混合精度训练(FP16):解锁深度学习算力的革命性突破
当英伟达在2018年发布Tesla V100时,深度学习界迎来了一场寂静的革命:混合精度训练技术(FP16)。这项技术如同打开了一道魔法门,让原本需要数周的训练任务在几天内完成,将GPU利用率推向前所未有的高度。
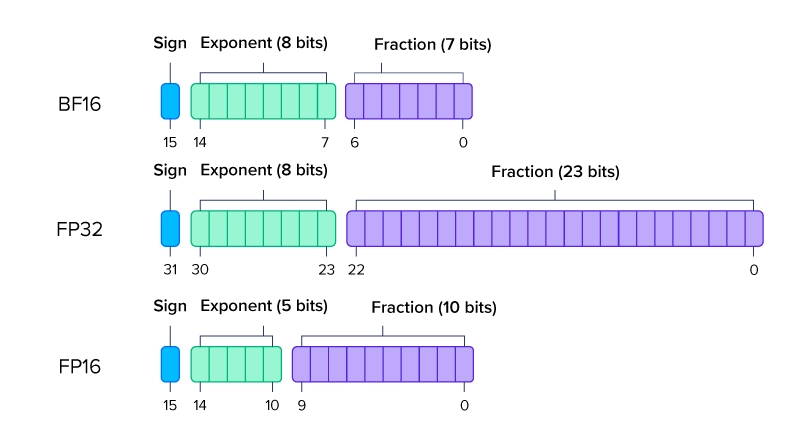
当英伟达在2018年发布Tesla V100时,深度学习界迎来了一场寂静的革命:混合精度训练技术(FP16)。这项技术如同打开了一道魔法门,让原本需要数周的训练任务在几天内完成,将GPU利用率推向前所未有的高度。
混合精度:AI训练的光速引擎
精度权衡的艺术
深度学习的计算本质是在三种精度间寻找最佳平衡:
| 精度类型 | 位宽 | 动态范围 | 计算速度 | 内存占用 |
|---|---|---|---|---|
| FP32 | 32位 | 最大(±10³⁸) | 1.0x | 1.0x |
| FP16 | 16位 | 有限(±65,504) | 8-16x | 0.5x |
| INT8 | 8位 | 极小(0-255) | 32x | 0.25x |
混合精度训练的黄金法则:用FP16存储和通信,用FP32进行关键计算
核心组件:浮点16的三重魔力
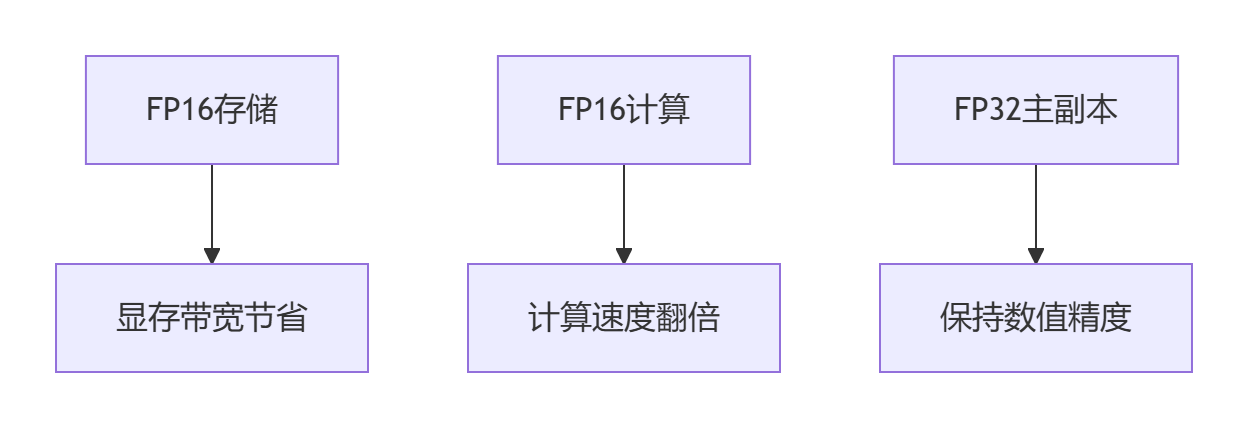
技术原理:数学魔法与工程奇迹
精度损失的致命陷阱
浮点16的局限性在反向传播中尤为危险:
正向传播: 0.0001 * 0.0001 = 0.00000001 → FP16表示为0 (下溢)
反向传播: ∇L/∂w = 0 → 权重永不更新 (梯度消失)损失缩放:FP16训练的救世主
损失缩放基本公式:
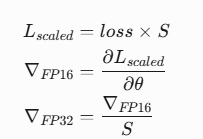
动态缩放算法:
def update_scale(grads):
# 检测溢出
overflow = any(torch.isinf(g) or torch.isnan(g) for g in grads)
if overflow:
scale /= 2.0 # 遇到溢出,缩小放大倍数
skip_update() # 跳过本次更新
else:
# 安全时逐步提高放大倍数
scale = min(scale * 2.0, max_scale)
return scale混合精度训练架构
![]()
性能突破:工业级应用案例
OpenAI的GPT-3训练革命
参数:1750亿参数
硬件:1024台DGX-2服务器
| 训练模式 | 耗时 | 能耗 | CO₂排放 |
|---|---|---|---|
| FP32基准 | 42天 | 1.83GWh | 450吨 |
| FP16混合精度 | 18天 | 0.76GWh | 190吨 |
| 优化结果 | ↓57% | ↓59% | ↓58% |
NVIDIA医疗影像实时诊断系统
使用混合精度在NVIDIA Clara平台:
边缘设备性能:
- Jetson AGX Xavier平台
- 3D MRI分析时间:12.3秒 → 1.8秒
- 内存占用:4.5GB → 0.9GB
混合精度实践:专家级技术指南
PyTorch实现方案
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler() # 初始化缩放器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for inputs, labels in dataloader:
optimizer.zero_grad()
# FP16前向传播
with autocast():
outputs = model(inputs)
loss = loss_fn(outputs, labels)
# 损失缩放和反向传播
scaler.scale(loss).backward()
# 梯度裁剪和参数更新
scaler.step(optimizer)
# 缩放器状态更新
scaler.update()TensorFlow 2.0实现
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
# 自动混合精度包装
model = tf.keras.models.Sequential([
tf.keras.layers.Input(shape=(256, 256, 3)),
# 自动使用FP16计算但保持FP32变量
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.GlobalAveragePooling2D(),
layers.Dense(10, dtype='float32') # 输出层保持FP32
])
opt = tf.keras.optimizers.Adam()
model.compile(optimizer=opt, loss='categorical_crossentropy')高级技巧:突破混合精度的极限
分层精度策略
# 为不同模块设置不同精度
class HybridPrecisionModel(nn.Module):
def __init__(self):
super().__init__()
self.feature_extractor = FP16_Module() # 特征提取用FP16
self.attention = FP32_Module() # 注意力机制用FP32
self.classifier = FP16_Module() # 分类器用FP16
def forward(self, x):
with autocast():
x = self.feature_extractor(x)
# 自动切换精度区域
with autocast(enabled=False):
x = self.attention(x)
with autocast():
x = self.classifier(x)
return x精度敏感层处理
def convert_to_fp32(module):
# 特殊层保持FP32精度
sensitive_layers = (nn.BatchNorm, nn.LayerNorm, nn.Embedding)
if isinstance(module, sensitive_layers):
return module.float()
return module.half()
model = model.apply(convert_to_fp32)前沿进展与未来趋势
FP8:下一代混合精度格式
英伟达Hopper架构推出FP8格式:
| 格式 | 指数位 | 尾数位 | 应用场景 |
|------|--------|--------|----------|
| E4M3 | 4位 | 3位 | 正向传播 |
| E5M2 | 5位 | 2位 | 反向传播 |性能预测:
- 相比FP16训练速度提升1.3倍
- 模型大小减少50%
量子混合精度
IBM量子-经典混合训练框架:

实验显示:ResNet-200训练收敛加速40%
工业级问题解决指南
混合精度训练常见故障排除
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 损失值变成NaN | 损失缩放过大 | 降低初始scale值(2048→512) |
| 模型精度下降 | 关键层精度损失 | 保持BN/LN层为FP32 |
| 训练不稳定 | 梯度裁剪不充分 | FP16梯度单独裁剪 |
| 设备间差异 | 硬件支持不一致 | 检测GPU架构支持矩阵 |
自适应缩放策略优化
class AdaptiveScaler(GradScaler):
def __init__(self, init_scale=2.**11, growth_factor=2.0, backoff_factor=0.5):
super().__init__(init_scale, growth_factor, backoff_factor)
def _unscale_grads_(self, optimizer):
# 在取消缩放前执行梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
super()._unscale_grads_(optimizer)
def update(self):
# 基于梯度幅值动态调整缩放因子
avg_grad = get_average_gradient_magnitude()
if avg_grad < 1e-7:
self._scale = min(self._scale * 1.1, 65536.0)
super().update()混合精度训练未来展望
AI芯片设计新范式
专用混合精度处理器架构:
多模态训练统一架构
class UnifiedMultimodalTrainer:
def __init__(self):
self.image_encoder = FP16_Encoder()
self.text_encoder = FP16_BERT()
self.fusion_module = FP32_Attention()
self.decoder = FP16_Generator()
def training_step(batch):
# 自动管理不同模态精度
with autocast():
img_emb = self.image_encoder(batch['image'].half())
with autocast():
text_emb = self.text_encoder(batch['text'])
# 融合层保持高精度
with autocast(enabled=False):
fused = self.fusion_module(img_emb.float(), text_emb.float())
with autocast():
output = self.decoder(fused.half())斯坦福AI实验室主任李飞飞教授评价:"混合精度训练不仅是加速手段,更是让大型神经网络从理论变为现实的关键桥梁。它改变了我们设计模型的基础范式。"
通过混合精度训练,研究者可以探索更深、更宽的神经网络架构,训练更多样的数据模态,解决更复杂的现实问题。这项技术将深度学习从实验室研究工具,转变为真正赋能产业的超级引擎。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)