个人从零开始打造大语言模型?攻略都在这里了!
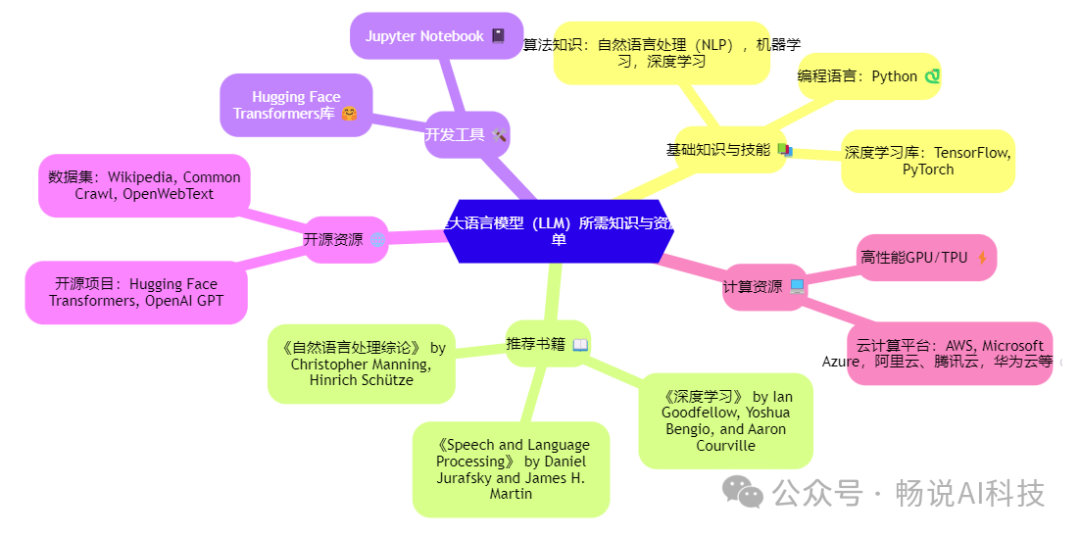
首先,给出一个学习清单:构建大语言模型(LLM)所需知识与资源清单1.基础知识与技能编程语言:Python深度学习库:TensorFlow, PyTorch算法知识:自然语言处理(NLP),机器学习,深度学习2.推荐书籍《深度学习》 by Ian Goodfellow, Yoshua Bengio, and Aaron Courville《自然语言处理综论》 by Christopher Mann
首先,给出一个学习清单:
构建大语言模型(LLM)所需知识与资源清单
1.基础知识与技能
-
编程语言:Python
-
深度学习库:TensorFlow, PyTorch
-
算法知识:自然语言处理(NLP),机器学习,深度学习
2.推荐书籍
-
《深度学习》 by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
-
《Speech and Language Processing》 by Daniel Jurafsky and James H. Martin
-
《自然语言处理综论》 by Christopher Manning, Hinrich Schütze
3.开发工具
-
Jupyter Notebook
-
Hugging Face Transformers库
4.开源资源
-
开源项目:Hugging Face Transformers, OpenAI GPT
-
数据集:Wikipedia, Common Crawl, OpenWebText
5.计算资源
-
高性能GPU/TPU
-
云计算平台:AWS, Microsoft Azure,阿里云、腾讯云,华为云等
有了清单后,我们就可以来逐步攻克这个难关了。
我们要梳理一下构建一个大语言模型的整个流程。
从零开始构建大语言模型(LLM)的难度与要求
构建大语言模型(LLM)对于没有团队支持的个人来说是一个巨大的挑战,需要深厚的技术知识、丰富的计算资源和大量的数据。以下是详细步骤和要求,通过一个人的独立流程,让大家对整个过程有清晰的认识。
1. 编程与算法
掌握Python和深度学习库:
-
例子:学习并熟练使用Python的TensorFlow和PyTorch库。
-
具体步骤:通过在线课程和项目练习,掌握Python编程基础;然后深入学习TensorFlow和PyTorch的基本概念和应用。
理解自然语言处理(NLP)和深度学习算法:
-
例子:理解并实现Transformer架构。
-
具体步骤:阅读并理解论文《Attention is All You Need》,然后尝试用TensorFlow实现一个简单的Transformer模型。
2. 模型结构
理解Transformer模型:
-
例子:从头实现一个简化版的Transformer模型。
-
具体步骤:在理解论文的基础上,先实现一个简单的Encoder-Decoder模型,然后逐步增加复杂性。
进行模型调优和性能优化:
-
例子:通过调整超参数提高模型性能。
-
具体步骤:尝试不同的学习率、批量大小等参数,使用验证集评估模型性能,找到最佳配置。
3. 计算资源
需要高性能GPU/TPU支持:
-
例子:使用Google Colab进行初步实验。
-
具体步骤:注册Google Colab,配置环境,使用免费提供的GPU资源进行小规模实验。
考虑使用云计算资源:
-
例子:租用AWS的EC2实例进行大规模训练。
-
具体步骤:注册AWS账号,选择适合的EC2实例,配置深度学习环境,上传数据集并开始训练。
4. 数据准备
收集大量高质量文本数据:
-
例子:使用公开的Wikipedia数据集。
-
具体步骤:从Wikipedia下载数据集,使用Python进行数据清洗和预处理。
进行数据清洗和预处理:
-
例子:编写脚本去除无关内容和格式化文本。
-
具体步骤:编写Python脚本,去除HTML标签、特殊字符等,整理成训练所需的格式。
5. 小规模实验
从小模型开始实验:
-
例子:训练一个小型GPT模型。
-
具体步骤:在Google Colab上实现并训练一个小型GPT模型,使用小规模数据集进行测试和调整。
逐步扩展模型规模和复杂性:
-
例子:逐步增加模型层数和参数规模。
-
具体步骤:从小规模模型开始,逐步增加Transformer层数和隐藏层大小,观察性能变化。
6. 学习与实践
学习NLP和深度学习基础知识:
-
例子:学习经典教材《Speech and Language Processing》和《Deep Learning》。
-
具体步骤:系统学习相关教材,完成书中的练习和项目,打好理论基础。
参与开源项目积累实践经验:
-
例子:参与Hugging Face Transformers库的开发。
-
具体步骤:在GitHub上查找并参与开源项目,解决实际问题,积累实战经验。
7. 工具和资源
使用开发工具如Jupyter Notebook和Hugging Face Transformers库:
-
例子:在Jupyter Notebook中实现一个文本生成模型。
-
具体步骤:安装Jupyter Notebook,使用Hugging Face库加载预训练模型,进行文本生成实验。
利用开源数据集进行模型训练:
-
例子:使用OpenAI提供的预训练数据集。
-
具体步骤:下载数据集,进行预处理,训练模型,评估结果并进行优化。
8. 社区参与
参与NLP社区,学习前沿技术:
-
例子:加入AI和NLP论坛,参加相关讨论和研讨会。
-
具体步骤:注册并活跃于Reddit的r/MachineLearning和AI Alignment Forum,参与讨论并分享自己的项目。
参加研讨会和培训:
-
例子:参加ACL、EMNLP等顶级会议。
-
具体步骤:关注会议官网,提交论文或报名参会,参与技术交流和学习。
写在最后
从零开始构建大语言模型需要强大的技术能力、丰富的计算资源和持续的学习与实践。
通过从小规模实验和现有开源资源入手,逐步积累经验,并积极参与NLP社区和相关项目,可以逐步实现构建大语言模型的目标。
通过上述具体步骤和案例,可以更清晰地了解整个过程和所需的积累。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署
一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)