长度的输入场景,辅助模态信息(如图像、文本等)在预测中的作用日益凸显。这推动了对时间序列基础模型(foundation models)的需求,这类模型具备多步预测、零样本泛化、上下文学习和多模态处理能力,从而能扩展时间序列预测的适用范围。
然而,时间序列基础模型的发展受到两个主要限制:一是缺乏大规模预训练数据集,二是可扩展架构的技术不确定性。相比之下,大型语言模型(LLMs)由于拥有大规模文本语料、预训练模型和成熟的适配技术,在近年取得了快速进展。值得注意的是,自然语言和时间序列在序列建模和 token 生成方式上有高度相似性,这为将 LLM 迁移用于时间序列预测提供了新机遇。
尽管已有一些 LLM for Time Series(LLM4TS)研究在预测基准上取得了显著突破,但 LLM 如何与时间序列模态真正对齐,仍不清晰。现有方法往往将时间序列切分为 token 后展平,再进行一次性预测(非自回归方法),这破坏了 LLM 原有的自回归结构(decoder-only),造成结构与生成方式的不一致。研究表明,LLM 的泛化能力大多来源于其 decoder-only 的自回归训练方式,因此,如果不维持这一特性,其潜能将无法充分发挥。而很多现有方法忽略了“自回归性”这一统计模型与 LLM 共同核心特征。因而,自回归式的 LLM4TS 方法尚属空白,这恰恰是实现多步预测和任意长度预测的关键。
基于上述反思,本文作者提出 AutoTimes,一个将 LLM 重新用于时间序列预测的框架,目标是复用 LLM 的自回归一致性与生成能力,以实现时间序列基础模型的构建。技术上,本文将时间序列片段独立嵌入语言模型的潜在空间中,遵循一致的训练目标:下一 token 的预测。为充分利用 LLM 原有的 token 转换机制并降低训练成本,本文冻结 LLM 主体,仅对时间序列的 token 嵌入与投影层进行训练,这部分参数仅占总参数的 0.1% 以内。最终的预测器采用类似 LLM 的自回归推理方式,不再受限于固定的回看/预测长度。进一步突破传统时间序列预测方法,本文提出 in-context forecasting(上下文内预测),如图 1 所示,时间序列可以通过相关上下文自行触发预测。本文还引入 LLM 嵌入时间戳 作为位置编码,来利用时间顺序信息并对多变量序列进行对齐。
本文的主要贡献如下:
-
本文修正现有非自回归 LLM4TS 方法的结构性不一致问题,继承了 LLM 的自回归特性,从而摆脱了对特定回看长度的依赖,实现具备时间感知的任意长度预测;
-
本文提出 AutoTimes,一种简单而高效的 LLM 适配方法,借助 LLM 内部 token 转换机制来外推时间序列。同时引入 上下文内预测,通过引导相关提示序列,重塑传统预测范式;
-
相比现有最先进方法,AutoTimes 在训练和推理时间上节省超过 80%,同时具备 零样本泛化能力、上下文预测能力,以及 由 LLM 赋能的扩展性行为。

方法论

本文提出的 AutoTimes 旨在将大型语言模型(LLMs)适配用于多变量时间序列预测。给定历史观测序列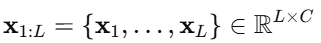 其中,L是时间步数,C是变量数量。本文的目标是预测未来F个时间步的值,即:
其中,L是时间步数,C是变量数量。本文的目标是预测未来F个时间步的值,即:
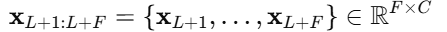
同时,采用文本形式的时间戳作为最常见的协变量,与时间点对齐。本文的任务是训练一个基于 LLM 的预测器f,能够处理不同的回看长度L并预测任意长度的未来值:
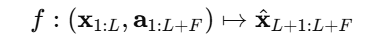
1.模态对齐
a) 时间序列 Token
为了使模型具备任意长度的时间序列预测能力,AutoTimes 将自回归 LLM 改造为时间序列预测器,如图 2 所示。为此,本文将时间序列 token 定义为单一变量上的连续非重叠片段,这被视为 LLM 预测器的通用 token,既能覆盖序列变化,又避免过长的自回归路径。
为了专注于建模时间变化,AutoTimes 独立预测每个变量。不同于通道独立假设(Channel Independence)那样仅隐式建模变量间关系,AutoTimes 将时间戳转化为位置编码,显式地对同时刻的多个变量进行对齐。因此,本文将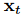 简化为某个变量在时刻t的值。设定每个变量的序列长度为NS,本文将其划分为N个长度为S的片段,第i个片段表示为:
简化为某个变量在时刻t的值。设定每个变量的序列长度为NS,本文将其划分为N个长度为S的片段,第i个片段表示为:
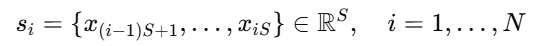
为了适配通用的 token 生成机制,本文冻结语言模型的所有参数,并构建时间序列 token 与语言 token 之间的一致性对齐机制。本文引入: 即将每段时间序列嵌入到语言模型的潜在空间中,其中D与LLM的维度一致。于是:
即将每段时间序列嵌入到语言模型的潜在空间中,其中D与LLM的维度一致。于是:
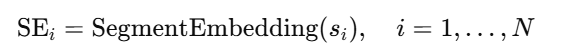
b)位置嵌入
时间戳作为表征时间顺序信息的重要协变量,过去常作为额外嵌入项广泛应用于深度预测模型中。然而,越来越多的研究选择舍弃时间戳嵌入,并发现模型性能不会明显下降,这说明时间戳未被正确编码。相反,文本形式的时间戳作为 prefix prompt 的一部分在 LLM4TS 方法中被证明是有效增强方式。
但这也带来问题:过长的上下文序列会使 LLM 无法专注于时间序列 token本身,导致前向推理缓慢。受到位置嵌入机制的启发(该机制用于引入 token 的相对或绝对位置信息),本方法采用LLM 嵌入的时间戳作为位置嵌入,以利用时间信息并对不同时刻的多变量 segment 进行对齐。
在技术实现上,本文根据图 3 所示的模板,为每段时间序列构建起始与结束的时间戳。实验发现,即便使用简单模板(无需复杂设计),也能稳定提升预测性能(可见原文附录),帮助 LLM 理解日期并实现变量间的对齐(基于通道独立假设)。
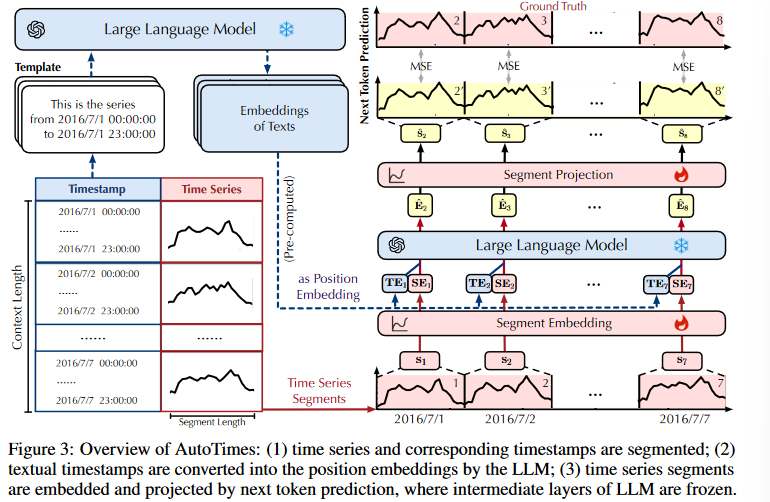
由于所有之前的语言 token 都可以被 <EOS> 感知,本文将 <EOS> 的嵌入向量作为时间戳的位置嵌入,记为: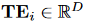
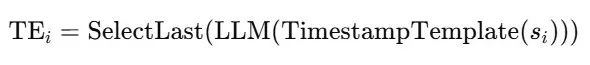
特别地,这一时间嵌入 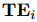 是由 LLM 预先计算得到的,因此在训练阶段无需重复计算语言 token 的前向传播。由于 LLM 的潜在空间同时可用于时间序列与语言 token,因此本文可以将时间嵌入与 segment 嵌入合并,无需增加上下文长度。最终,每个时间序列 token 的嵌入表示为:
是由 LLM 预先计算得到的,因此在训练阶段无需重复计算语言 token 的前向传播。由于 LLM 的潜在空间同时可用于时间序列与语言 token,因此本文可以将时间嵌入与 segment 嵌入合并,无需增加上下文长度。最终,每个时间序列 token 的嵌入表示为:
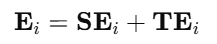
2.预测下一 个Token
如图 3 所示,现有主流的 LLM【6, 36】具备根据前序 token预测下一个 token 的能力,本文在 AutoTimes 中完全复用 LLM 这一特性,以一致的方式迭代生成任意长度的预测。假设输入时间序列长度为 NS,本文将其分割为 N个片段并嵌入为 token 向量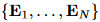 。训练目标是独立生成下一组 token:
。训练目标是独立生成下一组 token:
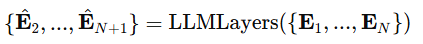
本文采用投影函数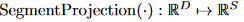 将嵌入向量还原为片段表示:
将嵌入向量还原为片段表示: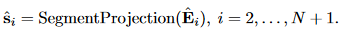 最终,所有预测片段通过 token-level 的真实标签进行监督,优化嵌入与投影层的参数,损失函数为:
最终,所有预测片段通过 token-level 的真实标签进行监督,优化嵌入与投影层的参数,损失函数为:
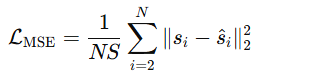
值得注意的是,NS(上下文长度)在训练时设定,表示模型所能接受的最大输入长度。因此,训练出的预测器能够处理不同长度的输入,类似于 LLM(详见原文附录 D.4)。此外,AutoTimes 还能通过多步迭代方式进行任意长度的预测,在减少误差累计方面优于现有方法(详见原文第 4.1 节),因为自回归的 LLM 本身就非常擅长多步生成:
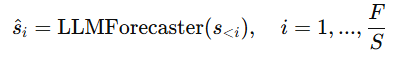
与传统方法需要分别训练多个模型以适应不同的回看/预测长度不同,AutoTimes 使用一个模型就可以统一应对所有情况。令人惊喜的是,由于其保持自回归一致性,它还能继承 LLM 在泛化能力和可扩展性方面的优势(详见原文第 4.2 和 4.4 节)。
3.上下文内预测
大型语言模型可在无需梯度更新的前提下,基于下游任务的示例直接生成期望输出,这被称为上下文学习(in-context learning)能力。这些任务示例通常为配对的“问题-答案”对。形式上,上下文表示为:
对于时间序列预测任务,本文提出将这种“问题-答案”对表示为“历史-预测窗口”对,其本质上是来自历史观测中的连续时间点。因此,本文将目标数据集中的时间序列作为 prompt 使用,以扩展预测上下文至超过连续历史序列的范围。本文将扩展后的上下文记为C,表示如下:
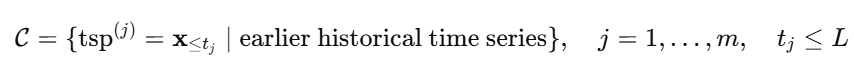
在训练阶段,本文首先使用源数据集训练一个 LLM 预测器,并从目标数据集中选择若干时间序列 prompt,通过统一策略加入模型上下文。
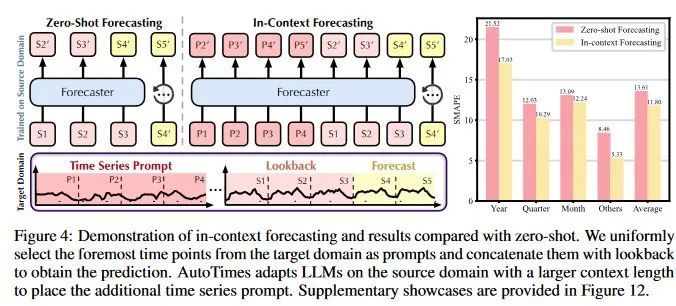
在推理时,确保所有 prompt 出现在预测窗口之前,以防信息泄露。如图 4 所示,本文将时间序列 prompt 与回看序列拼接输入,定义为 上下文内预测(in-context forecasting):
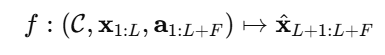

实验

1.泛化能力
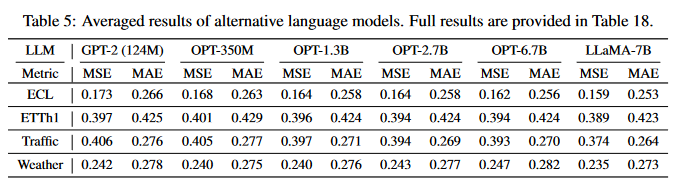
先前的 LLM4TS 方法主要集中在特定的语言模型上进行适配。而本文证明了 AutoTimes 对任意 decoder-only 的 LLM 都具有良好的兼容性。本文基于当前主流的 LLM,包括 GPT-2、OPT和 LLaMA,广泛训练了 AutoTimes 模型作为时间序列预测器,并将其预测性能汇总在表 5 中,突出显示了 AutoTimes 的良好泛化能力。
2.拓展能力
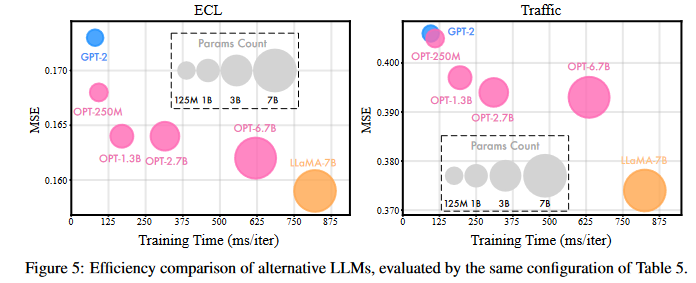
可扩展性是从小模型到大模型演化中关键的能力特征。本文通过分析表 5 的结果发现,随着 LLM 参数规模的提升,预测器的性能也趋于提升。但与此同时,LLM 的扩展也带来了性能与代价之间的权衡:更大的模型意味着更好的预测效果,但也增加了训练成本。为了全面评估,本文从以下三个维度对每个适配的预测器进行分析:预测性能(MSE)、训练时间(ms/iter)、模型参数数量。如下图所示(图 5),本文以 ECL 和 Traffic 数据集为例,展示不同模型在性能与效率上的分布情况。

实验

本文旨在构建用于时间序列预测的基础模型。本文通过转移大型语言模型(LLMs)在通用建模和多步生成方面的能力,将其作为自回归预测器进行再利用。与以往方法不同,本文观察到当前主流的非自回归式 LLM4TS 方法可能与 LLM 的 decoder-only 架构不兼容,导致其能力未被充分发挥。在实验中,所提出的方法在保持卓越模型效率的同时,实现了当前最先进的预测性能。进一步分析表明,该预测器有效继承了 LLM 的诸多高级能力,包括零样本泛化能力(zero-shot)、上下文内预测(in-context forecasting),以及对时间序列和时间戳的双重利用能力。未来,本文将进一步引入先进的低秩适配技术,并结合不断发展的语言模型主干结构,持续提升模型性能与适应性。

Attention

欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)