多导睡眠五大PSG数据集统一格式化处理|HMC
本文介绍了HMC多导睡眠图(PSG)数据集的预处理方法。该数据集包含151份整夜睡眠记录(15.7GB),含EEG、EOG、EMG和ECG信号及睡眠分期标注。预处理步骤包括:1)导入MNE等工具库;2)筛选匹配的PSG和标注文件;3)定义睡眠阶段标签映射;4)信号处理(重采样、滤波);5)30秒分段和事件标注;6)数据标准化;7)序列化保存为20段/序列的npy格式。代码实现了从原始EDF文件到标
完整五个数据集处理请见:
https://blog.csdn.net/m0_70335361/article/details/151406787?fromshare=blogdetail&sharetype=blogdetail&sharerId=151406787&sharerefer=PC&sharesource=m0_70335361&sharefrom=from_link![]() https://blog.csdn.net/m0_70335361/article/details/151406787?fromshare=blogdetail&sharetype=blogdetail&sharerId=151406787&sharerefer=PC&sharesource=m0_70335361&sharefrom=from_link本文代码已公开至:XingXingYuoos/PSG_data_prepare
https://blog.csdn.net/m0_70335361/article/details/151406787?fromshare=blogdetail&sharetype=blogdetail&sharerId=151406787&sharerefer=PC&sharesource=m0_70335361&sharefrom=from_link本文代码已公开至:XingXingYuoos/PSG_data_prepare
一、背景介绍
睡眠医学研究中多导睡眠图(PSG)数据集的异构性导致跨研究分析困难
HMC数据库作为公开基准数据集的价值
统一格式化处理对提高数据复用性和算法泛化能力的作用
二、数据集介绍
HMC数据集是2018 年在 Haaglanden Medisch Centrum(HMC,荷兰)睡眠中心收集的 151 份整夜多导睡眠图 (PSG) 睡眠记录(85 名男性,66 名女性,平均年龄 53.9 ± 15.4 岁)。
该数据集包含脑电图 (EEG)、眼电图 (EOG)、下巴肌电图 (EMG) 和心电图 (ECG) 活动,以及与睡眠模式评分相对应的事件注释(催眠图)由 HMC 的睡眠技术人员执行。
官网下载的所有文件如下,总共15.7 GB大小:
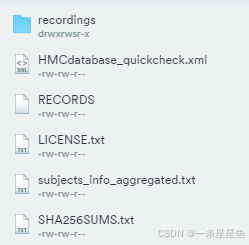
夜间录音由序列号 SNXXX 标识(例如 SN001 标识录音 001)。每个录音使用以下表示法提供三个不同的文件:
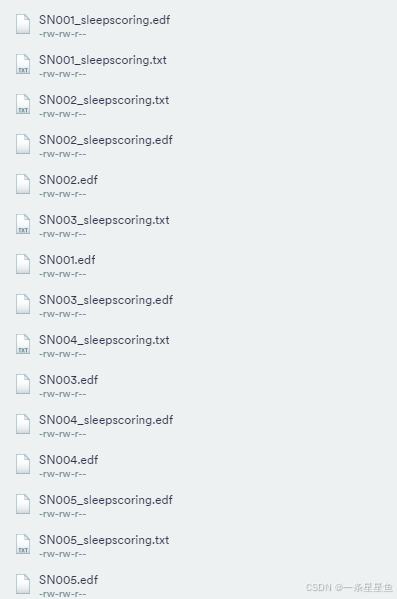
- SNXXX.edf:包含 EDF 格式的 PSG 信号(例如如上所述的 EEG、EMG、EOG 和 ECG 推导)
- SNXXX_sleepscoring.edf:包含相应的催眠图注释和 EDF+ 格式的熄灯/开灯标记
- SNXXX_sleepscoring.txt:包含相应的催眠图注释和熄灯/亮灯标记*,采用逗号分隔的文本文件格式
具体文件如下:
标签txt文件里面的内容如下:
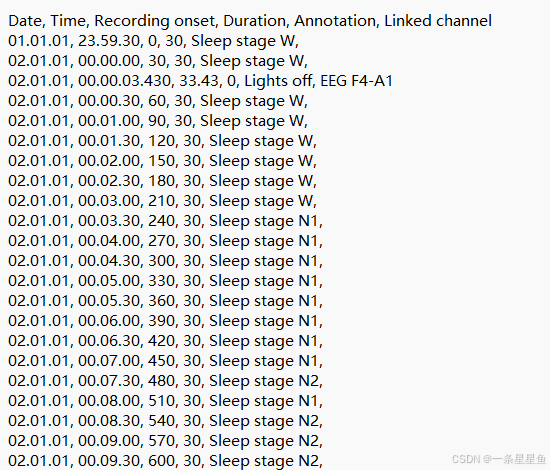
前面是时间点标记,后面是分期标签
三、数据预处理
在前面了解数据集格式之后,下面可以开始进行预处理了
step1:导入依赖库
from mne.io import concatenate_raws, read_raw_edf
import matplotlib.pyplot as plt
import mne
import os
import numpy as np
from tqdm import tqdm
from sklearn.preprocessing import StandardScaler
from pathlib import Path
step2:路径配置
dir_path = "/data/datasets/haaglanden-medisch-centrum-sleep-staging-database-1.1/recordings/"
seq_dir = "/data/datasets/GSS_datasets/HMC/seq/"
label_dir = "/data/datasets/GSS_datasets/HMC/labels/"
step3:筛选PSG和标签文件
psg_f_names = []
label_f_names = []
for f_name in f_names:
if 'sleepscoring.edf' in f_name:
label_f_names.append(f_name)
elif '.edf' in f_name:
psg_f_names.append(f_name)
psg_f_names.sort()
label_f_names.sort()
psg_label_f_pairs = []
for psg_f_name, label_f_name in zip(psg_f_names, label_f_names):
if psg_f_name[:5] == label_f_name[:5]:
psg_label_f_pairs.append((psg_f_name, label_f_name))
print(psg_label_f_pairs)
step4:定义睡眠阶段标签映射
label2id = {'Sleep stage W': 0,
'Sleep stage N1': 1,
'Sleep stage N2': 2,
'Sleep stage N3': 3,
'Sleep stage R': 4,
'Lights off@@EEG F4-A1': 0}
print(label2id)
step5:最核心的一步,把原始数据和标签处理成我们想要的格式
num_seqs = 0
num_labels = 0
signal_name = ['EEG F4-M1', 'EOG E1-M2']
for psg_f_name, label_f_name in tqdm(psg_label_f_pairs[:151]):
epochs_list = []
labels_list = []
raw = read_raw_edf(os.path.join(dir_path, psg_f_name), preload=True)
print(raw.info)
print(raw.ch_names)
raw.pick_channels(signal_name)
raw.resample(sfreq=100)
raw.filter(0.3, 35, fir_design='firwin')
annotation = mne.read_annotations(os.path.join(dir_path, label_f_name))
raw.set_annotations(annotation, emit_warning=False)
events_train, event_id = mne.events_from_annotations(
raw, chunk_duration=30.)
print(event_id)
key_list = []
for key in event_id.keys():
if 'Light' in key:
key_list.append(key)
for key in key_list:
event_id.pop(key)
print(event_id)
step6:数据分段与预处理
tmax = 30. - 1. / raw.info['sfreq']
epochs_train = mne.Epochs(raw=raw, events=events_train,
event_id=event_id, tmin=0., tmax=tmax, baseline=None)
print(epochs_train.event_id)
labels = []
for epoch_annotation in epochs_train.get_annotations_per_epoch():
labels.append(epoch_annotation[0][2])
length = len(labels)
epochs = epochs_train[:]
labels_ = labels[:]
print(epochs)
print(labels_)
step7:数据标准化与维度变换
for epoch in epochs:
epochs_list.append(epoch)
for label in labels_:
labels_list.append(label2id[label])
index = len(epochs_list)
while index % 20 != 0:
index -= 1
epochs_list = epochs_list[:index]
labels_list = labels_list[:index]
print(len(epochs_list), len(labels_list))
epochs_array_ = np.array(epochs_list)
labels_array_ = np.array(labels_list)
print(epochs_array_.shape, labels_array_.shape)
epochs_array_ = epochs_array_.transpose(0, 2, 1)
epochs_array_ = epochs_array_.reshape(-1, 2)
std = StandardScaler()
epochs_array_ = std.fit_transform(epochs_array_)
print(epochs_array_.shape)
epochs_array_ = epochs_array_.reshape(-1, 3000, 2)
epochs_array_ = epochs_array_.transpose(0, 2, 1)
print(epochs_array_.shape)
step8:序列化保存数据
epochs_seq = epochs_array_.reshape(-1, 20, 2, 3000)
labels_seq = labels_array_.reshape(-1, 20)
print(epochs_seq.shape, labels_seq.shape)
print(epochs_seq.dtype, labels_seq.dtype)
if not os.path.isdir(f'{seq_dir}/{psg_f_name[:5]}'):
os.makedirs(f'{seq_dir}/{psg_f_name[:5]}')
for seq in epochs_seq:
seq_name = f'{seq_dir}/{psg_f_name[:5]}/{psg_f_name[:5]}-{str(num_seqs)}.npy'
with open(seq_name, 'wb') as f:
np.save(f, seq)
num_seqs += 1
if not os.path.isdir(f'{label_dir}/{label_f_name[:5]}'):
os.makedirs(f'{label_dir}/{label_f_name[:5]}')
for label in labels_seq:
label_name = f'{label_dir}/{label_f_name[:5]}/{label_f_name[:5]}-{str(num_labels)}.npy'
with open(label_name, 'wb') as f:
np.save(f, label)
num_labels += 1
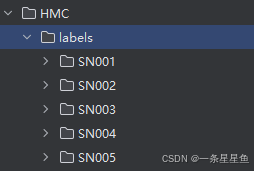
确认代码无误后,运行:

最后生成结果
本文代码已公开至:XingXingYuoos/PSG_data_prepare

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)