如何使用yolov8训练使用——管道内缺陷数据集 下水管内部损害缺陷数据集 下水道损害检测数据集 6类 ‘树根‘, ‘沉积物‘, ‘裂缝‘, ‘垃圾‘, ‘错口‘, ‘穿入 目标检测使用
如何使用yolov8训练使用——管道内缺陷数据集 下水管内部损害缺陷数据集 下水道损害检测数据集 6类 '树根', '沉积物', '裂缝', '垃圾', '错口', '穿入 目标检测使用

损害检测数据集 6类 ‘树根’, ‘沉积物’, ‘裂缝’, ‘垃圾’, ‘错口’, '穿入 目标检测使用
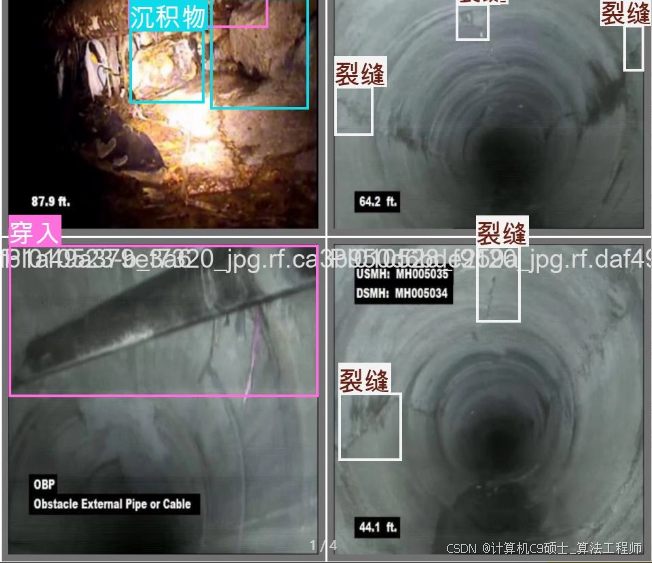
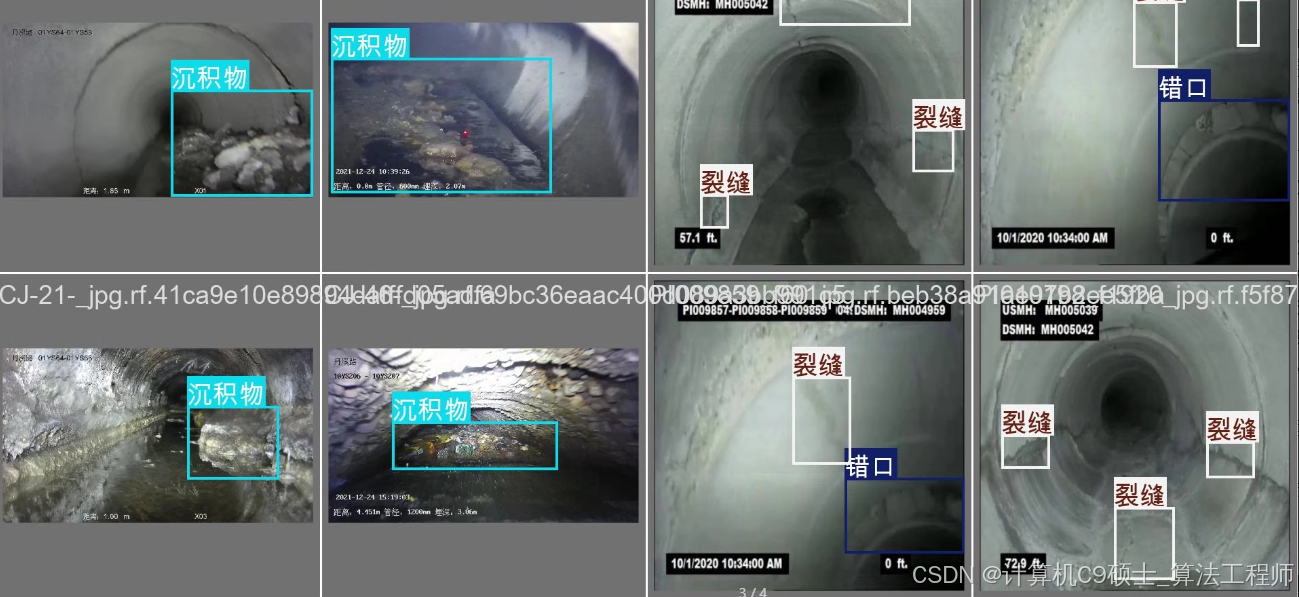
数据集介绍
数据集概述
数据集名称:Pipe Sewer Damage Detection Dataset (PSDDD)
数据类型:RGB图像
目标类别:6类管道下水道损害
图像数量:2070张
训练集:1656张
验证集:414张
标注格式:YOLO格式(.txt)
目标类别及统计
树根:图片数352张,标注框数707个
沉积物:图片数855张,标注框数1136个
裂缝:图片数407张,标注框数1087个
垃圾:图片数232张,标注框数279个
错口:图片数143张,标注框数160个
穿入:图片数302张,标注框数338个
数据集目录结构
深色版本
PSDDD/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
└── data.yaml
数据集配置文件
创建一个data.yaml文件,配置数据集的路径和类别信息:
yaml
深色版本
path: ./PSDDD # 数据集路径
train: images/train # 训练集图像路径
val: images/val # 验证集图像路径
nc: 6 # 类别数
names: [‘树根’, ‘沉积物’, ‘裂缝’, ‘垃圾’, ‘错口’, ‘穿入’] # 类别名称
YOLOv8训练代码
安装YOLOv8库和依赖项:
bash
深色版本
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirements.txt
训练模型:
python
深色版本
from ultralytics import YOLO
def train_model(data_yaml_path, model_config, epochs, batch_size, img_size):
# 加载模型
model = YOLO(model_config)
# 训练模型
results = model.train(
data=data_yaml_path,
epochs=epochs,
batch=batch_size,
imgsz=img_size
)
# 保存模型
model.save("runs/train/pipeline_damage_detection/best.pt")
if name == “main”:
data_yaml_path = ‘PSDDD/data.yaml’
model_config = ‘yolov8s.yaml’
epochs = 100
batch_size = 16
img_size = 640
train_model(data_yaml_path, model_config, epochs, batch_size, img_size)
详细解释
安装YOLOv8和依赖项:
克隆YOLOv8仓库并安装所有必要的依赖项。
训练模型:
导入YOLOv8库。
加载模型配置文件。
调用model.train方法进行训练。
保存训练后的最佳模型。
运行训练脚本
将上述脚本保存为一个Python文件(例如train_yolov8.py),然后运行它。
bash
深色版本
python train_yolov8.py
输出结果
运行脚本后,YOLOv8会在指定的输出目录中生成训练日志和最佳模型文件。你可以使用这些模型文件进行推理和评估。
转换标注格式(可选)
如果你的数据集是VOC格式的,需要将其转换为YOLO格式。以下是转换脚本:
python
深色版本
import xml.etree.ElementTree as ET
import os
def convert_voc_to_yolo(voc_file, yolo_file, class_names):
tree = ET.parse(voc_file)
root = tree.getroot()
width = int(root.find('size/width').text)
height = int(root.find('size/height').text)
with open(yolo_file, 'w') as f:
for obj in root.findall('object'):
class_name = obj.find('name').text
if class_name not in class_names:
continue
class_id = class_names.index(class_name)
bbox = obj.find('bndbox')
x_min = float(bbox.find('xmin').text)
y_min = float(bbox.find('ymin').text)
x_max = float(bbox.find('xmax').text)
y_max = float(bbox.find('ymax').text)
x_center = (x_min + x_max) / 2.0 / width
y_center = (y_min + y_max) / 2.0 / height
w = (x_max - x_min) / width
h = (y_max - y_min) / height
f.write(f"{class_id} {x_center} {y_center} {w} {h}\n")
def convert_all_voc_to_yolo(voc_dir, yolo_dir, class_names):
os.makedirs(yolo_dir, exist_ok=True)
for filename in os.listdir(voc_dir):
if filename.endswith(‘.xml’):
voc_file = os.path.join(voc_dir, filename)
yolo_file = os.path.join(yolo_dir, filename.replace(‘.xml’, ‘.txt’))
convert_voc_to_yolo(voc_file, yolo_file, class_names)
if name == “main”:
class_names = [‘树根’, ‘沉积物’, ‘裂缝’, ‘垃圾’, ‘错口’, ‘穿入’]
voc_train_dir = ‘PSDDD/labels_voc/train’
yolo_train_dir = ‘PSDDD/labels/train’
convert_all_voc_to_yolo(voc_train_dir, yolo_train_dir, class_names)
voc_val_dir = 'PSDDD/labels_voc/val'
yolo_val_dir = 'PSDDD/labels/val'
convert_all_voc_to_yolo(voc_val_dir, yolo_val_dir, class_names)
详细解释
转换标注格式:
编写一个脚本来将VOC格式的XML文件转换为YOLO格式的TXT文件。
遍历所有VOC格式的标注文件,提取边界框和类别信息,并将其转换为YOLO格式。
运行转换脚本:
将上述脚本保存为一个Python文件(例如convert_voc_to_yolo.py),然后运行它。
bash
深色版本
python convert_voc_to_yolo.py
总结
通过以上步骤,你可以准备好管道下水道损害检测数据集,并使用YOLOv8进行训练。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)