Star 50k+ Crawl4AI: 面向大模型爬虫保姆级入门指南
Crawl4AI是一款革命性的开源智能爬虫工具,通过集成大语言模型(LLM)技术,实现了从传统"规则驱动"到"智能驱动"的范式转变。相比传统爬虫工具,Crawl4AI的核心创新在于:1)开发者只需定义所需数据结构,无需编写复杂解析规则;2)利用LLM理解网页语义内容,而非依赖固定DOM路径;3)具备强大的结构适应能力,减少前端改版的影响。该工具特别适合构建R
本文将带您深入 Crawl4AI 的世界,从其核心设计理念、与传统爬虫的根本区别,到手把手的实战教程和高级应用技巧,为您全面揭示这一开源项目的强大之处。
社区与支持: Crawl4AI 是一个充满活力的开源项目,欢迎所有开发者加入。您可以通过官方 Discord 频道与其他开发者交流、获取帮助:https://discord.gg/jP8KfhDhyN
目录
第三章:Crawl4AI vs. 传统爬虫 —— 一场全面的范式革命
第一章:时代之变 —— 为何我们需要 Crawl4AI?
1.1 传统爬虫的“旧世界”:辉煌与困境
在过去的二十年里,网络爬虫技术是数据科学、搜索引擎、市场分析等领域的基石。以 Scrapy、BeautifulSoup + Requests 等库为代表的传统爬虫,其工作模式可以概括为:
-
发送请求 (Request): 向目标服务器发送 HTTP 请求。
-
接收响应 (Response): 获取服务器返回的 HTML/JSON/XML 文档。
-
解析内容 (Parse): 开发者编写精确的解析规则(通常是 CSS 选择器或 XPath 路径),从文档中提取所需数据。
-
存储数据 (Store): 将提取的数据存入数据库、文件或其他存储介质。
这种模式在网站结构稳定的情况下非常高效、精准。然而,随着前端技术的飞速发展(如 React, Vue, Angular 等动态框架的普及),传统爬虫的弊端日益凸显:
-
脆弱性 (Brittleness): 爬虫规则与网站的 DOM 结构强耦合。哪怕网站前端进行一次微小的改版(比如
<div>换成<section>,或者类名class="product-title"改为class="item-name"),之前编写的所有解析规则就可能全部失效,导致爬虫崩溃。维护成本极高。 -
开发效率低下: 针对每一个不同的网站,开发者都需要花费大量时间去分析其页面结构,手动编写、调试一套全新的解析规则。这个过程繁琐且无法规模化。
-
无法理解语义: 传统爬虫只能“看”到结构,无法“理解”内容。它不知道
<h1>标签里的内容是文章标题,也不知道<span>¥99</span>代表的是价格。它只是机械地执行开发者给定的路径指令。 -
动态内容处理复杂: 对于大量使用 JavaScript 异步加载内容的“单页应用”(SPA),传统爬虫需要借助
Selenium、Playwright等浏览器自动化工具来模拟真实用户行为,这使得爬虫的开发和运行都变得更加复杂和缓慢。
1.2 LLM 时代的“新大陆”:对数据的渴求
进入2020年代,以 GPT 系列为代表的大语言模型(LLM)开启了人工智能的新纪元。无论是用于构建智能问答系统的 RAG (Retrieval-Augmented Generation),还是用于训练垂直领域专用模型,LLM 对数据的需求发生了质变:
-
需要结构化数据: LLM 需要的不仅仅是杂乱无章的文本。将网页内容整理成具有清晰字段(如
title,author,publish_date,content,tags)的 JSON 对象,能极大提升 RAG 的检索效率和生成质量。 -
需要语义化信息: LLM 需要理解数据的含义。例如,对于一个电商页面,LLM 需要知道“iPhone 15 Pro”是产品名,“256GB”是规格,“蓝色”是颜色。这种语义信息是传统爬虫难以提供的。
-
需要大规模、多样化的数据源: 为了构建强大的 AI 应用,我们需要从成千上万个不同结构、不同领域的网站上获取数据。使用传统爬虫为每个网站都写一套规则,这在人力和时间成本上是不可接受的。
矛盾出现了:我们拥有了能够理解自然语言的强大 LLM,但获取高质量、结构化、语义化数据的工具,却还停留在“刀耕火种”的规则时代。
1.3 Crawl4AI 的诞生:连接两个世界的桥梁
Crawl4AI 正是为解决这一核心矛盾而设计的。它的核心思想颠覆了传统爬虫的“规则驱动”模式,代之以“智能驱动”。
Crawl4AI 的核心承诺是:你告诉它你想要什么样的数据(定义一个数据结构),而不是告诉它如何去获取数据(编写解析规则)。
它将繁琐的页面分析、规则编写工作,交给了最擅长理解语言和上下文的 LLM。开发者只需要用最自然的方式(比如 Python 的 Pydantic 模型)定义一个期望的数据蓝图,Crawl4AI 就能像一个聪明的助手一样,自动阅读网页,理解其内容,并将信息填充到你指定的蓝图中。
这使得 Crawl4AI 成为:
-
一个 LLM 友好的爬虫: 它天生为生成 LLM 需要的结构化、语义化数据而设计。
-
一个开发者友好的爬虫: 它将开发者从繁琐的规则维护中解放出来,使其能专注于数据本身的应用,极大地提升了开发效率和幸福感。
第二章:原理剖析 —— 揭开 Crawl4AI 的智能面纱
要理解 Crawl4AI 的革命性,我们必须深入其内部,看看它是如何工作的。
2.1 核心架构:从“规则驱动”到“智能驱动”
Crawl4AI 的架构可以被 conceptualized 为一个智能流水线,它巧妙地组合了成熟的爬取技术和前沿的 LLM 技术。
-
爬取引擎 (Crawler Engine): 这是系统的“腿脚”。它负责处理网络请求、管理 URL 队列、执行页面导航等基础任务。底层通常会使用像
Playwright这样的现代浏览器自动化工具,确保能够完美处理 JavaScript 渲染的动态页面。 -
HTML 预处理器 (Preprocessor): 这是系统的“过滤器”。在将原始 HTML 发送给 LLM 之前,进行预处理至关重要。这一步会:
-
清理: 移除不必要的标签,如
<script>,<style>,<nav>,<footer>等,这些标签通常包含大量与主要内容无关的“噪音”。 -
简化: 可能会使用类似
readability.js的算法,提取页面的核心正文内容。 -
目的: 这一步的核心目标是降低 Token 消耗并提升信噪比。更干净的 HTML 意味着发送给 LLM 的文本更短,调用成本更低,同时 LLM 也更容易聚焦于核心信息,提取结果更准确。
-
-
智能提取核心 (LLM Extraction Core): 这是系统的“大脑”,也是最关键的部分。
-
动态提示工程 (Dynamic Prompt Engineering): Crawl4AI 不会简单地把 HTML 扔给 LLM。它会根据用户的需求(Pydantic Schema)和预处理后的 HTML,动态地构建一个高效的指令(Prompt)。这个 Prompt 大致会是这样的结构:
"你是一个专业的数据提取专家。这是某个网页的 HTML 内容:
{cleaned_html}。请从这份 HTML 中提取信息,并严格按照以下的 JSON Schema 格式返回结果:{json_schema}。请只返回符合该 Schema 的 JSON 对象,不要包含任何额外的解释或文本。" -
模式驱动提取 (Schema-Driven Extraction): 用户通过 Pydantic 定义的 Schema 会被转换成 JSON Schema,并注入到 Prompt 中。这强制 LLM 输出结构化、类型正确的数据,极大地保证了输出的可靠性。
-
-
输出与验证 (Output & Validation):
-
解析: 系统接收 LLM 返回的(通常是字符串形式的)JSON 数据。
-
验证: 使用用户最初定义的 Pydantic Schema 对 LLM 返回的 JSON 进行验证。如果验证通过,说明数据是干净、可用的。如果失败,可以触发重试或错误处理逻辑。
-
交付: 将通过验证的、结构化的 Python 对象(Pydantic model instance)返回给用户。
-
2.2 工作流程详解
让我们通过一个完整的流程来理解 Crawl4AI 是如何工作的:
-
用户:定义一个 Pydantic Schema 来描述他想要的数据(例如,一个包含
title和content的Article类),并提供一个起始 URL。 -
Crawl4AI.run(): 用户调用
run方法。 -
URL 队列: 起始 URL被放入待爬取队列。
-
爬取引擎: 从队列中取出一个 URL,使用
Playwright打开页面,等待页面加载完成(包括 JS 渲染)。获取完整的页面 HTML。 -
预处理器: 清理和简化 HTML,去除噪音。
-
智能提取核心:
-
将 Pydantic Schema 转换为 JSON Schema。
-
构建一个包含清理后 HTML 和 JSON Schema 的 Prompt。
-
通过配置好的 LLM API (如 OpenAI, Groq) 发送这个 Prompt。
-
-
LLM: “阅读”HTML,理解其内容,并生成一个符合 JSON Schema 的 JSON 字符串。
-
输出与验证: Crawl4AI 接收到 JSON 字符串,用 Pydantic 模型进行解析和验证。
-
链接发现: 在爬取过程中,爬取引擎会从页面中发现新的链接。它会根据用户设置的
url_regex(正则表达式)来判断哪些链接是需要跟进爬取的,并将符合条件的链接加入 URL 队列。 -
循环: 重复步骤 4-9,直到队列为空或达到用户设置的最大爬取深度。
-
返回结果: 将所有成功提取并验证的数据对象汇总,返回给用户。
2.3 架构可视化图表
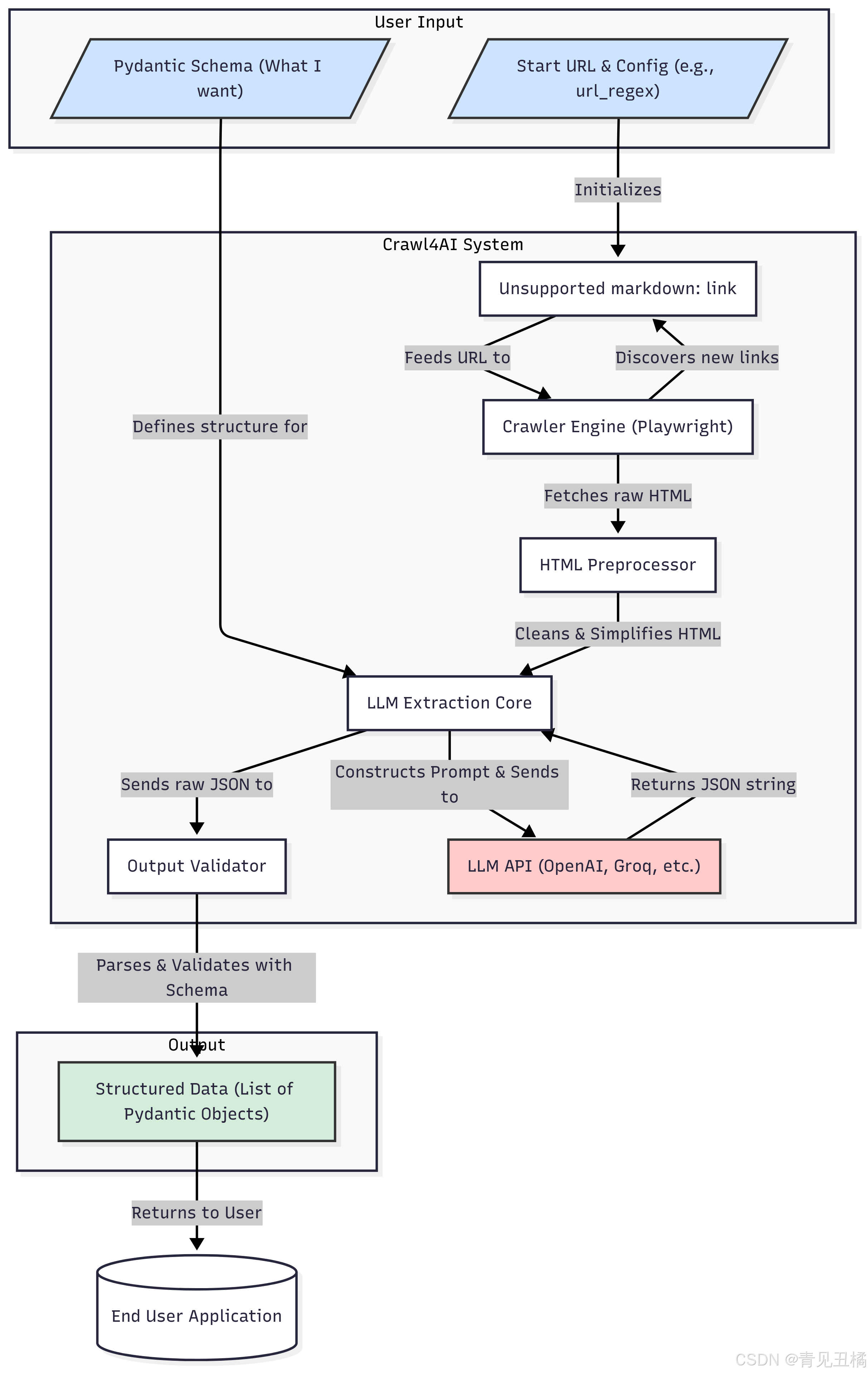
2.4 关键技术:LLM 如何替代 XPath
传统爬虫的核心是 定位 (Location)。XPath 就像一个地址,告诉爬虫去 HTML 文档的 //div[@id='main']/article[1]/h1/text() 这个位置去取东西。它不关心那里是什么,只关心路径是否正确。
Crawl4AI 的核心是 理解 (Understanding)。它把整个 HTML 文档(或其核心部分)作为上下文,然后向 LLM 提问。这个“问题”就是用户的 Schema。
-
传统方式: "Go to this specific address and grab whatever is there."
-
Crawl4AI 方式: "Read this whole document, find the main title of the article, and give it to me."
这种转变带来了巨大的优势:
-
对结构变化的鲁棒性: 即使
<h1>标签被换成了<h2>,或者它外面包裹的<div>的id变了,LLM 依然能理解哪个是标题,因为它依赖的是内容的语义和上下文,而不是固定的 DOM 路径。 -
处理非结构化信息: 对于一段没有明确标签的文字,比如 "Posted on July 26, 2025 by John Doe",传统爬虫很难用一个统一的规则提取出
publish_date和author。而 LLM 可以轻松地理解这句话的含义,并抽取出这两个字段。 -
隐式关系推断: LLM 甚至可以推断信息。如果页面上有多张图片,但只有一张图片的
alt文本与文章标题最相关,LLM 很有可能会选择这张图片作为featured_image,而传统爬虫则无法做出这种判断。
第三章:Crawl4AI vs. 传统爬虫 —— 一场全面的范式革命
现在我们已经理解了 Crawl4AI 的工作原理,让我们进行一次全方位的对比。
3.1 核心理念对比
-
传统爬虫 (Imperative - 命令式): 你必须告诉它每一步怎么做。
-
"找到所有
class="product-item"的<div>。" -
"在每个
div里,找到class="title"的<a>标签并提取文本。" -
"接着,在同一个
div里,找到class="price"的<span>标签并提取文本。" -
...
-
-
Crawl4AI (Declarative - 声明式): 你只需要声明你想要什么结果。
-
"我想要一个产品列表,每个产品包含
name和price这两个字段。"
-
这种从“命令式”到“声明式”的转变,是编程语言和框架发展的一大趋势,它极大地简化了开发,让开发者可以更专注于业务逻辑而非底层实现。
3.2 详细对比矩阵
| 特性维度 | 传统爬虫 (e.g., Scrapy, BeautifulSoup) | Crawl4AI | 备注 |
| 核心技术 | CSS 选择器, XPath, 正则表达式 | 大语言模型 (LLM), 自然语言理解 | 从“定位”到“理解”的根本转变。 |
| 开发效率 | 低至中。每个网站都需要定制开发和调试。 | 极高。定义 Pydantic Schema 即可,通常无需针对特定网站编码。 | Crawl4AI 在处理多样化网站时,效率优势呈指数级增长。 |
| 健壮性/维护 | 脆弱。网站前端微小改动即可导致爬虫失效,维护成本高。 | 强大。基于语义理解,对大多数前端样式、结构变化不敏感。 | 大大降低了长期维护的人力投入。 |
| 数据质量 | 原始或半结构化。输出的数据通常需要二次清洗和结构化。 | 高质量、结构化。直接输出经验证的、符合预定义 Schema 的 JSON 数据。 | 数据天生就是“应用就绪”(Application-Ready)的。 |
| 处理动态内容 | 复杂。需要集成 Selenium/Playwright,编写等待、点击等逻辑。 | 原生支持。内置 Playwright,自动处理 JS 渲染,对用户透明。 | 简化了对现代 Web 应用的数据抓取。 |
| 学习曲线 | 陡峭。需要掌握 HTML/CSS, XPath, 爬虫框架,反爬策略等。 | 平缓。只需要掌握基础 Python 和 Pydantic 的使用。 | 极大地降低了数据获取的门槛。 |
| 运行速度 | 快。本地解析,无外部 API 调用延迟。 | 较慢。主要瓶颈在于 LLM API 的网络延迟和处理时间。 | 速度是 Crawl4AI 的主要权衡点。 |
| 运行成本 | 低。主要是服务器和网络带宽成本。 | 较高。主要成本来自于 LLM API 的 Token 费用。 | 成本是选择 Crawl4AI 前必须考虑的重要因素。 |
| 通用性 | 差。为一个网站写的规则几乎无法用于另一个网站。 | 极强。同一套 Schema 和逻辑可以应用于无数个内容相似但结构不同的网站。 | 这是 Crawl4AI 最具革命性的特点之一。 |
3.3 适用场景分析:何时选择 Crawl4AI?
基于以上对比,我们可以清晰地界定两者的最佳使用场景。
选择传统爬虫的场景:
-
大规模、高速率的价格监控: 当你需要每分钟从固定的几个电商网站上抓取成千上万个商品的价格时,速度是第一位的,且网站结构相对稳定。此时传统爬虫的低延迟和低成本是最佳选择。
-
搜索引擎索引: 构建搜索引擎需要以极高的速度爬取海量网页,此时更关心的是文本内容和链接关系,而不是深度的结构化提取。
-
API 数据获取: 如果目标网站提供公开的 API,直接调用 API 永远是比爬取网页更稳定、更高效的选择。
选择 Crawl4AI 的场景:
-
为 RAG 系统构建知识库: 当你需要从几十个、几百个不同的新闻网站、博客、文档站点提取文章并结构化(标题、作者、日期、内容),Crawl4AI 的通用性和开发效率无人能及。
-
快速市场调研和数据分析: 需要快速从多个竞争对手或行业网站上抓取产品信息、功能列表、定价方案等进行分析。Crawl4AI 可以让你在几小时内完成传统方法需要几天甚至几周的工作。
-
非结构化内容提取: 从论坛帖子、用户评论、法律文书中提取特定实体和关系。这些场景下,内容的结构非常不规律,传统爬虫几乎无能为力。
-
概念验证 (PoC) 和快速原型开发: 在项目的早期阶段,需要快速验证一个依赖外部网页数据的想法。Crawl4AI 可以让你迅速拿到可用的结构化数据,而不用在爬虫细节上耗费时间。
-
个人项目和数据爱好者: 对于不具备深厚爬虫技术背景,但又想从网页上获取数据的个人开发者或分析师来说,Crawl4AI 极大地降低了门槛。
第四章:实战演练 —— 从零到一构建你的第一个智能爬虫
理论说再多,不如亲手一试。本章将通过几个实例,带你体验 Crawl4AI 的强大与简洁。
4.1 准备工作:环境设置与安装
1. Python 环境: 确保你已安装 Python 3.8 或更高版本。
2. 安装 Crawl4AI: 打开终端,运行以下命令:
pip install crawl4ai
3. 获取 LLM API 密钥: Crawl4AI 需要一个 LLM 后端来工作。最常用的是 OpenAI。
-
访问 OpenAI 官网 创建一个 API 密钥。
-
重要: 设置环境变量。这是最安全、最推荐的方式。
-
在 Linux 或 macOS 上:
export OPENAI_API_KEY='sk-...' -
在 Windows 上:
set OPENAI_API_KEY=sk-... -
你也可以将这行命令添加到你的 shell 配置文件中(如
.bashrc,.zshrc),这样就无需每次都设置。
-
4.2 小试牛刀:提取单个页面的结构化信息
我们的第一个目标是提取一个简单的博客文章页面。这里我们使用 Crawl4AI 官方提供的一个静态示例页面。
目标: 从 https://unclecode.github.io/crawl4ai/ 提取文章的标题、作者和内容。
第一步:定义数据结构 (Schema)
我们使用 Pydantic 来定义我们想要的数据长什么样。
import pydantic
class Article(pydantic.BaseModel):
"""
Represents a single article with its title, author, and content.
"""
title: str = pydantic.Field(description="The main title of the article")
author: str = pydantic.Field(description="The name of the person who wrote the article")
content: str = pydantic.Field(description="The full text content of the article, in Markdown format")
-
pydantic.BaseModel: 这是所有 Pydantic 模型的基础。 -
pydantic.Field: 我们可以使用Field来为每个字段添加描述。这些描述会被 Crawl4AI 用来生成更精确的 Prompt,从而引导 LLM 更好地提取信息。这是个非常有用的技巧!
第二步:编写爬虫代码
import asyncio
from crawl4ai import Crawl4AI
# 我们在上面定义的 Article Schema
from your_schema_file import Article # 假设你把上面的类存在一个文件里
async def main():
# 实例化 Crawl4AI
crawler = Crawl4AI()
# 运行爬虫
# - url: 目标网址
# - target_schema: 我们期望返回的数据结构
result = await crawler.run(
url="https://unclecode.github.io/crawl4ai/",
target_schema=Article
)
# 打印结果
if result and result.data:
# result.data 是一个 Article 类型的对象
article_data = result.data
print("--- Extracted Article ---")
print(f"Title: {article_data.title}")
print(f"Author: {article_data.author}")
print("\n--- Content ---")
print(article_data.content[:500] + "...") # 打印前500个字符
# 你可以像访问任何 Python 对象一样访问数据
# 比如,将其转换为字典
print("\n--- As Dictionary ---")
print(article_data.model_dump())
if __name__ == "__main__":
asyncio.run(main())
运行与输出:
当你运行这段代码,Crawl4AI 会在后台完成我们第二章所描述的所有流程。几秒钟后,你会看到类似这样的输出:
--- Extracted Article ---
Title: Crawl4AI: The LLM-Powered Web Crawler
Author: Uncle Code
--- Content ---
In the era of Large Language Models (LLMs), the demand for high-quality, structured data has never been higher. Traditional web scraping tools, while powerful, often require extensive manual configuration and are brittle to website updates. Crawl4AI emerges as a revolutionary open-source tool designed to address these challenges. It leverages the power of LLMs to understand and extract data from websites, allowing developers to focus on what data they need, not how to get it....
--- As Dictionary ---
{'title': 'Crawl4AI: The LLM-Powered Web Crawler', 'author': 'Uncle Code', 'content': 'In the era of Large Language Models...'}
看!我们没有写一行 XPath 或 CSS 选择器。我们只是“声明”了我们想要一个 Article 对象,Crawl4AI 就智能地为我们完成了提取。
4.3 进阶实战:爬取并结构化整个博客系列
单个页面提取很酷,但 Crawl4AI 的真正威力在于其“Crawl”能力。现在,我们的目标是爬取一个博客主页,并提取出所有文章的标题和链接。
目标: 从青见丑橘-CSDN博客提取首页的文章列表。
第一步:定义数据结构
这次我们需要一个列表。所以我们定义两个 Schema:一个代表单篇文章,一个代表文章列表。
import pydantic
from typing import List
class NewsItem(pydantic.BaseModel):
"""
Represents a single news item on the front page.
"""
title: str = pydantic.Field(description="The title of the news article")
url: str = pydantic.Field(description="The direct URL to the article")
class NewsPage(pydantic.BaseModel):
"""
Represents the entire list of news items on the page.
"""
items: List[NewsItem]
第二步:编写爬虫代码
这次,我们需要用到 url_regex 参数来告诉爬虫,在完成首页提取后,不需要进一步点击和爬取每篇文章的详情页。我们只关心首页。
import asyncio
from crawl4ai import Crawl4AI
# 假设上面的 Schema 定义在 news_schema.py
from news_schema import NewsPage
async def main():
crawler = Crawl4AI()
print("Starting crawl on Hacker News...")
result = await crawler.run(
url="https://blog.csdn.net/u012210662?spm=1011.2266.3001.5343",
target_schema=NewsPage,
# max_depth=0 意味着只处理当前页面,不跟踪任何链接
# 这对于只想提取列表页的场景非常高效
max_depth=0
)
if result and result.data:
news_page_data = result.data
print(f"\nSuccessfully extracted {len(news_page_data.items)} news items.")
print("-" * 20)
for i, item in enumerate(news_page_data.items[:5], 1): # 打印前5条
print(f"{i}. {item.title}")
print(f" URL: {item.url}")
print("\n--- Full result as JSON ---")
print(news_page_data.model_dump_json(indent=2))
if __name__ == "__main__":
asyncio.run(main())
运行与输出:
运行后,你将得到一个包含 Hacker News 首页所有新闻标题和链接的结构化 JSON 对象。
Successfully extracted 30 news items.
--------------------
1. Show HN: I built an open-source AI-powered terminal
URL: https://github.com/example/ai-terminal
2. The unreasonable effectiveness of F-strings
URL: https://blog.example.com/f-strings
3. A deep dive into modern CPU architecture
URL: https://example.com/cpu-deep-dive
...
这个例子展示了 Crawl4AI 如何轻松处理列表数据。如果你想进一步爬取每个链接并提取文章内容,你只需要:
-
修改
url_regex来匹配文章详情页的 URL 格式。 -
将
max_depth设置为一个大于0的数,比如1。 -
设计一个更复杂的 Schema 来嵌套文章详情。
而这一切,同样不需要编写任何解析规则。
4.4 更换“大脑”:使用不同的 LLM 后端
成本和速度是使用 LLM 的关键考量。Crawl4AI 设计灵活,可以轻松切换不同的 LLM 提供商。
使用 Groq (为了速度)
Groq 提供了极快的推理速度。你需要获取 Groq 的 API 密钥并设置环境变量 GROQ_API_KEY。
from crawl4ai import Crawl4AI
from crawl4ai.model import Groq
crawler = Crawl4AI(
llm=Groq(model="llama3-8b-8192") # Llama 3 8B model
)
# ... 后续的 crawler.run() 调用不变 ...
使用 Ollama (为了免费和隐私)
如果你在本地通过 Ollama 运行着开源模型(如 Llama 3, Mistral),你可以将 Crawl4AI 指向本地服务,实现零 API 成本。
首先确保你的 Ollama 服务正在运行。
from crawl4ai import Crawl4AI
from crawl4ai.model import Ollama
# 假设你在本地运行着 llama3 模型
crawler = Crawl4AI(
llm=Ollama(model="llama3")
)
# ... 后续的 crawler.run() 调用不变 ...
这种灵活性使得用户可以根据自己的需求(追求最高质量用 GPT-4, 追求速度用 Groq, 追求低成本和隐私用 Ollama)来自由配置爬虫的“大脑”。
第五章:高级话题与未来展望
5.1 成本与性能优化策略
-
选择合适的模型: 并非所有任务都需要最强大的 GPT-4 Turbo。对于简单的提取任务,使用像 Groq 的 Llama3-8B 或本地的 Mistral 模型,可以在保证质量的同时,将成本和延迟降低一个数量级。
-
精炼的 HTML 预处理: Crawl4AI 内部的预处理器已经做了很多工作。理解其原理,可以帮助你更好地评估为什么某些页面处理快,某些慢。未来版本可能会开放更多预处理配置。
-
有效利用缓存: Crawl4AI 提供了缓存机制。对于不经常变化的页面,启用缓存可以避免重复爬取和重复调用 LLM API,从而节省大量成本和时间。
-
精确的
url_regex和max_depth: 精心设计你的爬取范围,避免爬虫进入不相关的链接(如“关于我们”、“隐私政策”等),这是控制成本最直接的手段。
5.2 健壮性与错误处理
虽然 Crawl4AI 对页面结构变化有很强的抵抗力,但在实际应用中仍然会遇到问题,例如:
-
LLM 输出格式错误: 偶尔 LLM 可能无法完美遵守 JSON Schema。Crawl4AI 的 Pydantic 验证层可以捕获这些错误。你可以添加重试逻辑,或者在失败时记录下有问题的页面和 LLM 输出,以便后续分析和改进 Prompt。
-
网络问题或反爬机制: 目标网站可能会有 IP 封锁等反爬措施。Crawl4AI 支持配置代理(Proxy),可以集成专业的代理服务来解决这个问题。
5.3 Crawl4AI 的未来:走向自主智能代理
Crawl4AI 目前的模式是“声明式”的。未来,它很可能向更高级的“自主代理”模式演进。
想象一下,你不再是给它一个起始 URL 和一个 Schema,而是给它一个高级目标:
"帮我调研市场上所有主流的 AI 笔记软件,为我整理一份报告,包含它们的核心功能、定价、用户评价链接。"
这个未来的“Crawl4AI Agent”会:
-
自主规划: 自己使用搜索引擎找到相关的 AI 笔记软件官网。
-
动态适应: 访问每个网站,自主判断哪个页面是“功能介绍”,哪个是“定价”,哪个是“用户社区”。
-
自主学习 Schema: 它甚至可能不需要你预先定义 Schema,而是通过分析多个同类网站,自己总结出应该提取哪些共同的关键字段。
-
多模态能力: 不仅能读取文本,还能理解页面截图、图表甚至视频内容,提取更丰富的信息。
Crawl4AI 目前的工作,正是为实现这一宏伟蓝图奠定了坚实的基础。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)