人工智能实验六(决策树)
ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。可视化的决策树:使用matplotlib和sklearn.tree.plot_tree函数生成的图形,展示了决策树的结构,包括节点、分支和叶节点。可视化的决策树:使用matplotlib和skle
- 实验环境
使用python编程实现,并在Mindspore框架下实现。
- 实验内容
题目: 某连锁餐饮企业想了解周末和非周末对销量是否有很大影响,以及天气好坏、是否有促销活动对销量的影响,从而公司的辅助决策。现有单个门店的历史数据。请按要求完成实验。建议使用python 编程实现,并在Mindspore框架下实现。
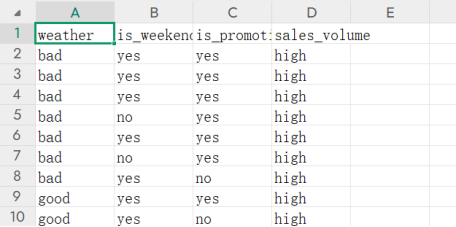
数据集: 文件ex3data.xls 为该实验的数据集,第1-5 列分别表示序号、天气好坏、是否周末、是否有促销和销量高低。
实验要求: 选择ID3、C4.5、CART 三种常见决策树算法中的一种建立决策树模型,并画出决策树。
ex3data.xls数据集:(只截取了一部分)
一、ID3:
- 原理:
D3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
①对当前样本集合,计算所有属性的信息增益;
②选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集;
③若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。
- 程序运行结果图:
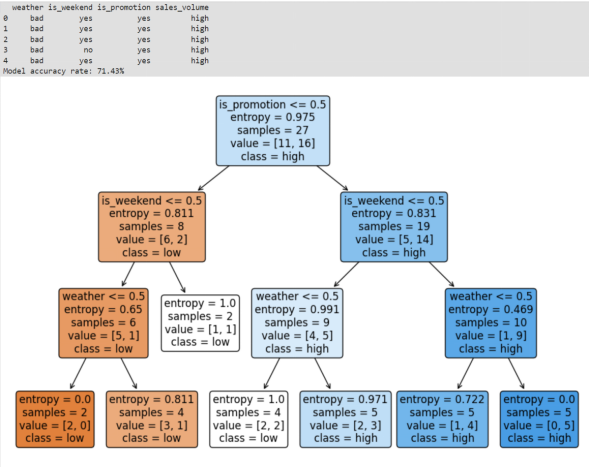
- 数据的前几行:通过print(data.head())输出,用于检查数据是否正确加载和理解数据格式。
- 模型的准确率:通过计算accuracy_score(y_test, y_pred)并打印,显示模型在测试集上的准确率,以百分比形式表示。
- 可视化的决策树:使用matplotlib和sklearn.tree.plot_tree函数生成的图形,展示了决策树的结构,包括节点、分支和叶节点。
3.源码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import sklearn
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取数据
data = pd.read_csv('ex3data.csv')
# 显示数据的前几行,检查数据格式
print(data.head())
# 数据预处理: 将文本数据转换为数值
# 将'weather', 'yesno周末', 'yesno有促销' 和 '销量' 的类别数据转换为数值
data['weather'] = data['weather'].apply(lambda x: 1 if x == 'good' else 0)
data['is_weekend'] = data['is_weekend'].apply(lambda x: 1 if x == 'yes' else 0)
data['is_promotion'] = data['is_promotion'].apply(lambda x: 1 if x == 'yes' else 0)
data['sales_volume'] = data['sales_volume'].apply(lambda x: 1 if x == 'high' else 0)
# 提取特征和标签
X = data[['weather', 'is_weekend', 'is_promotion']] # 特征
y = data['sales_volume'] # 标签
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用DecisionTreeClassifier来训练ID3模型
model = DecisionTreeClassifier(criterion='entropy', random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Model accuracy rate: {accuracy * 100:.2f}%')
# 可视化决策树
plt.figure(figsize=(12, 8))
tree.plot_tree(model, feature_names=X.columns, class_names=['low', 'high'], filled=True, rounded=True, fontsize=12)
plt.show()
- 代码思路及解释:
- 数据读取:使用pandas库的read_csv函数读取CSV文件中的数据。
- 数据预处理:将文本标签转换为数值,以便机器学习模型可以处理。这里使用apply方法和lambda函数将分类特征(如天气、是否周末、是否有促销)转换为数值特征。
- 特征和标签提取:从数据集中提取特征(X)和标签(y)。特征是用于训练模型的输入变量,而标签是我们想要预测的目标变量。
- 数据集划分:使用train_test_split函数将数据集分为训练集和测试集。通常,一部分数据用于训练模型,另一部分用于评估模型的性能。
- 模型训练:创建DecisionTreeClassifier实例,并设置criterion='entropy'参数来使用信息熵作为节点分裂的标准,然后,使用训练集数据调用fit方法来训练模型。
- 模型预测:使用训练好的模型对测试集进行预测,将预测结果存储在y_pred变量中。
- 性能评估:计算模型在测试集上的准确率,这是通过比较模型预测的结果和实际结果来完成的。
- 结果可视化:使用tree.plot_tree函数可视化决策树,这有助于理解模型是如何做出预测的。通过图形化展示,我们可以直观地看到每个特征是如何影响决策过程的。
二、C4.5:
- 原理:C4.5算法改进了信息增益,它选用信息增益比来选择最优特征。
特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的熵HA(D)之比,即:
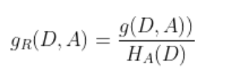
其中:
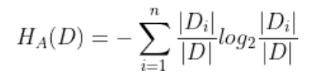
n是特征A取值的个数。其他部分与ID3算法完全相同。
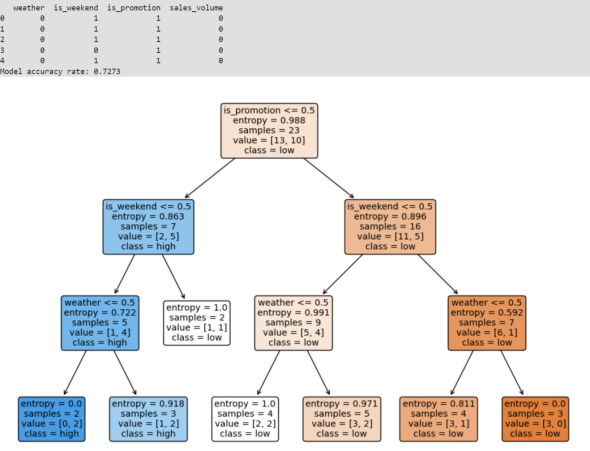
- 程序运行结果图:
- 数据转换后的情况:通过print(data.head())输出数据的前五行,以检查数据预处理后的情况。
- 模型的准确率:通过clf.score(X_test, y_test)计算模型在测试集上的准确率,并打印出来,显示模型的性能。
- 可视化的决策树:使用matplotlib和sklearn.tree.plot_tree函数生成的图形,展示了决策树的结构,包括节点、分支和叶节点。
3.源码:
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn import tree
# 读取数据
data = pd.read_csv("ex3data.csv")
# 数据预处理:将类别特征转换为数值型
le = LabelEncoder()
# 编码天气(weather)、周末(is_weekend)、促销(is_promotion)为数值
data['weather'] = le.fit_transform(data['weather']) # bad -> 0, good -> 1
data['is_weekend'] = le.fit_transform(data['is_weekend']) # no -> 0, yes -> 1
data['is_promotion'] = le.fit_transform(data['is_promotion']) # no -> 0, yes -> 1
data['sales_volume'] = le.fit_transform(data['sales_volume']) # low -> 0, high -> 1
# 查看数据转换后的情况
print(data.head())
# 特征和标签分开
X = data[['weather', 'is_weekend', 'is_promotion']]
y = data['sales_volume']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用sklearn的决策树分类器
clf = DecisionTreeClassifier(criterion='entropy') # 选择基于熵的划分
clf.fit(X_train, y_train)
# 评估模型
accuracy = clf.score(X_test, y_test)
print(f"Model accuracy rate: {accuracy:.4f}")
# 可视化决策树
plt.figure(figsize=(12, 8))
tree.plot_tree(clf, filled=True, feature_names=X.columns, class_names=['low', 'high'], rounded=True)
plt.show()- 代码思路及解释:
- 数据读取:使用pandas库的read_csv函数读取CSV文件中的数据。
- 数据预处理:使用LabelEncoder将分类特征(如天气、是否周末、是否有促销)转换为数值特征。这是因为机器学习模型无法直接处理文本数据。
- 特征和标签提取:从数据集中提取特征(X)和标签(y)。特征是用于训练模型的输入变量,而标签是我们想要预测的目标变量。
- 数据集划分:使用train_test_split函数将数据集分为训练集和测试集,其中30%的数据用作测试集,70%的数据用作训练集。random_state参数确保每次分割都是可重复的。
- 模型训练:创建DecisionTreeClassifier实例,并设置criterion='entropy'参数来使用信息熵作为节点分裂的标准,这与ID3算法的决策标准相似。然后,使用训练集数据调用fit方法来训练模型。
- 模型评估:使用clf.score方法计算模型在测试集上的准确率,这是通过比较模型预测的结果和实际结果来完成的。
- 结果可视化:使用tree.plot_tree函数可视化决策树,这有助于理解模型是如何做出预测的。通过图形化展示,我们可以直观地看到每个特征是如何影响决策过程的。
三、CART:
- 原理:CART是分类与回归树的简称,最终结果是二叉树,可以用于分类,也可以用于回归问题。分类树的输出是样本的类别, 回归树的输出是一个实数。自上而下从根开始建立节点,在每个节点处要选择一个最好的属性来分裂,使得子节点中的训练集尽量的纯。分类问题,可以选择GINI作为纯度指标;回归问题,可以使用最小二乘偏差(LSD)或最小绝对偏差(LAD)。
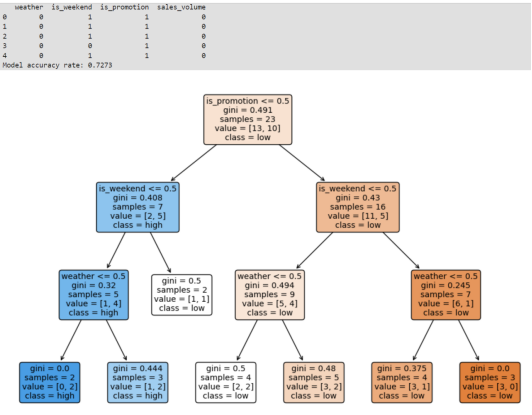
- 程序运行结果图:
- 数据转换后的情况:程序首先打印出数据预处理后的前五行,以便检查数据是否正确转换为数值型。
- 模型的准确率:程序计算并打印出模型在测试集上的准确率。准确率是一个介于0和1之间的值,表示模型正确预测的比例。
- 可视化的决策树:程序使用matplotlib库生成一个图形,展示训练好的决策树的结构。这个图形将显示:每个节点的决策规则。节点的类别(用不同颜色表示)。节点的基尼不纯度或信息增益。每个叶节点的类别分布。
3.源码:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn import tree
# 1. 读取数据并进行预处理
data = pd.read_csv("ex3data.csv")
# 数据预处理:将类别特征转换为数值型
le = LabelEncoder()
data['weather'] = le.fit_transform(data['weather']) # bad -> 0, good -> 1
data['is_weekend'] = le.fit_transform(data['is_weekend']) # no -> 0, yes -> 1
data['is_promotion'] = le.fit_transform(data['is_promotion']) # no -> 0, yes -> 1
data['sales_volume'] = le.fit_transform(data['sales_volume']) # low -> 0, high -> 1
# 查看数据转换后的情况
print(data.head())
# 2. 分离特征和目标变量
X = data[['weather', 'is_weekend', 'is_promotion']]
y = data['sales_volume']
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 4. 使用CART决策树构建模型
clf = DecisionTreeClassifier(criterion='gini') # 默认使用基尼不纯度
clf.fit(X_train, y_train)
# 5. 评估模型准确率
accuracy = clf.score(X_test, y_test)
print(f"Model accuracy rate: {accuracy:.4f}")
# 6. 可视化决策树(简易方法)
plt.figure(figsize=(12, 8))
tree.plot_tree(clf, filled=True, feature_names=X.columns, class_names=['low', 'high'], rounded=True)
plt.show()- 代码思路及解释:
- 读取数据并进行预处理:使用pandas的read_csv函数读取CSV文件中的数据。使用LabelEncoder将分类特征(天气、是否周末、是否有促销)转换为数值型数据。这是因为决策树算法需要数值输入。LabelEncoder的fit_transform方法用于学习标签的编码并将其转换为相应的数值。
- 分离特征和目标变量:特征(X)是从数据中提取的输入变量,即weather、is_weekend和is_promotion。目标变量(y)是模型需要预测的变量,即sales_volume。
- 划分训练集和测试集:使用train_test_split函数将数据集分为训练集和测试集,其中30%的数据用作测试集,70%的数据用作训练集。random_state参数确保每次分割都是可重复的。
- 使用CART决策树构建模型:创建DecisionTreeClassifier实例,并设置criterion='gini'参数来使用基尼不纯度作为节点分裂的标准,这是CART算法的默认设置。
- 评估模型准确率:使用训练好的模型对测试集进行预测,并使用score方法计算模型的准确率。
- 可视化决策树:使用matplotlib和sklearn.tree.plot_tree函数可视化训练好的决策树。filled参数为True表示用不同的颜色填充节点,以区分不同的类别。feature_names和class_names参数分别指定特征名称和类别名称,使树的结构更易于理解。rounded参数为True表示节点的形状为圆角矩形。
- 三种方法比较
ID3、CART和C4.5是三种不同的决策树算法,它们在构建决策树时使用不同的标准来选择最佳分裂属性。下面是每种算法的特点以及如何在代码中实现它们:
- ID3 :使用信息增益作为分裂标准。只适用于分类属性。Python的sklearn库没有直接实现ID3算法,但可以使用DecisionTreeClassifier并通过设置criterion='entropy'来近似实现,因为信息增益与熵(Entropy)相关。
- C4.5:是ID3的改进版本,使用信息增益比(Information Gain Ratio)作为分裂标准。可以处理数值属性,并且可以处理缺失值。sklearn没有直接实现C4.5算法,但可以通过设置DecisionTreeClassifier的criterion='entropy'并结合一些预处理步骤来近似实现。
- CART :使用基尼不纯度或信息增益作为分裂标准。适用于分类和回归问题。sklearn的DecisionTreeClassifier默认使用基尼不纯度(criterion='gini'),可以通过设置criterion='entropy'来使用信息增益。
- 实验收获
- 更好地理解了三种算法对解决决策树问题的原理与差异。
- 理解特征选择的重要性:如何根据不同算法的特性选择合适的特征,以及特征工程在决策树学习中的重要性。
- 加深对信息熵、信息熵增益的理解,理解了特征与信息熵的关系,更好地分析解决实际问题。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)