TimeCMA: 通过跨模态对齐实现大语言模型驱动的多变量时间序列预测
本推文详细的介绍了一个通过跨模态对齐实现大语言模型驱动的多变量时间序列预测模型,该模型旨在解决多变量时间序列预测中信息表征弱、模型泛化差、计算开销大的关键难题。
本推文详细介绍一篇来自南洋理工大学S-Lab等机构联合发表在AAAI 2025上的文章《TimeCMA: Towards LLM-Empowered Multivariate Time Series Forecasting via Cross-Modality Alignment》,论文的共同第一作者是Chenxi Liu和Qiangxiong Xu。该工作旨在解决多变量时间序列预测中信息表征弱、模型泛化差、计算开销大的关键难题。作者创新性地提出了TimeCMA框架,通过引入大语言模型与时间序列之间的跨模态对齐机制,不仅增强了时间序列的语义理解能力,还保持了变量之间的解耦结构,并显著提升了预测精度与计算效率。论文在8个真实数据集上全面优于现有方法。
推文作者为朱旺,审校为李杨和陆新颖。
论文链接:https://arxiv.org/abs/2406.01638
开源代码链接:https://github.com/ChenxiLiu-HNU/TimeCMA
一、研究背景及主要贡献
1.1多变量时间序列预测的现状与挑战
多变量时间序列预测广泛应用于金融、交通、气象等领域,核心任务是在多个时间序列变量上,挖掘其复杂的时序与变量间交互规律,从而预测未来的变化趋势。但目前主流方法面临以下问题:
(1)数据不足与建模能力弱:传统模型训练数据量有限,模型参数量较小,难以学习复杂的变量间动态依赖;
(2)信息表征能力差:在变量多、序列长的情况下,模型难以获取足够强的语义特征;
(3)大模型计算开销高:引入LLM虽然带来强表征,但其推理速度慢、参数量大,不适合部署落地。
1.2 利用LLM的尝试与问题
近年,有学者尝试将大语言模型(LLMs)引入时间序列建模,主要方式包括Time-series-based LLMs:用LLM替代编码器,但训练数据少,迁移性弱;和Prompt-based LLMs:将时间序列转化为文本,利用LLM的语义理解增强序列表征。但这类方法直接拼接文本和序列的嵌入,会混淆语义,导致时间序列信息被稀释甚至扰乱。
1.3论文的主要贡献:
(1)首次提出跨模态对齐框架用于时间序列建模:以时间序列与语言两种视角同时建模,解决信息纠缠。
(2)设计通道级相似度检索机制:从LLM提取“既强又解耦”的时间序列特征。
(3)引入最后Token表征压缩机制:显著降低计算资源消耗,提升推理效率。
(4)实验验证优越性:在8个真实数据集上超越多个SOTA方法,平均提升10%以上。
二、方法
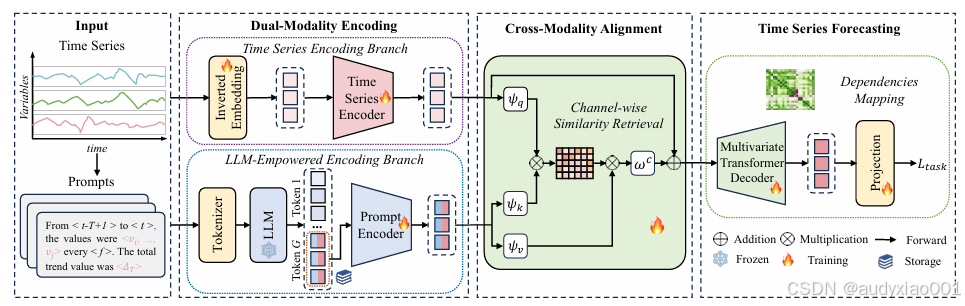
图1 TimeCMA整体框架图
如图1所示,论文提出了一个融合大语言模型和时间序列结构建模的多变量预测框架TimeCMA。其整体框架由三个模块组成:双模态编码、跨模态对齐与预测模块。首先,时间序列分支使用倒置嵌入与Transformer提取结构化、解耦的变量特征;同时,另一分支将时间序列包装为自然语言Prompt输入冻结的GPT模型,获取强语义但纠缠的嵌入,并提取最后token以压缩表示。随后,跨模态对齐模块通过通道级相似度检索机制,从Prompt中提取出与原始序列最相关的强解耦表征用于增强。最后,预测模块基于对齐后的表示进行未来时间序列的解码与预测。
2.1双模态编码模块:
双模态编码模块的核心思想是从两个视角建模输入的时间序列数据。一方面,保留时间序列自身结构的独立性和变量依赖;另一方面,借助LLM对文本形式序列的理解能力,获取更强的语义表示。在时间序列分支中,论文采用倒置嵌入策略,将每个变量的完整时间序列视为一个Token输入Transformer编码器。这种做法强调变量之间的独立性与解耦,有助于提升模型在多变量预测任务中的表现。在LLM分支中,作者将时间序列数据转换为自然语言Prompt,例如“从时间t1到tT,数值为v1到vT,总趋势为ΔT”,再输入冻结的GPT-2模型提取语义嵌入。关键在于引导LLM将序列的关键信息压缩至最后一个token,使得模型仅需保存这一token的嵌入用于下游任务,大幅减少内存与计算负担。此外,为增强Prompt的结构建模能力,该分支还加入了与时间序列分支同构的Transformer编码器。
2.2跨模态对齐模块:
TimeCMA通过相似度检索机制,将Prompt分支中具有强语义能力的表征部分挑选出来,并与时间序列嵌入融合。具体而言,论文使用三个线性投影分别将时间序列嵌入与Prompt嵌入映射为查询(q)、键(k)和值(v)。通过计算通道级的注意力相似度矩阵,将Prompt中语义最相关的维度传递回时间序列中。这种方式保留了语义强度的同时,不打破原有的变量解耦结构。最终融合后的嵌入结合了两个视角的优点,被用于后续的预测任务。
2.3时间序列预测模块:
预测模块采用一个标准的多变量Transformer Decoder架构。论文引入了masked self-attention和cross-attention两种机制,分别建模未来时间步的依赖关系和变量之间的交互信息。预测部分的最后,通过全连接映射层将解码器输出还原为预测的时间序列值,并通过反归一化获得最终结果。
三、实验及结果
TimeCMA在8个真实世界数据集上进行了全面评估,通过对比、消融、效率分析等四类实验,充分验证了模型的优越性能。
3.1 对比试验
TimeCMA在8个真实世界时间序列数据集上与现有主流方法进行了全面的性能对比,涵盖了从周期性强、趋势明显到高度动态变化的数据场景。模型性能通过均方误差与平均绝对误差两个指标进行评估,分别度量预测的偏差程度和平均误差。实验结果显示,TimeCMA在所有数据集和预测长度上都取得了最佳表现。相较于Time-LLM,TimeCMA在MSE和MAE上有较大提升。此外,即使与不基于语言模型的高效结构如FEDformer、PatchTST相比,TimeCMA依旧展现出更优的性能。对比结果充分表明,融合LLM的语义理解能力和结构建模的TimeCMA架构,在多变量时间序列预测任务中具有极强的泛化能力和表现力。
表1 对比实验结果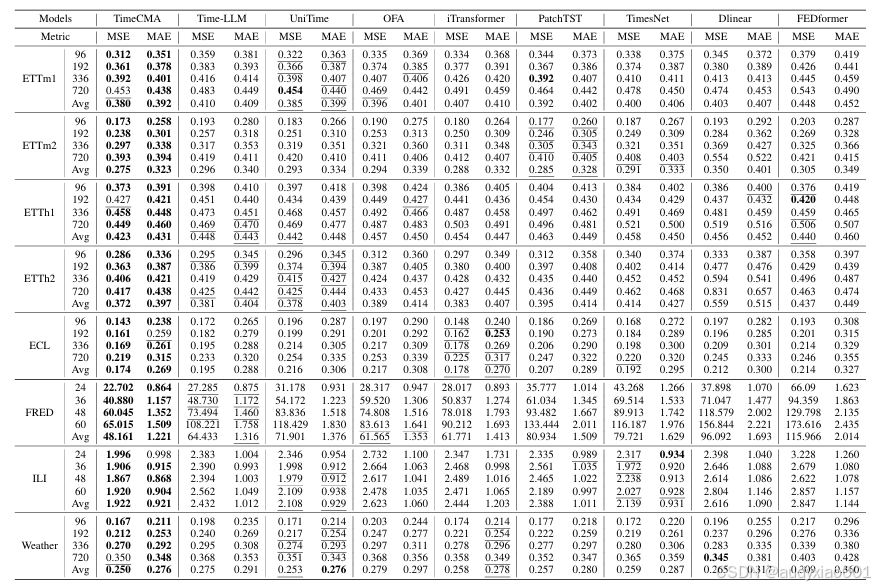
3.2 消融实验
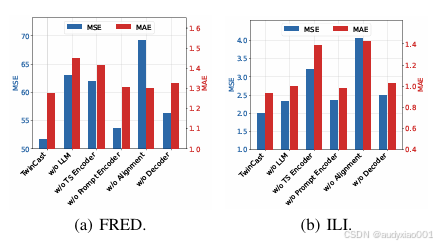
图2 消融实验结果
为了验证TimeCMA各个模块在模型性能中的作用,如图2所示,作者设计了多项消融实验,通过逐一移除模型中的关键组件并重新训练,观察性能变化情况。实验表明,移除跨模态对齐模块,即用简单拼接方式替代检索机制后,模型性能显著下降。这说明对齐模块不仅增强了表达能力,而且有效避免了信息混淆。当完全移除LLM分支,只使用传统的时间序列编码器时,性能也有明显下滑,反映出LLM所带来的高语义表征在预测中具有不可替代的作用。而如果移除时间序列编码器,仅依靠Prompt编码器与LLM,模型性能大幅下降,甚至不稳定,说明结构化时序建模仍是时间序列预测的基础。
3.3 Prompt设计实验
作者设计并比较了五种不同类型的Prompt模板,分别强调频率、预测目标、历史均值、时间段描述和趋势总结等不同要素。这些Prompt被统一用于包装时间序列输入,然后送入冻结的 GPT-2 模型进行编码。实验结果如图3所示,以“趋势”为重点的 Prompt(即 Prompt 5)在所有数据集上表现最好。这种设计将时间序列的整体方向(如上升或下降)明确表达在最后一个token中,有助于LLM在该位置聚合全局语义信息。而引导 LLM 关注平均值、时间跨度等的Prompt次之,表现稳定。相较之下,仅描述输入数据或简单提示未来预测的 Prompt效果较差,说明Prompt的结构化设计和目标导向性对模型性能影响显著。
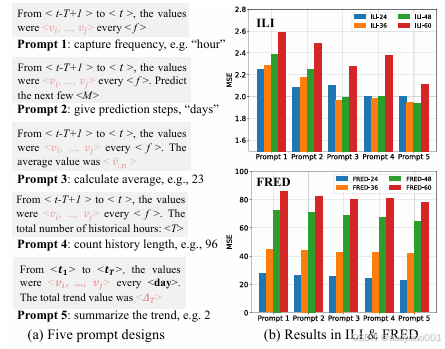
图3 Prompt设计及其结果
3.4效率分析实验
表2 效率分析实验结果
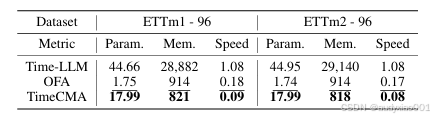
作者分别评估了模型在参数量、显存占用和推理时间三方面的表现,并与Time-LLM和OFA进行了详细对比。在确保模型性能的前提下,TimeCMA借助“最后 token嵌入存储”机制,仅保留Prompt的最后一个token作为嵌入,并将其缓存,从而避免了每次预测都重复调用LLM编码器的高开销。实验表明,TimeCMA 的参数量相比 Time-LLM 减少超过50%,显存使用也降低为其约1/3;在同一输入条件下,推理速度比Time-LLM快了近10倍。这一优化大幅提升了TimeCMA的实际可部署性。
四、总结与展望
论文提出了一个融合大语言模型和时间序列结构建模的多变量预测框架TimeCMA,为多变量时间序列预测提供了一种极具前景的范式,即通过跨模态对齐实现语言理解能力与结构化建模能力的协同融合,成功解决了长期以来困扰LLM与时间序列结合的两个核心难题。
未来,TimeCMA可扩展至多模态预测场景,如图像-文本-序列的混合建模,亦可用于金融预测、智能医疗、IoT 监控等高时效要求场景中。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)