BridgeVLA:输入-输出对齐为基于视觉语言模型的高效 3D 操作学习
25年6月来自中科院自动化所、字节跳动、中科院大学、中科第五纪和南京大学的论文“BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models”。近年来,利用预训练的视觉语言模型 (VLM) 构建视觉语言动作 (VLA) 模型已成为一种高效的机器人操作学习方法,
25年6月来自中科院自动化所、字节跳动、中科院大学、中科第五纪和南京大学的论文“BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models”。
近年来,利用预训练的视觉语言模型 (VLM) 构建视觉语言动作 (VLA) 模型已成为一种高效的机器人操作学习方法,且前景广阔。然而,目前仅有少数方法将 3D 信号融入 VLM 进行动作预测,且未能充分利用 3D 数据固有的空间结构,导致样本效率低下。本文 BridgeVLA,这是一种 3D VLA 模型,其 (1) 将 3D 输入投影到多个 2D 图像上,确保输入与 VLM 主干模型对齐;(2) 利用 2D 热图进行动作预测,将输入和输出空间统一在一个一致的 2D 图像空间内。此外还提出一种可扩展的预训练方法,使 VLM 主干模型能够在下游策略学习之前预测 2D 热图。大量实验表明,该方法能够高效地学习 3D 操作。BridgeVLA 在三个模拟基准测试中均优于最先进的基准方法。在 RLBench 中,它将平均成功率从 81.4% 提升至 88.2%。在 COLOSSEUM 中,它在具有挑战性的泛化设置中表现出显著提升的性能,平均成功率从 56.7% 提升至 64.0%。在 GemBench 中,它的平均成功率超越了所有对比的基线方法。在真实机器人实验中,BridgeVLA 的平均成功率比最先进的基线方法高出 32%。它在多种分布外的设置中表现出稳健的泛化能力,包括视觉干扰和未见过的指令。值得注意的是,它能够在 10 多个任务中实现 96.8% 的成功率,每个任务仅需 3 条轨迹,彰显了其卓越的样本效率。
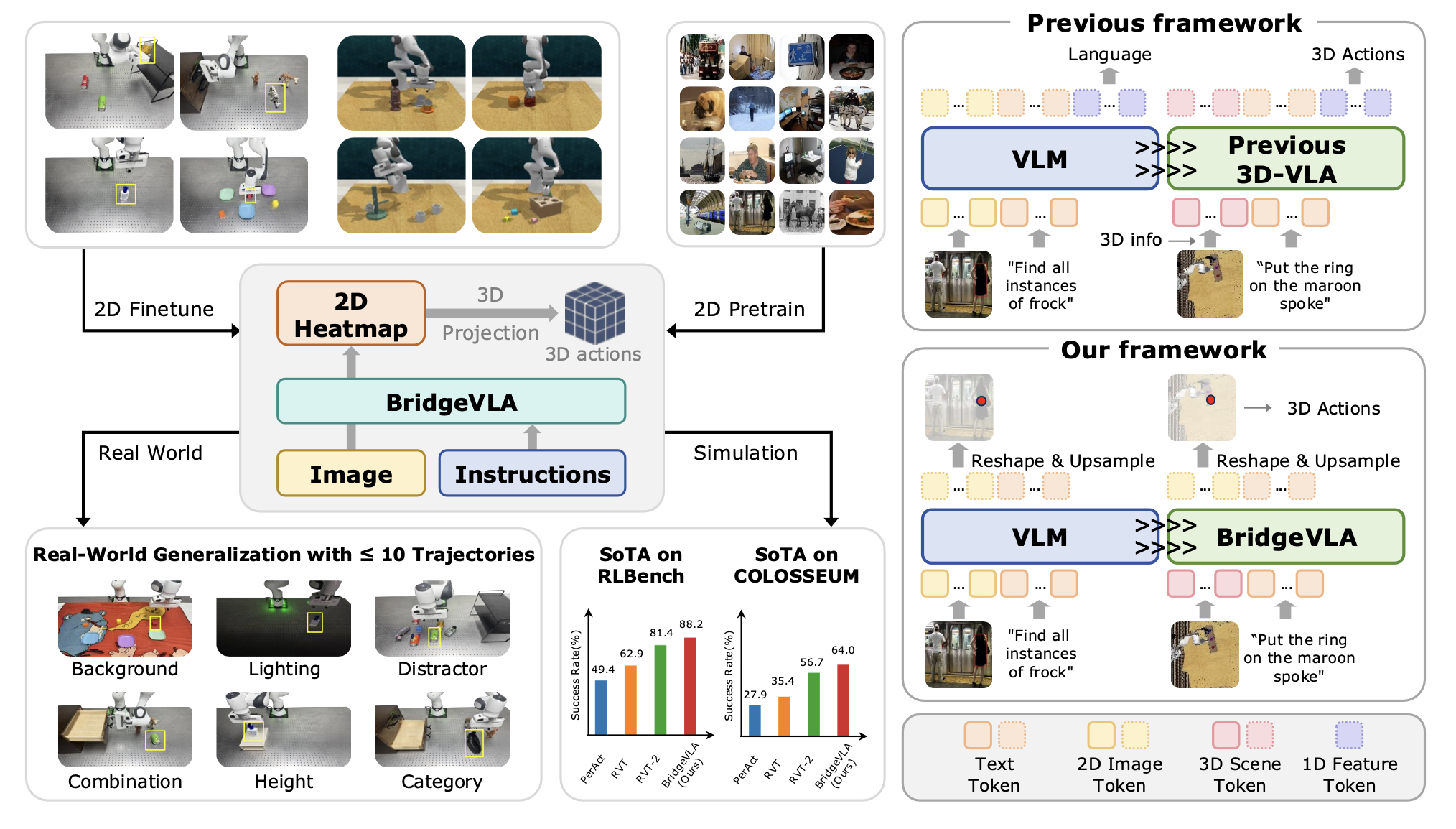
如图所示:BridgeVLA 是一个 3D VLA 模型,它将输入和输出对齐到统一的 2D 图像空间中。它使用 2D 热图进行目标定位预训练,并针对 3D 操作的动作预测进行微调。模拟和现实世界的实验结果均表明,该模型能够高效地学习 3D 操作。
预先知识
BridgeVLA 旨在学习一个多任务 3D 机器人操作策略 pi,该策略将观测值 o 和语言指令 l 映射到动作 a:
pi: (o, l) -> a
假设可以访问一组包含 N 条轨迹的专家演示 D = {ri}。每条轨迹包含一条语言指令和一系列观测-动作对,即 ri = {li,(oi_1,ai_1),…,(oi_H,ai_H)}。观测值 o 是从一个或多个视点捕获的一张或多张 RGB-D 图像。借鉴先前的研究 [10, 12, 13],动作 a 由 6 自由度末端执行器位姿 T、目标夹持器状态 g 和下一关键帧的碰撞标志 c 组成。碰撞标志 c 指示运动规划器在向目标位姿移动时是否应避免碰撞。关键帧通常捕捉轨迹中的重要步骤或瓶颈步骤 [33]。BridgeVLA 通过迭代过程运行:1)根据当前观测值 o_t 和指令 l 预测动作 a_t;2)使用基于采样的运动规划器 [34–36] 移动到预测的下一个关键帧位姿 T_t;3)更新观测值并重复此过程,直至任务完成或达到最大步长 H_max。
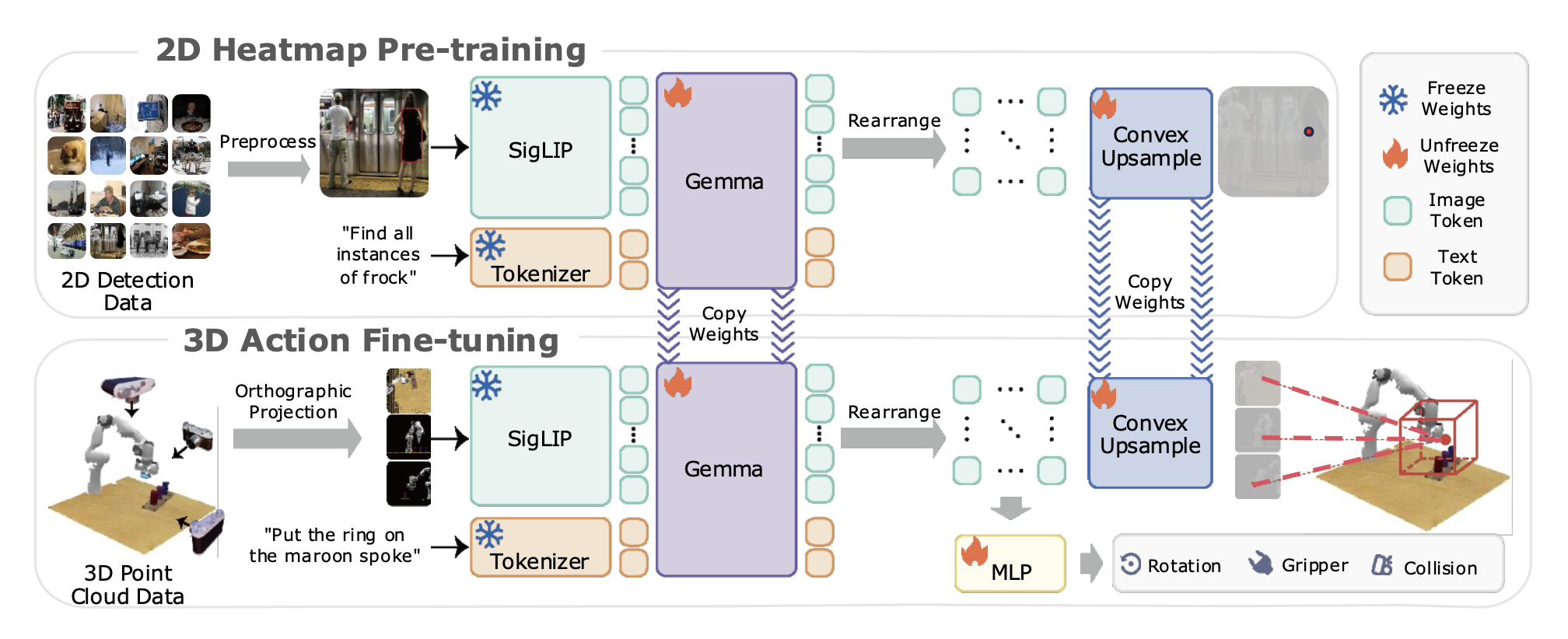
如图所示,BridgeVLA 采用双阶段训练方案。在预训练阶段,它被训练用于预测目标检测数据集上的二维热图。在微调阶段,点云被投影到多个二维图像中,作为 VLM 主干网络的输入。该模型被训练用于预测二维热图,以估计平移动作和其他动作成分。这种设计在预训练和微调阶段都将输入和输出对齐到共享的二维空间中。
二维热图预训练
VLM 主干网络最初预训练用于预测不包含空间结构的 token 序列。为了使其具备与下游策略学习相同的预测热图的能力,引入一个预训练阶段,通过热图训练模型识别目标物体。具体来说,利用 RoboPoint [37] 的 12 万个目标检测样本作为预训练数据集。对于每幅图像,根据所有感兴趣物体的边框构建真实热图 Hgt。具体来说,对于每个物体,构建一个带有空间截断的概率图 Hgt_i(x)。
对于所有感兴趣物体,通过平均化和归一化融合所有物体的概率图,以获得 Hgt。
如上图所示,将一张图片以及描述感兴趣目标的文本提示输入到 BridgeVLA 的 VLM 主干网络中。在本文中,采用 PaliGemma [1] 作为 VLM 主干模型,它由 SigLIP 视觉编码器 [38] 和 Gemma Transformer 主干模型 [39] 组成。在预训练阶段,PaliGemma 将一张或多张二维图像以及前缀文本(例如,关于图像的问题)作为输入,并输出后缀文本(例如,问题的答案)。该模型使用因果注意机制来预测后缀文本tokens,而对图像 token 和前缀文本token 则采用双向注意机制。这使得图像 token 化能够融合来自前缀文本的信息。
为了预测热图,首先根据图像块的位置重新排列输出图像 tokens,以重建空间特征网格。然后,凸上采样模块 [40] 将网格转换为与输入图像具有相同分辨率的热图。该模型采用交叉熵损失进行训练,以预测能够定位图像中所有感兴趣目标位置的热图。需要强调的是,与先前研究 [15, 16] 中使用的传统下一个 token 预测方法不同,所提出的预训练策略输出的是具有空间感知的二维热图。此外,该方法具有高度可扩展性,因为它原则上可以利用任何可构建为热图预测任务的视觉语言数据集,例如关键点检测和语义分割。
3D 动作微调
在微调过程中,首先根据已标定摄像头捕获的 RGB-D 图像重建场景的点云。为了与 VLM 主干网络的 2D 图像输入对齐,从三个视角(顶部、正面和右侧)渲染点云的三幅正交投影图像,并将这些图像用作 VLM 主干网络的输入图像,就像 RVT [13] 和 RVT-2 [14] 中提到的那样。然后,这些图像连同任务指令一起被输入到预训练的 VLM 主干网络中,为三个视角分别生成热图。重要的是,在 VLM 前向传播过程中不加入任何其他信息(例如机器人状态),以最大限度地减少预训练和微调之间的分布偏差。
对于平移动作,对所有三个视角的热图进行反向投影,以估算均匀分布在机器人工作空间中的所有 3D 点网格的得分。得分最高的三维点的位置,决定了末端执行器在下一关键帧中的平移。与先前的研究 [13, 14] 类似,用欧拉角来表示旋转动作,其中每个轴被离散化为 72 个区间。为了预测旋转、二值化夹持器动作和防碰撞标志,整合来自全局和局部上下文的特征。对于全局特征,将最大池化应用于每个输入正交投影图像的输出 tokens,从而总共产生三个 tokens ——每个视图一个。对于局部特征,从每个视图的热力图峰值中提取一个token,同样总共产生三个tokens。所有这些 tokens 被连接起来并通过多层感知器 (MLP) 来预测旋转动作、夹持器动作和防碰撞标志。
BridgeVLA 沿袭先前研究 [14, 29] 中的方法,采用由粗到精的细化策略来实现精确的动作预测。在对原始点云进行初始预测后,将点云放大并裁剪成一个以预测平移为中心的长方体。对裁剪并放大后的点云进行第二次前向传播。第二次前向传播的预测动作将用于执行。
与预训练类似,L_trans 是一个交叉熵损失函数,用于监督平移动作的热图预测。每个正交视图的真实热图是归一化单目标概率图,其中 x_b 表示真实末端执行器位置 i 在下一关键帧的投影像素位置。在将旋转的欧拉角离散化到各个 bins 中时,还在 L_rot 中应用交叉熵损失函数来监督旋转预测。对于夹持器动作和防碰撞,用 L_gripper 和 L_collision 中的二元交叉熵损失函数作为监督。为了增强几何鲁棒性,在训练过程中,随机刚体变换被联合应用于点云和真实动作。
设置。RLBench [17] 使用安装有平行爪夹持器的 Franka Panda 机器人在 CoppeliaSim [44] 中执行任务。观测数据包含四幅 RGB-D 图像,这些图像由分别位于机器人前部、左肩、右肩和腕部的四个已校准摄像头采集。基于前期研究 [10–14],在 RLBench 上对 18 项任务进行实验。这些任务涵盖:1)非抓握操作(例如,将块滑动到目标位置);2)拾取和放置(例如,堆叠杯子);以及 3)高精度插入(例如,插入钉子)。每项任务均提供 100 个专家演示。每个演示均配有语言指导和多个关键帧。模型评估通过每个任务 25 次试验的二分类成功率进行,每次试验最多包含 25 个动作步骤。
基线。将 BridgeVLA 与多个基线进行比较。 (1)Image-BC(CNN)和Image-BC(ViT)[41]是两种二维基线方法,它们分别使用CNN和ViT作为骨干,直接从二维图像预测动作。(2)C2F-ARM-BC[29]采用由粗到精的策略预测体素空间中的下一个关键帧动作。(3)PerAct[10]也在体素空间中运行,并使用感知器transformer[43]预测动作。(4)HiveFormer使用统一的多模态transformer架构整合历史信息。(5)PolarNet采用PointNext[45]对三维场景进行编码,并预测所有点的热图和偏移量以估计平移动作。(6)Act3D[12]通过从工作区中随机采样的一组点中选择得分最高的点来预测下一个关键帧动作。 (7)3D 扩散器 Actor [11] 通过基于 3D 观测和语言指令的扩散过程生成 3D 轨迹。(8)RVT [13] 使用多视图transformer从点云观测的多个正交视图中聚合信息。(9)目前最先进的方法 RVT-2 [14] 通过由粗到精的策略进一步提高了先验的精度。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 30
30 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)