【机器学习&深度学习】模型微调训练时的评估指标(详细版)
模型微调训练的评估指标是 “模型效果的刻度表”,从基础指标到多分类策略,再到混淆矩阵与综合报告,每个工具都有其独特价值。关键在于 结合任务场景 ,选择最能反映模型核心能力的指标,并通过多维度分析(如指标关系图、混淆矩阵细节)定位优化方向。只有科学评估,才能让模型微调真正 “调得准、效果好”!
目录
1.2.2 精确率(Precision):你说是垃圾的,有多少真的是?
1.2.3 召回率(Recall):所有垃圾邮件中,你抓住了多少?
1.2.4 F1 分数(F1 Score):“精确率”和“召回率”的平衡点

在自然语言处理(NLP)或计算机视觉(CV)等任务中,模型微调(Fine-tuning)已成为迁移学习不可或缺的步骤。我们常说“调模型”,可问题是,调到什么程度才算调得好?核心就在于:如何评估微调后的模型是否达标。
本文将系统梳理模型微调过程中的核心评估指标,帮助你科学判断模型性能,避免“调不准、评不清”的尴尬局面。
一、基础评估指标:从 “对与错” 到 “准与全”
1.1 基础评估4大指标
微调模型后,第一步就是搞清楚“预测得准不准”。以下四类基础指标,是所有监督学习任务的评估基石:
| 指标 | 公式 | 适用场景 |
|---|---|---|
| 准确率 Accuracy | (TP + TN) / (TP + TN + FP + FN) | 类别均衡时反映整体正确性 |
| 精确率 Precision | TP / (TP + FP) | 假正例代价高(如垃圾邮件) |
| 召回率 Recall | TP / (TP + FN) | 假负例代价高(如疾病漏诊) |
| F1 分数 F1 Score | 2 × (P × R) / (P + R) | 平衡考虑“准”与“全”,适合类别不平衡场景 |
理解提示:
TP:预测为正且实际为正
FP:预测为正但实际为负
FN:预测为负但实际为正
TN:预测为负且实际为负
1.2 类比理解
📦 假设你在做一个“垃圾邮件识别器”
你的模型要判断每封邮件是否是垃圾邮件(正类),正常邮件是非垃圾邮件(负类)。
模型预测后你得到这样的结果:
实际 \ 预测 垃圾邮件(正类) 正常邮件(负类) 垃圾邮件(正类) ✅ 预测对了:TP ❌ 漏掉了:FN 正常邮件(负类) ❌ 误判了:FP ✅ 没判断是垃圾:TN
缩写 中文名称 含义(预测结果 vs 实际情况) 举例说明 TP 真正例 模型预测是垃圾邮件,实际也是垃圾邮件 你说它是垃圾,它也确实是垃圾(预测对了) FP 假正例 模型预测是垃圾邮件,但实际是正常邮件 你误把正常邮件当成垃圾邮件(误判) FN 假负例 模型预测是正常邮件,但实际是垃圾邮件 你没发现它是垃圾邮件(漏掉了) TN 真负例 模型预测是正常邮件,实际也是正常邮件 你说它是正常邮件,它也确实正常(预测对了)
🧠 四个指标通俗解释
1.2.1 准确率(Accuracy):整体对的比例
你总共判断了多少封邮件?你猜对了多少?
📌 公式:
Accuracy = (TP + TN) / 总邮件数
✅ 适合用在“垃圾邮件”和“正常邮件”数量差不多时。如果90%都是正常邮件,那模型哪怕啥都不做,只说“都是正常邮件”,准确率都能高达90% —— 所以不能总用它判断。
1.2.2 精确率(Precision):你说是垃圾的,有多少真的是?
你标了10封垃圾邮件,结果只有6封真的是,其它4封是误判的(误伤),那么你的精确率是 60%。
📌 公式:
Precision = TP / (TP + FP)
✅ 适合在“误伤很严重”的场景,比如:
-
正常邮件被误判为垃圾(你可能错过重要邮件)
-
把好人当坏人(治安系统)
1.2.3 召回率(Recall):所有垃圾邮件中,你抓住了多少?
10封真实垃圾邮件你只识别出6封,那召回率是60%。还有4封你没发现,被放进了收件箱(漏判)
📌 公式:
Recall = TP / (TP + FN)
✅ 适合在“漏掉很严重”的场景,比如:
-
癌症诊断(不能漏掉任何患者)
-
安检(不能漏掉任何违禁物品)
1.2.4 F1 分数(F1 Score):“精确率”和“召回率”的平衡点
当你想又“抓得准”又“抓得全”,F1就是这个中间值。
📌 公式:
F1 = 2 × (Precision × Recall) / (Precision + Recall)
✅ 适合 类别不平衡任务(比如只有1%的邮件是垃圾),因为准确率可能失真,而F1分数更真实反映模型在“正类”上的能力。
小结
🎯 一个表格总结四者:
| 指标 | 问的问题 | 更关注哪一类错误? | 举例适用场景 |
|---|---|---|---|
| Accuracy | 总体猜对了吗? | 不区分 | 分类均衡的数据 |
| Precision | 说是“正”的,有多少是对的? | 少犯假正例(FP) | 垃圾邮件、司法错判 |
| Recall | 真正的“正”,你找到了多少? | 少漏真正例(FN) | 癌症筛查、异常检测 |
| F1 Score | 精确率 vs 召回率的折中 | 平衡两者 | 类别不平衡、重点关注正类 |
1.3 一个简单的例子练练手
假设我们有 100 封邮件:
实际有 20 封是垃圾(正类),80 封是正常(负类)
模型预测了 25 封为垃圾,其中:
真正是垃圾的有 15 封(TP)
误判的有 10 封(FP)
漏掉的垃圾邮件有 5 封(FN)
判断为正常的 75 封中有 70 封真的是正常(TN)
我们来算一下四个指标:
-
Accuracy = (TP + TN) / 所有邮件 = (15 + 70) / 100 = 85%
-
Precision = TP / (TP + FP) = 15 / (15 + 10) = 60%
-
Recall = TP / (TP + FN) = 15 / (15 + 5) = 75%
-
F1 = 2 × (0.6 × 0.75) / (0.6 + 0.75) ≈ 66.7%
1.4 大典型业务场景指标侧重
下面按 5 大典型业务场景 展开,说明为什么要偏重某一指标、具体怎么做权衡,并给出常见做法参考。读完你就知道:面对不同任务,该把“注意力”放在 Accuracy、Precision、Recall 还是 F1 上。
| 场景类型 | 错误成本特点 | 首选指标 | 为什么 | 常见做法 & Tips |
|---|---|---|---|---|
| 1. 类别基本均衡(情感三分类、猫狗二分类等) | 正反例数量相近,FP 与 FN 代价也差不多 | 准确率 (Accuracy) | 既能直观反映整体正确率,又不会被类别失衡“稀释” | - 仍需同时监控 P/R,防止模型“懒惰”- 若类别稍不平衡,可补充 Macro‑F1 |
| 2. 假正例代价高(垃圾邮件、司法误判、广告点击扣费) | 把正常样本错判为正样本会直接伤害用户或带来损失 | 精确率 (Precision) | 希望“凡是你说是正类的,基本都靠谱” | - 通过升高阈值提高 Precision- 将 FP 加入损失函数权重- 提供手动复核流程来弥补召回下降 |
| 3. 假负例代价高(癌症筛查、金融欺诈预警、危险品检测) | 漏掉真实正样本可能造成巨大风险 | 召回率 (Recall) | 情愿多报几个可复查,也不能漏掉关键正例 | - 降低阈值提升 Recall- 采用级联模型:先高 Recall 粗筛→再高 Precision 精筛- 人工二审去除 FP |
| 4. 类别极度不平衡(罕见缺陷检测、少数客户流失预测) | 正类稀少,Accuracy 失真,FP/FN 代价往往都高 | F1(宏或加权) | 同时关注“抓得全”与“抓得准”,避免单边倾斜 | - 报告 Macro‑F1 + per‑class P/R- 采样或代价敏感学习处理失衡- PR‑Curve 找最佳阈值 |
| 5. 多标签 / 大规模分类(文本多标签、商品千分类) | 单条样本可属于多类,或类数特别多 | 微平均 F1 或 Micro P/R | 把所有 TP/FP/FN 汇总,更能体现全局覆盖 | - 业务看“能覆盖多少标签” → 看 Recall- 看“推荐列表质量” → 看 Precision@k- 别忘对长尾类别做 Macro‑分析 |
具体权衡与实践建议
1、先问业务:错哪一种更痛?
-
如果“错抓”比“漏掉”更痛 → 抓 Precision
-
如果“漏掉”后果更严重 → 抓 Recall
-
两者都痛且样本少 → 看 F1
2、多维监控不只单指标
-
报告里同时列出 P、R、F1、支持数 (support)
-
绘制 PR‑Curve / ROC‑Curve,方便运营或医学专家选阈值
3、阈值调优是最简单的杠杆
-
二分类 softmax / sigmoid 输出 → 调阈值直接移动 P、R
-
训练后根据验证集或业务线下实验(A/B)选点
4、代价敏感学习
-
在损失函数里加权,把 FP 或 FN 的损失系数调高
-
适用于极端不平衡或需定量衡量金钱/风险成本
5、把评估写进持续集成
-
每次微调都产出同一套指标 + 混淆矩阵 + 曲线
-
用 TensorBoard/wandb 做曲线对比,避免“局部最优”假象
快速记忆口诀
“均衡看准率,误伤看精确;漏检看召回,两难看 F1。”
只要先搞清“正类是谁、错误代价怎么量化”,再对号入座,你就能选对评估指标,给微调找准方向。
二、多分类任务的特殊挑战:如何公平评估?
2.1 多分类3大策略
现实任务往往是多分类(如文本情感三分类、图像识别千分类),此时单一类别指标不足以反映整体性能。推荐三种策略:
✅ 宏平均(Macro Average)
-
特点:不考虑类别样本多少,平等对待每一类
-
适用场景:各类同等重要(如情感分类:正面 / 中性 / 负面)
✅ 加权平均(Weighted Average)
-
特点:按各类样本占比加权
-
适用场景:样本数量分布不均,避免小类被忽略
✅ 微平均(Micro Average)
-
特点:合并所有 TP / FP / FN 统一计算
-
适用场景:关注整体性能,适合多标签或大规模分类任务
2.2 类比理解
🎯 场景假设:你在做一个三分类任务
你有一个模型,分类情绪为:
类别 A:正面(100 个样本)
类别 B:中性(30 个样本)
类别 C:负面(20 个样本)
模型预测后,计算了每一类的指标(比如 F1):
类别 F1 分数 A 0.9 B 0.6 C 0.3
2.2.1 宏平均(Macro Average)
🎯 “平等对待每一类,不管你样本多少。”
直接 对每一类的指标求平均,不加权。
1、计算方式:
Macro F1 = (F1_A + F1_B + F1_C) / 3
= (0.9 + 0.6 + 0.3) / 3 = 0.6
2、适合场景:
-
当你想“每个类都一样重要”,即使某类样本很少(如情感分类任务中,正中负都重要)
-
可以发现模型在哪些小类上表现差 → 提醒你别忽视冷门类
❗️注意:宏平均容易被小类别“拉低平均分”,其实正是其优点:
| 优势 | 解释 |
|---|---|
| ✅ 保护小类别 | 在样本极度不平衡的情况下,像微平均(Micro Average)更容易忽略小类别的性能,只看总体数量。而宏平均会显式体现出模型在小类别上表现差,这对提高模型泛化性很关键。 |
| ✅ 适用于关注所有类别均衡性任务 | 比如医学诊断中罕见疾病检测、电商异常行为检测、舆情中的极端情绪分类 —— 小类很重要,不能被主类掩盖。 |
| ✅ 揭示模型偏见 | 如果模型总是对大类预测得很好,而对小类“乱猜”,宏平均能直接揭示这个问题,提醒我们改进数据、模型或策略。 |
3、宏平均不适用的场景:
如果你只关注整体效果(比如点击率、总体准确率),或类别分布就是重点(比如电商商品分类,热门商品更重要),那微平均或加权平均更合适。
4、宏平均一般用在哪些指标上?
常见的:Precision(精确率)
Recall(召回率)
F1-score(F1 值)
举个例子,sklearn 中:
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred, digits=4))
你会看到类似结果:
| class | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.95 | 0.98 | 0.96 | 980 |
| 1 | 0.70 | 0.45 | 0.55 | 20 |
| macro avg | 0.825 | 0.715 | 0.755 | 1000 |
| weighted avg | 0.94 | 0.96 | 0.95 | 1000 |

5、怎么看 macro avg 指标?
| 解读维度 | 怎么看 |
|---|---|
| 是否平衡 | 看 每类表现是否均衡,宏平均会暴露“最差类别”。如果 macro F1 明显低于 weighted F1,说明小类表现差。 |
| 模型公平性 | 如果你任务需要保证小类不被忽略(如欺诈识别、极端情绪),宏 F1 是你最重要的指标。 |
| 模型迭代追踪 | 用它对比不同模型在所有类上的平均表现,特别适合做 ab 测试时比谁对每类都更稳。 |
6、宏平均值低说明了什么?
它不是“模型差”,而是“某些类别表现差”。
特别是小类别表现不好,直接会把宏平均拉低。
所以宏平均是一面镜子:揭示模型最弱的短板。
7、从宏平均指标中定位模型短板
✅ 操作步骤:三步法定位短板
步骤一:看宏平均指标(macro avg)
macro avg | precision: 0.74 | recall: 0.65 | f1-score: 0.68代表模型在“平均意义下”的表现 —— 比如整体 f1 只有 0.68,说明有部分类表现很差。
步骤二:和 weighted avg 或 accuracy 做对比
weighted avg | f1-score: 0.91 accuracy | 0.92如果:
weighted avg 高但 macro avg 低 ➜ 模型偏向大类,小类可能预测得很差。
macro avg 和 weighted avg 接近 ➜ 模型各类表现均衡,无明显偏向。
步骤三:查看每个类别的指标,找“罪魁祸首”
假设分类报告如下(简化版):
类别 precision recall f1-score support A 0.98 0.99 0.99 900 B 0.60 0.40 0.48 50 C 0.55 0.35 0.42 50 macro avg 0.71 0.58 0.63 1000 🔍 解读:
类别 A 表现很好(大类)
类别 B 和 C 是小类,precision 和 recall 都很低
这就是 macro avg 被拉低的原因
✅ 短板定位结论:
问题 短板类 解释 F1 < 0.5 类别 B、C 模型要么误判太多(精确率低),要么漏判严重(召回率低),说明这两类的特征分布、样本量或训练策略存在问题
📌 如何进一步解释和修复短板?
排查方向 方法 数据问题 类 B/C 的样本太少?噪声多?标签质量差? 特征问题 类别间特征不区分?需要特征工程或模型加复杂度? 模型问题 模型结构不敏感?试试 class weight 或 Focal Loss 训练策略 类别不平衡?尝试上采样 / 下采样 / 分布重加权等方法 宏平均告诉你“模型整体表现”,具体短板要通过每类指标去查,哪类 f1 低就是该优化的方向。
8、项目落地时判断宏平均“高/低”的三个维度
| 准则 | 含义 | 对“宏平均”的判断 |
|---|---|---|
| 1️⃣ 业务价值导向 | 看分类任务对小类别的容忍度 | 小类很关键(如欺诈、医疗、风控)时,宏 F1 要尽可能高(>0.7) |
| 2️⃣ 相对性能提升 | 看和已有系统 / 基线模型的对比 | 宏 F1 比之前模型高,就可以认为是“改进” |
| 3️⃣ 类别平衡程度 | 看类别分布是否极度不均 | 样本严重不平衡(比如大类占 95%)时,宏 F1 自然会低一些,但小类的 F1 能做到 0.5 以上已不错 |
9、实际中使用的参考线(经验值)
| 宏平均 F1 | 评价 | 说明 |
|---|---|---|
| ≥ 0.80 | 表现非常好 | 各类均衡、模型鲁棒;适用于多数工业任务 |
| 0.65–0.79 | 中上水准 | 表示模型对小类也有一定学习能力 |
| 0.50–0.64 | 有提升空间 | 小类识别弱,建议增强训练策略或样本质量 |
| < 0.50 | 表现较差 | 模型可能严重偏向大类,小类预测几乎靠“蒙” |
⚠️ 特别注意:
有些场景,小类非常难学、样本稀缺,即便 F1=0.4 也比完全识别不了好很多(比如罕见病预测);
所以不要死盯数字,要看它在你的业务场景中带来了多少边际价值。
10、实际落地时的建议做法
| 步骤 | 内容 |
|---|---|
| 1️⃣ 定义业务目标 | 小类重要吗?容忍漏判吗? |
| 2️⃣ 建一个 baseline | 哪怕是逻辑回归、随机森林,先测个 macro F1 |
| 3️⃣ 跟踪改进幅度 | 不必一开始追 0.8,重点是比基线提升了多少 |
| 4️⃣ 结合其它指标 | 同时看 micro F1、accuracy、各类单独 F1,更全面 |
宏平均没有绝对标准线,以“业务价值 + 基线对比 + 类别表现平衡”为核心判断;但经验上,F1 ≥ 0.7 为好,< 0.5 是警告信号,应具体问题具体分析。
11、实际用法(看什么 + 怎么改)
| 你看到什么 | 可能原因 | 应对策略 |
|---|---|---|
| 宏 F1 很低,微 F1 高 | 模型只学会了大类,小类乱猜 | ✅ 数据采样平衡✅ 使用 Focal Loss✅ 分类阈值调优 |
| 某类 Precision 很低 | 假阳性多,模型误判该类 | ✅ 加强该类训练样本质量✅ 分析特征区分度 |
| 某类 Recall 很低 | 假阴性多,模型漏判该类 | ✅ 增强召回策略✅ 换更敏感的模型结构 |
看 macro F1,是在检查模型对“每一类都是否尊重”,不是只看总分,而是看“有没有人被冷落”。
12、小结
宏平均不是用来“表现模型好”的,而是用来“检验模型公平性”的。
2.2.2 加权平均(Weighted Average)
🎯 “样本多的类更重要,就按占比加权。”
考虑各类样本数量,对每一类指标乘上它的样本占比,再加总。
1、计算方式:
Weighted F1 = (100 × 0.9 + 30 × 0.6 + 20 × 0.3) / (100 + 30 + 20)
= (90 + 18 + 6) / 150 = 114 / 150 = 0.76
✅ 适合场景:
-
当你希望整体指标更符合数据分布
-
类别极度不均衡时,反映更“真实的平均表现”
❗️注意:小类表现差时容易被大类掩盖
2、先理解:为什么要“加权”
现实中,很多任务的类别分布是不平衡的,比如:
-
90% 是正常样本,10% 是异常
-
电商评论中,80% 是中立 / 正面,20% 是负面
你当然希望整体模型准确率高、表现好——但也别让小类“决定了全局表现”。
这时候就要用 加权平均,让样本多的类有更大的“话语权”。
3、用例子讲透:加权平均怎么计算 + 怎么理解
假设你有三类分类任务:
| 类别 | 样本数 | F1 分数 |
|---|---|---|
| A | 100 | 0.90 |
| B | 30 | 0.60 |
| C | 20 | 0.30 |
📌加权平均的计算方式如下:
Weighted F1 = (100 × 0.90 + 30 × 0.60 + 20 × 0.30) / (100 + 30 + 20)
= (90 + 18 + 6) / 150 = 114 / 150 = 0.76
📌怎么理解这个结果?
-
类 A 占了大多数(100/150),所以它的高分 主导了总分;
-
类 C 的表现虽然很差(F1=0.30),但因为样本少(20个),影响不大;
-
所以 Weighted F1 = 0.76 看起来还不错!
📌但要小心!
| 指标 | 能力 |
|---|---|
| ✅ Weighted F1 | 衡量整体模型是否符合真实数据分布 |
| ❌ 但会掩盖小类的差 | 小类表现差,可能几乎不会拉低加权平均 |
📌风险例子:
类别 A(正常):F1=0.95,占比95%
类别 B(欺诈):F1=0.10,占比5%
Weighted F1 ≈ 0.95×0.95 + 0.10×0.05 = 0.9025 + 0.005 = 0.9075
看起来模型很好,但实际小类(欺诈)几乎完全识别不了!
4、宏平均 vs 加权平均
| 对比点 | 宏平均(Macro) | 加权平均(Weighted) |
|---|---|---|
| 关注重点 | 每类都平等看待 | 样本多的类更重要 |
| 是否考虑样本数 | ❌ 不考虑 | ✅ 考虑 |
| 优点 | 关注小类表现,公平性强 | 更符合实际分布,整体可控 |
| 缺点 | 容易被小类拉低 | 小类差也看不出来 |
| 适用场景 | 医疗、金融风控、对每类都重要的任务 | 用户意图分类、产品推荐等整体准确性重要的任务 |
一句话总结:
加权平均告诉你模型在“现实数据中整体表现如何”,但不能反映模型在小类别上的公平性或识别能力。
所以实际项目中,加权 + 宏平均要一起看,一个看“整体”,一个看“短板”。
5、怎么看数据:看出模型短板、整体表现和落地分析
🧪假设你跑完模型后,得到了如下分类报告:
precision recall f1-score support Class 0 0.95 0.97 0.96 900 Class 1 0.60 0.40 0.48 50 Class 2 0.55 0.35 0.42 50 accuracy 0.92 1000 macro avg 0.70 0.57 0.62 1000 weighted avg 0.91 0.92 0.91 1000
✅ 第一步:看整体表现(accuracy 和 weighted avg)
指标 数值 解读 accuracy 0.92 模型整体预测准确率很高,看起来不错 weighted F1 0.91 模型在数据分布主导下的整体表现非常好 说明:你这个模型对“整体数据”预测效果很好,特别是样本多的那一类(Class 0)表现优秀。
✅第二步:看宏平均(macro avg)
指标 数值 解读 macro F1 0.62 明显低于 weighted F1(0.91)! macro recall 0.57 平均召回率低,模型容易漏判某些类 ⚠️ 说明:尽管整体表现好,但模型对一些类别“严重识别不佳”,小类性能是短板。
✅第三步:深入看每一类表现,找到“罪魁祸首”
类别 F1分数 支持数 问题 Class 0 0.96 900 模型预测得很好,是大类 Class 1 0.48 50 召回率只有 0.40,漏判严重 Class 2 0.42 50 更差,F1 仅 0.42,模型基本没学会这类 💥 所以:
宏平均被 Class 1、Class 2 拖了后腿
加权平均没有问题是因为 Class 0 太重,掩盖了小类问题
🚨 最终判断
结论 原因 模型“表面优秀” accuracy 和 weighted F1 高(得益于大类) 实则存在短板 macro F1 明显偏低,小类学得很差 落地风险 若业务上小类重要(比如异常检测、投诉分类等),这个模型风险极大
💡 建议优化方向
优化方向 方法 增强小类识别 上采样小类、下采样大类、使用 Focal Loss、加 class weights 检查特征区分度 是否小类没有明显特征?可尝试特征工程或引入新特征 多模型集成 对小类单独训练一个分类器,然后融合
2.2.3 微平均(Micro Average)
🎯 “不看分类别,统一把所有预测混一起算。”
微平均:把所有类的预测结果**“当成一个整体”**来看,计算模型的整体预测能力。
1、计算方法
把所有类的 TP、FP、FN 全部加总,然后统一计算一个 Precision / Recall / F1。
适合任务:多标签 或 大类数 的场景,比如:
-
一条文本可有多个标签(新闻主题分类)
-
图像识别 1000 类(ImageNet)
📌 举个例子(模拟数字):
-
全部 TP 总和:120
-
全部 FP 总和:30
-
全部 FN 总和:50
那:
Micro Precision = TP / (TP + FP) = 120 / (120 + 30) = 0.8
Micro Recall = TP / (TP + FN) = 120 / (120 + 50) = 0.705
Micro F1 ≈ 0.75
✅ 适合场景:
-
数据量大、类别多、每类数量差别大
-
更关注整体模型“预测能力”而非具体类别表现
2、类比记忆法
| 平均方式 | 类比场景 | 关键词 |
|---|---|---|
| 宏平均 | 老师给每个学生一票成绩 | 公平对待 |
| 加权平均 | 老师按学生出勤天数加权评分 | 按贡献计分 |
| 微平均 | 把所有学生作业混在一起评分 | 看总效果 |
3、直观类比:考试总分 vs 单科平均
| 类别 | 类比 |
|---|---|
| 宏平均(Macro) | 看每一科成绩分别如何,然后平均(语文60,数学100,平均80) |
| 微平均(Micro) | 看你所有题一共对了多少个(总共100题,答对90题,90分) |
4、怎么理解“把所有预测混一起算”?
你现在不是看每个类别各自 TP/FP/FN,而是所有类别的 TP/FP/FN 一起加总,再统一计算一个 Precision / Recall / F1。
5、举个详细例子(模拟 3 类分类任务)
| 类别 | TP(真预测正确) | FP(误判为该类) | FN(漏判该类) |
|---|---|---|---|
| A | 60 | 10 | 20 |
| B | 40 | 15 | 10 |
| C | 20 | 5 | 20 |
| 总和 | 120 | 30 | 50 |
📌 微平均公式:
Micro Precision = 总TP / (总TP + 总FP) = 120 / (120 + 30) = 0.80
Micro Recall = 总TP / (总TP + 总FN) = 120 / (120 + 50) = 0.705
Micro F1 ≈ 2 * P * R / (P + R) ≈ 0.75
6、 微平均适合什么场景?
| 适用场景 | 原因 |
|---|---|
| 多标签任务(multi-label) | 一条样本可能有多个标签,比如一篇新闻是「体育 + 政治」 |
| 类别数量多(千分类) | 比如图像分类、实体识别等,没必要每一类都单独评估 |
| 类别极度不均衡 | 宏平均容易被小类拉低,微平均反而更稳定 |
| 看整体模型能力 | 想知道“总的预测到底好不好”就用微平均 |
7、 场景示例
🎯 场景:多标签新闻主题分类系统
【场景描述】
你开发了一个 NLP 模型,用于给一篇新闻打上主题标签。每篇文章可能属于多个主题(多标签任务),比如:
一篇新闻同时属于「科技 + 经济」
一篇体育赛事报道也被贴了「国际 + 体育」
标签类别共有 5 类:
科技(Tech)
经济(Economy)
体育(Sports)
国际(World)
娱乐(Entertainment)
假设有以下模型输出:
文章编号 真实标签 预测标签 1 Tech, Economy Tech, Economy ✅ 全对(TP×2) 2 Sports Sports, World ✅ TP + ❌ FP 3 World, Economy Economy ✅ TP + ❌ FN 4 Entertainment (空) ❌ FN 5 Tech, Sports Tech ✅ TP + ❌ FN 📊 统计所有类别的 TP / FP / FN:
指标 数值 含义说明 TP 6 正确预测的标签总数 FP 1 错误预测多了标签 FN 3 有标签没预测出来
【微平均计算】
Micro Precision = TP / (TP + FP) = 6 / (6 + 1) = 0.857 Micro Recall = TP / (TP + FN) = 6 / (6 + 3) = 0.667 Micro F1 = 2 * P * R / (P + R) ≈ 0.75
【怎么解读这个微平均?】
Micro Precision ≈ 0.857:你预测的标签中,有 85.7% 是对的
Micro Recall ≈ 0.667:你该预测的标签中,有 66.7% 被成功识别了
Micro F1 ≈ 0.75:模型总体预测能力不错,但还有一部分没识别出来
【为什么用“微平均”而不是宏平均?】
项目 说明 多标签任务 一篇文章多个标签,宏平均不适合逐类平均计算 类别分布不均 娱乐类可能样本多,科技类样本少,用微平均不会被小类扰动太大 你关心整体预测表现 比如希望知道总共打了多少标签、成功了多少个,更关注整体预测数量和准确性
在多标签新闻分类里,微平均指标告诉你模型“整体预测了多少标签,成功了多少”,是任务总效果的真实体现。
✅ 一句话总结
微平均就像总成绩,告诉你模型整体有多能打;但它不告诉你有没有“偏科”或忽视冷门类别。
📌 总结对比表
| 策略 | 是否考虑类别样本数量 | 是否可区分类别表现 | 是否适合类别不均 | 最关注什么 |
|---|---|---|---|---|
| Macro | ❌ 不考虑 | ✅ 可区分 | ✅ 适合 | 各类表现公平性 |
| Weighted | ✅ 考虑 | ✅ 可区分 | ✅ 非常适合 | 整体平均表现 |
| Micro | ✅ 考虑(但不分类别) | ❌ 不区分 | ✅ 非常适合 | 整体覆盖率与质量 |
| 特性/指标 | 微平均(Micro) | 宏平均(Macro) | 加权平均(Weighted) |
|---|---|---|---|
| 核心计算方式 | 全部混一起算 TP/FP/FN | 每类单独算再平均 | 每类加权平均(按样本数) |
| 是否考虑样本数 | ✅ 自动考虑 | ❌ 不考虑 | ✅ 显式考虑 |
| 是否关注小类 | ❌ 不关注 | ✅ 非常关注 | ⚠️ 不太关注 |
| 易受偏数据影响 | ✅ 容忍大类主导 | ❌ 容易被小类拖垮 | ✅ 倾向大类 |
| 推荐场景 | 多标签/大类任务 | 公平性任务(医疗等) | 整体表现、符合实际分布 |
🚦选择建议
-
🤝 各类都重要 → Macro
-
🎯 想看真实平均水平 → Weighted
-
📦 类别很多 / 多标签 → Micro
-
📊 报告里推荐三种一起给出,结合支持数(support)辅助判断
三、混淆矩阵:细节中的真相
如果评估指标是总结性描述,那混淆矩阵就是错误定位的显微镜。
它以 N×N 的热力图形式呈现,N 是类别数:
-
对角线:正确预测(值越大越好)
-
非对角线:预测混淆(常见于相似类别)
-
行和 vs. 列和:揭示模型偏向与样本分布不平衡
🔍 例子:如果模型总把“猫”错判为“狗”,就会在“猫行-狗列”格子看到高值 —— 提示需要加强猫的特征区分能力。
四、精确率 vs 召回率:找到“最优阈值”
二分类模型常通过调整预测阈值(如默认 0.5)来影响预测行为:
-
提高阈值:更“谨慎”预测为正,精确率↑,召回率↓
-
降低阈值:更“大胆”预测为正,召回率↑,精确率↓
我们通常会画出精确率-召回率曲线(PR 曲线)或 F1 分数-阈值曲线,帮助找到一个平衡点,达到性能最优。
五、任务导向的指标选择指南
不同场景容忍的“错误类型”不同,指标选择要匹配业务目标:
| 场景 | 推荐指标 | 说明 |
|---|---|---|
| 类别均衡(如情感分析) | 准确率 | 直观反映整体表现 |
| 类别不平衡(如罕见病) | F1 宏平均 | 避免小类别被忽略,提升公平性 |
| 假正例代价高(如垃圾邮件) | 精确率 | 降低误判为正的风险 |
| 假负例代价高(如癌症诊断) | 召回率 | 尽量不漏掉真实正例 |
| 大类主导(如图像识别) | F1 加权平均 | 结合样本分布,合理反映整体性能 |
六、指标关系图:找到精确率与召回率的 “最佳平衡点”
在二分类任务中,模型常通过调整分类阈值(如将 “概率> 0.5” 判为正例)来平衡精确率与召回率。此时, 评估指标关系图 (图 1)能直观呈现二者的动态变化:
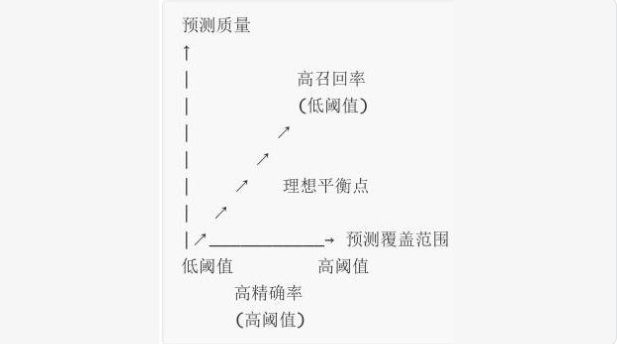
- X 轴 :预测覆盖范围(降低阈值会增加预测为正例的数量,但可能引入更多 FP)。
- Y 轴 :预测质量(预测为正例的准确性,即精确率)。
- 曲线趋势 :随着阈值降低,覆盖范围扩大(召回率提升),但预测质量下降(精确率降低)。理想平衡点是二者的调和最优位置(F1 分数最大) 。
八、指标选择指南:按需匹配场景
不同任务对 “错误类型” 的容忍度不同,需针对性选择指标:
| 场景 | 推荐指标 | 原因 |
|---|---|---|
| 类别平衡(如正负样本各半) | 准确率 | 直观反映整体正确性 |
| 类别不平衡(如罕见病检测) | F1 宏平均 | 平等对待小类别,避免大类别主导 |
| 假正例敏感(如垃圾邮件) | 精确率 | 减少 “误判为正” 的代价 |
| 假负例敏感(如疾病诊断) | 召回率 | 减少 “漏判为正” 的风险 |
| 大类别主导(如用户画像分类) | F1 加权平均 | 结合样本分布,避免小类别被忽略 |
九、综合评估报告:从 “单点” 到 “全局” 的完整视角
最终的模型效果评估需输出 综合报告 ,通常包含:
- 类别级指标 :每个类别的精确率、召回率、F1 分数(如 “体育类” 精确率 90%,“科技类” 召回率 85%)。
- 总体指标 :整体准确率(如 “全量样本准确率 88%”)。
- 平均策略结果 :宏平均、加权平均、微平均的对比(如宏平均 F1=85%,加权平均 F1=87%)。
- 支持数 :每个类别的真实样本数(辅助判断指标的可靠性,如某类别仅 10 个样本,其指标波动可能较大) 。
总结
模型微调训练的评估指标是 “模型效果的刻度表”,从基础指标到多分类策略,再到混淆矩阵与综合报告,每个工具都有其独特价值。关键在于 结合任务场景 ,选择最能反映模型核心能力的指标,并通过多维度分析(如指标关系图、混淆矩阵细节)定位优化方向。只有科学评估,才能让模型微调真正 “调得准、效果好”!
模型微调不是“调得越久越好”,而是“调得准、评得清”才最关键。
👉 高效微调的关键三问:
模型预测得准吗?(基础指标)
各类别表现公平吗?(多分类策略)
误判都出在哪?(混淆矩阵)
选择合适的评估指标、理解各类指标的意义与适用场景,再结合任务需求做权衡,你的微调才不会“南辕北辙”。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)