Pytorch中如何使用DataLoader对数据集进行批训练
为什么使用dataloader进行批训练我们的训练模型在进行批训练的时候,就涉及到每一批应该选择什么数据的问题,而pytorch的dataloader就能够帮助我们包装数据,还能够有效的进行数据迭代,以达到批训练的目的。如何使用pytorch数据加载到模型Pytorch的数据加载到模型是有一个操作顺序,如下:创建一个dataset对象创建一个DataLoader对象循环这个DataLoader对象
·
- 为什么使用dataloader进行批训练
我们的训练模型在进行批训练的时候,就涉及到每一批应该选择什么数据的问题,而pytorch的dataloader就能够帮助我们包装数据,还能够有效的进行数据迭代,以达到批训练的目的。 - 如何使用pytorch数据加载到模型
Pytorch的数据加载到模型是有一个操作顺序,如下:
- 创建一个dataset对象
- 创建一个DataLoader对象
- 循环这个DataLoader对象,将标签等加载到模型中进行训练

- 关于DataLoader
DataLoader将自定义的Dataset根据batch size大小、是否shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练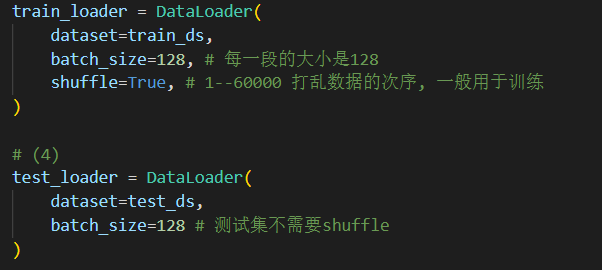
- 使用DataLoader进行批训练的例子
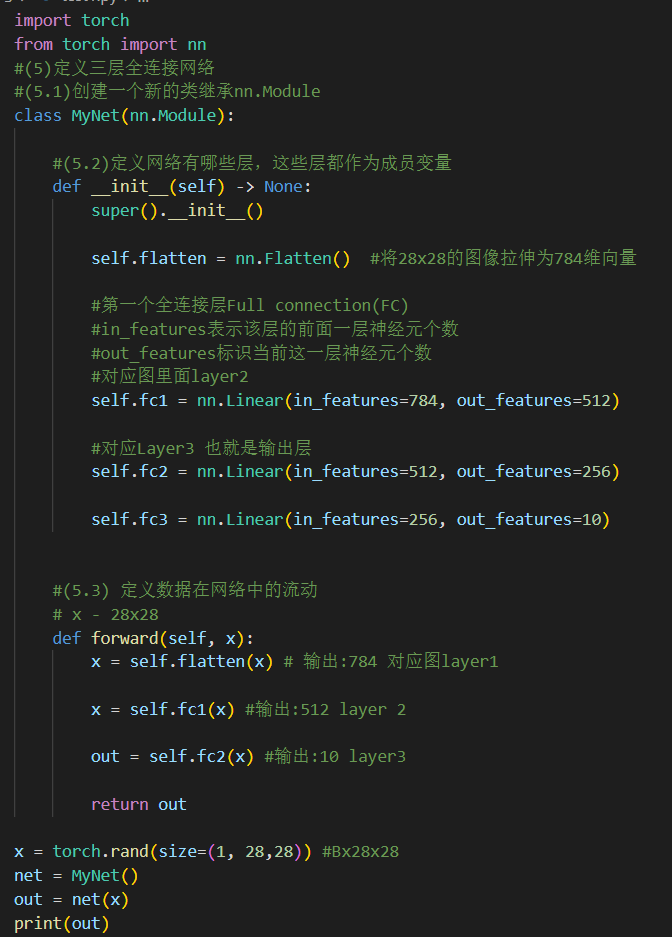
打印结果如下: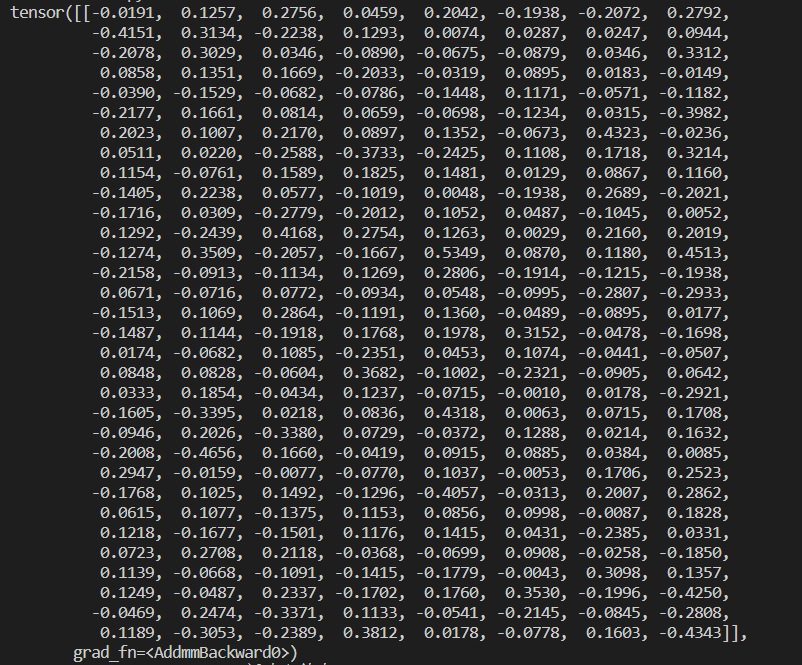
- 结语
Dataloader作为pytorch中用来处理模型输入数据的一个工具类,组合了数据集和采样器,并在数据集上提供了单线程或多线程的可迭代对象,另外我们在设置shuffle=TRUE时,每下一次读取数据时,数据的顺序都会被打乱,然后再进行下一次,从而两次数据读取到的顺序都是不同的,而如果设置shuffle=False,那么在下一次数据读取时,不会打乱数据的顺序,也因此两次读取到的数据顺序是相同的,并且我们通过借助tensor展示各种参数的功能,能为后续神经网络的训练奠定基础,同时也能更好的理解pytorch。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)