OpenELM:苹果开源的高效语言模型及训练推理框架
未来,随着更多的研究者参与改进和分析,OpenELM有望在各类自然语言任务上树立新的标杆,为LLM的发展注入新的活力。有别于此前只提供模型权重和推理代码,或在私有数据集上预训练的做法,苹果的开源内容包括了在公开数据集上进行训练和评估的完整框架,涵盖训练日志、多个检查点和预训练配置。与现有LLM在每层采用相同配置、均匀分配参数不同,OpenELM根据逐层缩放策略,让每层transformer的配置(
苹果公司最近开源了一个名为OpenELM的大型语言模型(LLM)家族,旨在通过公开模型架构、训练方法和数据集,提高LLM研究的可重复性和透明度。这不仅有助于学界验证结果、研究数据和模型偏差,也为探索潜在风险提供了机会。
OpenELM采用了一种逐层缩放(layer-wise scaling)策略,在transformer模型的每一层中高效分配参数,从而在给定参数预算下实现更高的精度。例如,在约10亿参数规模下,OpenELM的精度比最近开源的OLMo高出2.36%,而训练token数量只有后者的一半。
有别于此前只提供模型权重和推理代码,或在私有数据集上预训练的做法,苹果的开源内容包括了在公开数据集上进行训练和评估的完整框架,涵盖训练日志、多个检查点和预训练配置。他们还发布了将模型转换为MLX库的代码,方便在苹果设备上进行推理和微调。这种全面的开源有望赋能和加强开放研究社区,为未来的开放研究铺平道路。
OpenELM模型架构
OpenELM采用了decoder-only的transformer架构。参考SOTA的LLM,它在设计中融入了以下特点:
1. 所有全连接层(线性层)不使用可学习的偏置参数
2. 使用RMSNorm进行预规范化,使用RoPE编码位置信息
3. 用分组查询注意力(GQA)取代多头注意力(MHA)
4. 用SwiGLU FFN取代前馈网络(FFN)
5. 使用flash attention计算点积注意力
6. 沿用LLama的分词器
与现有LLM在每层采用相同配置、均匀分配参数不同,OpenELM根据逐层缩放策略,让每层transformer的配置(如注意力头数、前馈维度)各不相同,从而在整个模型中实现参数的非均匀分配。这种做法让OpenELM能在相同参数量下,实现更高的精度。
训练数据和方法
OpenELM在约1.8万亿token的公开数据集上进行了预训练,包括RefinedWeb、去重的PILE、RedPajama和Dolma的子集。与之前使用预分词数据的方法不同,OpenELM采用了即时过滤和分词。这大大简化了使用不同分词器进行实验的流程。
训练采用AdamW优化器,使用余弦退火学习率调度,训练35万步。他们训练了270M、450M、1.1B和3B四个不同规模的变体,对于某些模型还启用了FSDP和activation checkpointing技术。
评估结果
研究者在三个评估框架下测试了OpenELM:标准zero-shot任务、OpenLLM排行榜任务和LLM360排行榜任务。结果显示,不论在推理、知识理解还是识别错误信息和偏见方面,OpenELM都优于现有的开源LLM。尤其是在规模相当的情况下,OpenELM在精度上显著领先OLMo,且只用了一半的训练数据。 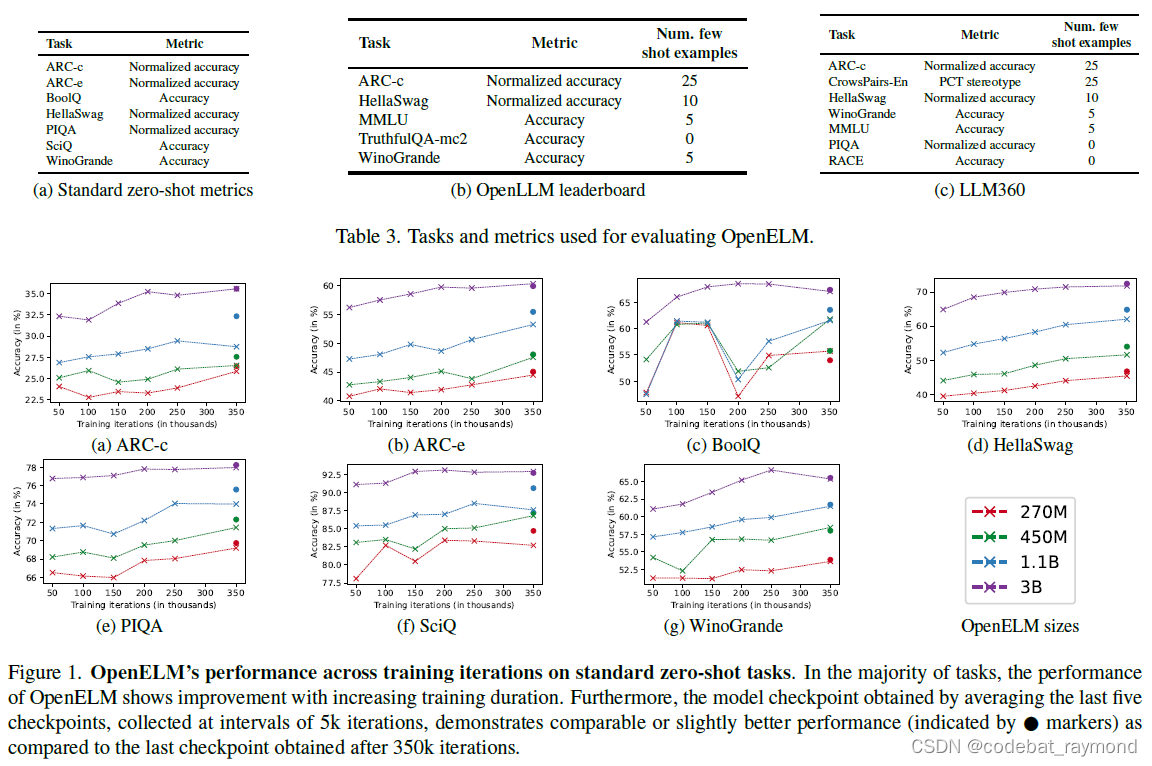
进一步的指令微调实验表明,在6万个指令样本上微调,可使OpenELM在各种任务上的平均精度提高1-2个百分点。此外,LoRA和DoRA等参数高效微调方法也被证明可用于OpenELM,在维持模型大小不变的情况下显著提升下游任务性能。
模型开源
OpenELM的源码、预训练权重和训练配方已在GitHub上开源。模型本身也已上传到HuggingFace,方便研究者使用。值得一提的是,苹果还开源了将模型转换为MLX的代码,MLX是一个在苹果硅芯片上进行高效机器学习的库。这为在苹果设备上部署OpenELM扫清了障碍。
结论
OpenELM的发布代表了苹果在开放研究道路上又迈出的一大步。逐层缩放策略和全面的开源内容是其两大亮点。尽管目前的推理速度还有待优化,但OpenELM在精度和数据效率上已经展现了巨大的潜力。未来,随着更多的研究者参与改进和分析,OpenELM有望在各类自然语言任务上树立新的标杆,为LLM的发展注入新的活力。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)