如何使用yolov8训练评估可视化——电梯行为检测数据集 扶梯危险行为检测 电梯安全行为检测数据集 5000张图像,提供voc,yolo两种标注 1.3GB 2类
如何使用yolov8训练评估可视化——电梯行为检测数据集 扶梯危险行为检测 电梯安全行为检测数据集 5000张图像,提供voc,yolo两种标注 1.3GB 2类
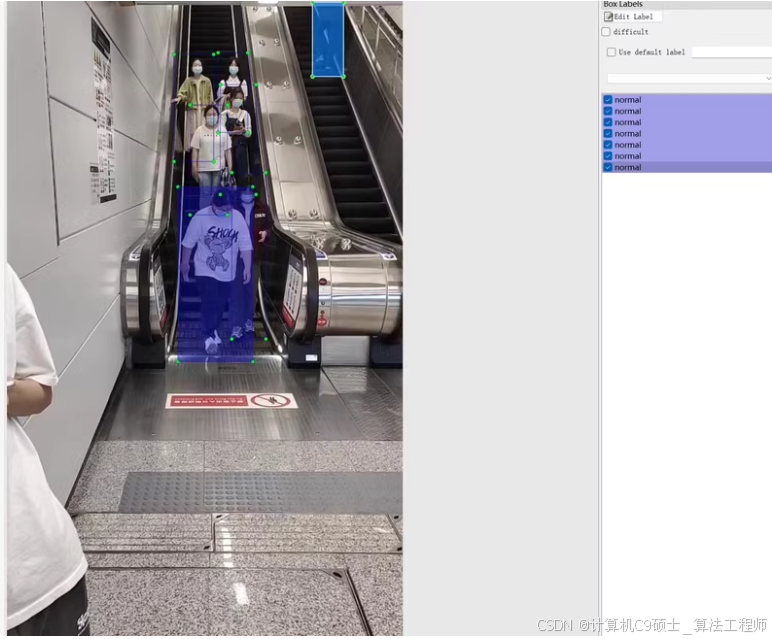
电梯扶梯危险行为检测数据集
共约5000张图像,提供voc,yolo两种标注方式,1.3GB数据量,标注异常和正常两种状态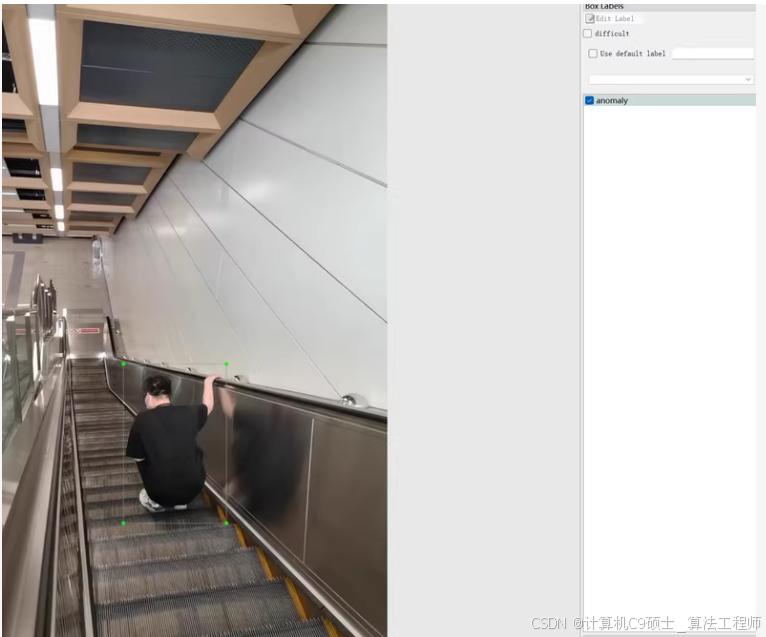
针对电梯扶梯危险行为检测的数据集,我们可以使用YOLOv8模型进行训练和评估。这个数据集包含约5000张图像,并且已经用VOC和YOLO格式标注了两种状态:异常(存在危险行为)和正常(无危险行为)。我们将重点放在YOLO格式的标注上,因为YOLOv8模型直接支持这种格式。
1. 环境准备
首先,确保你已经安装了必要的库和工具。你可以使用以下命令安装所需的库:
pip install torch torchvision
pip install numpy
pip install pandas
pip install matplotlib
pip install opencv-python
pip install pyyaml
pip install ultralytics
2. 数据集准备
假设你的数据集目录结构如下:
escalator_safety_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
├── labels/
│ ├── train/
│ ├── val/
│ └── test/
└── escalator_safety.yaml
每个图像文件和对应的标签文件都以相同的文件名命名,例如 0001.jpg 和 0001.txt。
3. 创建数据集配置文件
你已经有一个 escalator_safety.yaml 文件,内容如下:
train: ../escalator_safety_dataset/images/train
val: ../escalator_safety_dataset/images/val
test: ../escalator_safety_dataset/images/test
nc: 2
names: ['Normal', 'Abnormal']
4. 安装YOLOv8
克隆YOLOv8仓库并安装依赖项:
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
5. 训练模型
使用YOLOv8的训练脚本进行训练。确保你已经在 escalator_safety.yaml 中指定了正确的路径。
yolo task=detect mode=train model=yolov8n.yaml data=escalator_safety.yaml epochs=100 imgsz=640 batch=16
epochs=100:设置训练轮数。imgsz=640:设置输入图像大小。batch=16:设置批量大小。根据你的GPU内存大小调整这个值。
6. 评估模型
训练完成后,可以使用YOLOv8的评估脚本来评估模型在验证集上的性能。
yolo task=detect mode=val model=runs/detect/train/weights/best.pt data=escalator_safety.yaml
7. 测试模型
为了评估模型在测试集上的性能,可以使用以下命令:
yolo task=detect mode=test model=runs/detect/train/weights/best.pt data=escalator_safety.yaml
8. 可视化预测结果
使用以下Python代码来可视化模型的预测结果。
import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/detect/train/weights/best.pt')
# 读取图像
image_path = 'escalator_safety_dataset/images/test/0001.jpg'
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 进行预测
results = model(image)
# 绘制预测结果
results.print()
results.show()
9. 模型优化
为了进一步优化模型,可以尝试以下方法:
- 调整超参数:使用不同的学习率、批量大小、权重衰减等。
- 使用预训练模型:使用预训练的YOLOv8模型作为初始化权重。
- 增加数据量:通过数据增强或收集更多数据来增加训练集的多样性。
- 模型融合:使用多个模型进行集成学习,提高预测的准确性。
- 更复杂的网络结构:尝试使用更大的YOLOv8模型,如
yolov8s,yolov8m,yolov8l,yolov8x。 - 数据增强:使用数据增强技术,如旋转、缩放、翻转等,以增加模型的鲁棒性。
- 类别平衡:如果某些类别的样本数量不平衡,可以使用类别平衡技术,如过采样或欠采样。
10. 数据增强
使用 albumentations 库进行数据增强,以提高模型的泛化能力。
import albumentations as A
from albumentations.pytorch import ToTensorV2
transform = A.Compose([
A.Resize(640, 640), # 根据需要调整尺寸
A.Rotate(limit=35, p=1.0),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
])
11. 自定义数据加载器
创建自定义的数据加载器来读取图像和标签。
import os
import cv2
import numpy as np
from torch.utils.data import Dataset, DataLoader
class EscalatorSafetyDataset(Dataset):
def __init__(self, image_dir, label_dir, transform=None):
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.images[idx])
label_path = os.path.join(self.label_dir, self.images[idx].replace('.jpg', '.txt'))
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
with open(label_path, 'r') as f:
labels = [list(map(float, line.strip().split())) for line in f.readlines()]
if self.transform is not None:
transformed = self.transform(image=image, bboxes=labels)
image = transformed['image']
labels = transformed['bboxes']
return image, labels
12. 训练代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
# 超参数
batch_size = 16
num_epochs = 50
learning_rate = 0.001
# 数据加载器
train_dataset = EscalatorSafetyDataset(train_image_dir, train_label_dir, transform=transform)
val_dataset = EscalatorSafetyDataset(val_image_dir, val_label_dir, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# 模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov8n.yaml')
model.to(device)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# TensorBoard
writer = SummaryWriter('runs/escalator_safety_detection')
# 训练循环
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_train_loss = running_loss / len(train_loader)
writer.add_scalar('Training Loss', avg_train_loss, epoch)
# 验证
model.eval()
with torch.no_grad():
running_val_loss = 0.0
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_val_loss += loss.item()
avg_val_loss = running_val_loss / len(val_loader)
writer.add_scalar('Validation Loss', avg_val_loss, epoch)
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}')
# 保存模型
torch.save(model.state_dict(), 'yolov8_escalator_safety.pth')
13. 总结
通过以上步骤,你可以成功地使用YOLOv8模型对电梯扶梯危险行为检测的数据集进行训练、评估和可视化。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)