TT100K数据集
TT100K是一个专注于小尺度交通标志检测的大规模数据集,包含来自10万张腾讯街景图的3万交通标志实例。该数据集针对传统目标检测方法在小目标识别上的不足,特别关注仅占图像0.2%的交通标志(约80x80像素)。数据集涵盖三类交通标志(警告、禁止、指示),采集自中国5个城市的不同区域。研究发现交通标志类别分布极不均衡,论文通过数据增强平衡样本,保留45类实例数大于100的标志,并对100-1000个
1.数据集简介
TT100K官网==>点这里
Tsinghua-Tencent 100K数据集:
(1)数据集庞大,采集自10万张腾讯街景图,包含3万交通实例,覆盖复杂条件像天气等。
(2)之前的卷积图像处理方式都是定位占比很大的目标,这种网络并不会很好地作用于只占图像一小部分的交通标识实例(小尺度目标数据集)。
2.论文简读
(1)PASCAL VOC and ImageNet ILSVRC(目标区域占图像的20%左右),而对于交通标志来说,大概是80x80像素,或者说,对于一个2000x2000像素的图片来说,只占据0.2%左右。
(2)在交通标志检测任务中,虽然GTSDB和GTSRB能够实现100%的精确检测和99.67%的识别率,但是检测是四选一,识别是交通标志占据图像大部分。
(3)全景图分四份得到
(4)三类交通标志。黄色警告标志(黄色三角形+黑边框+黑色信息);红色禁止标志(主体白,红边框,加图形信息);蓝色指示标志(蓝色圆圈+白色信息)。
(5)从中国5个城市十个地区,包括城市和郊区采集,下载了十万张全景图。
(6)简单标注过程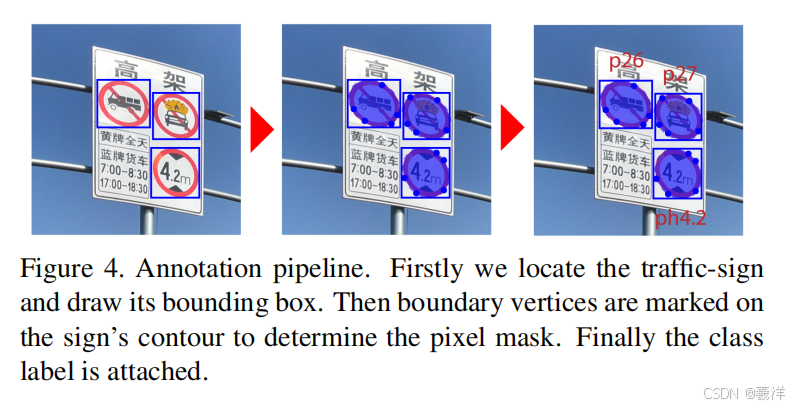
(7)复杂标注过程

(8)交通标志类别间的实例不均衡性,像注意山体滑坡这类交通标志就很少。下图是实例数大于100的交通标志的数量分布图。(后续处理数据集就可以考虑只保存这些类别,45类)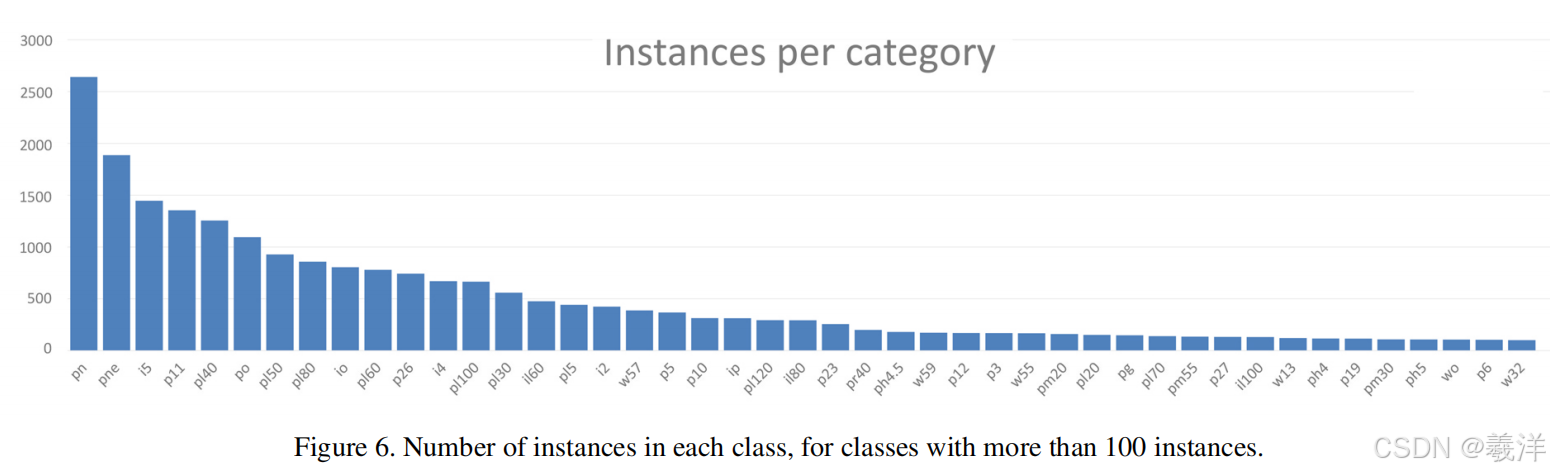
(9)实例数分布尺寸图如下。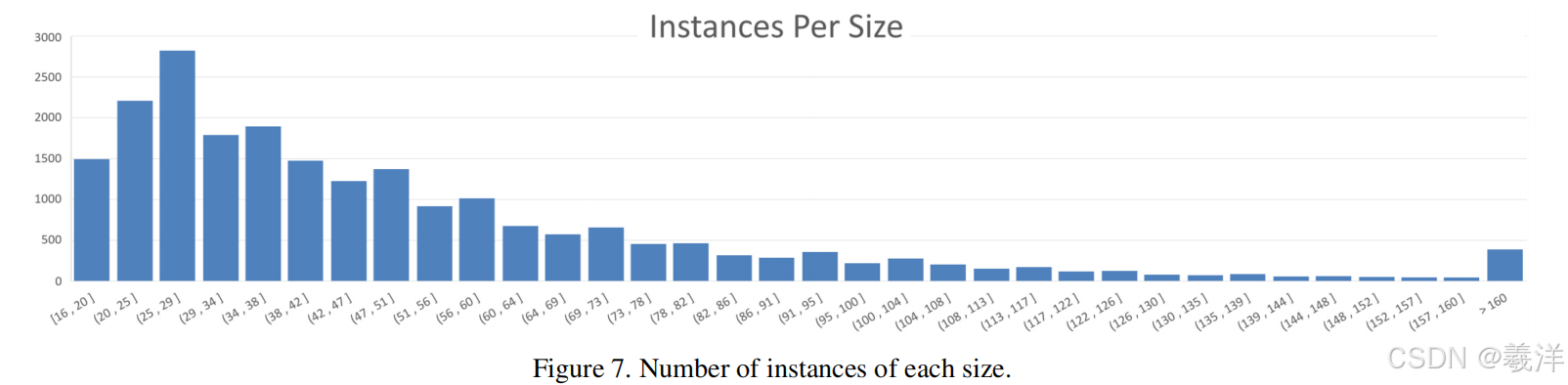
(10)论文中用到的网络。训练中过滤了实例数少于100的交通标志实例,并且将训练集中实例数在100~1000之间的实例数通过数据增强增加至1000,1000及以上的不变。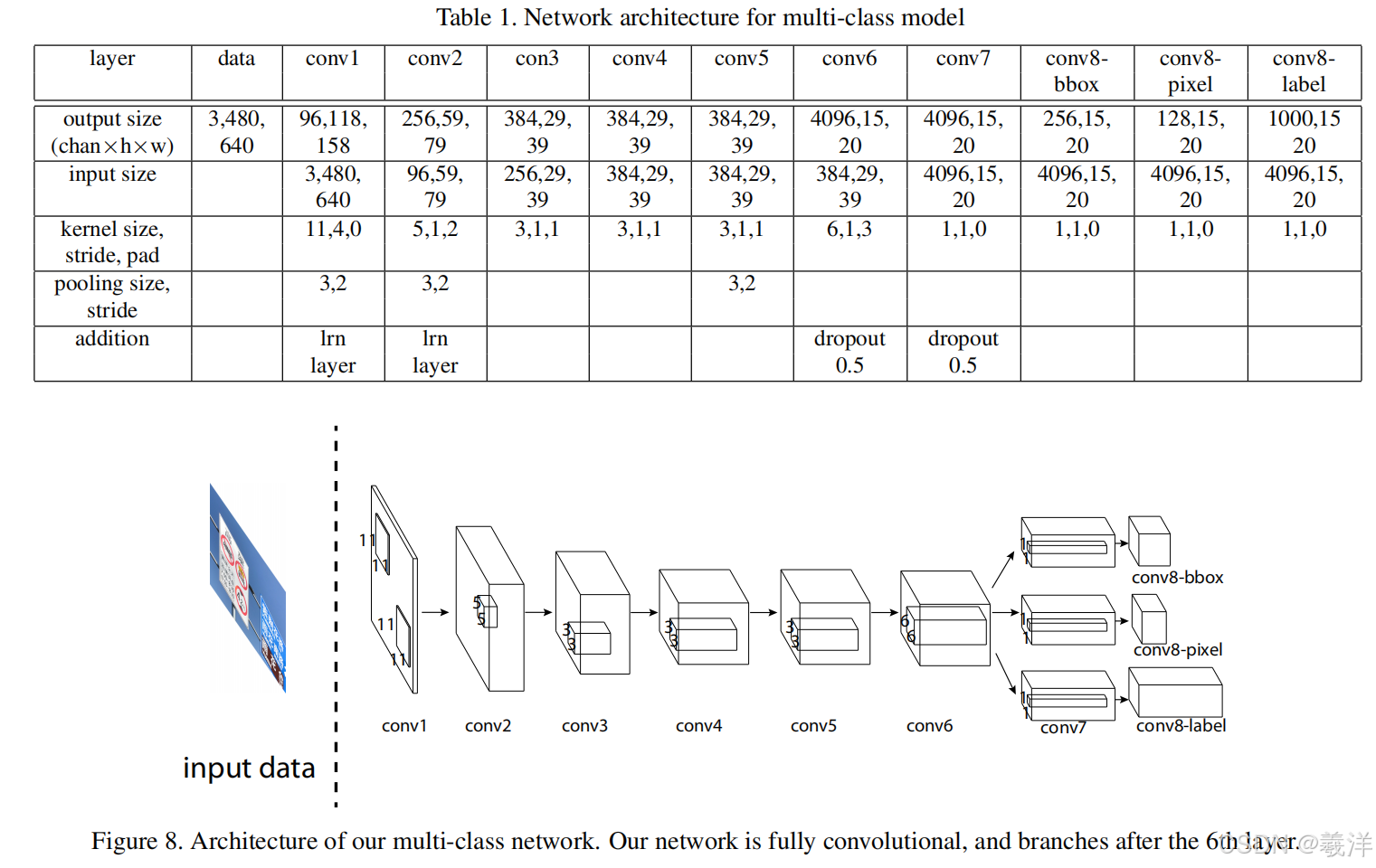
(11)数据增强策略:使用每个标志的标准模板,随机旋转 [−20°, 20°],随机缩放至[20,200],挑选没有交通标志的图像然后再加入随机噪声。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)