揭秘Self-RAG:引领大型语言模型生成质量的新潮流!
Self-RAG(Self-Reflective Retrieval-Augmented Generation)是一种新型的检索增强生成框架,旨在提高大型语言模型(LLM)的生成质量和准确性。Self-RAG通过引入“反思标记”(reflection tokens),使得模型能够根据具体需求动态决定是否进行信息检索。这种方法不仅减少了不必要的检索操作,还提高了生成内容的准确性和相关性。
Self-RAG(Self-Reflective Retrieval-Augmented Generation)是一种新型的检索增强生成框架,旨在提高大型语言模型(LLM)的生成质量和准确性。

Self-RAG通过引入“反思标记”(reflection tokens),使得模型能够根据具体需求动态决定是否进行信息检索。这种方法不仅减少了不必要的检索操作,还提高了生成内容的准确性和相关性。
与传统RAG相比,Self-RAG不仅增强了信息过滤和检索策略的灵活性,还能够更好地处理长尾问题和多样化信息需求,使得生成结果更加精准和高效。
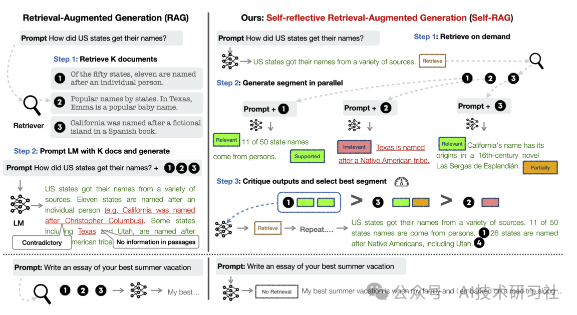
Self-RAG的工作流程主要包括以下几个步骤:
- 检索决策:
- 模型首先生成一个检索标记,以评估是否需要从外部资源检索信息。如果不需要检索,模型将直接生成答案;如果需要,则进行相关文档的检索。
- 生成内容:
- 在检索到相关文档后,模型会生成基于这些文档的内容,并使用批判标记(critique tokens)来评估生成的答案是否准确和有用。
- 自我评估:
- Self-RAG还会对生成的内容进行自我评估,确保输出的质量和事实准确性。这种自我反思的机制使得模型能够在生成过程中不断优化其输出。
论文开源项目self-rag(https://github.com/AkariAsai/self-rag)实现了自反射RAG。可以从HuggingFace Hub下载Self-RAG。对于推理,该项目建议使用VLLM来提高推理的效率。其他更多内容,读者可访问该项目自行阅读。
from vllm import LLM, SamplingParams
model = LLM("selfrag/selfrag_llama2_7b", download_dir="/gscratch/h2lab/akari/model_cache", dtype="half")
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False)
def format_prompt(input, paragraph=None):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the difference between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))
此外,LangChain框架也实现了Self-RAG的应用,其中LangChain框架被用来处理检索增强生成(RAG)的复杂流程,LangGraph则是用于从头构建图工作流的工具。
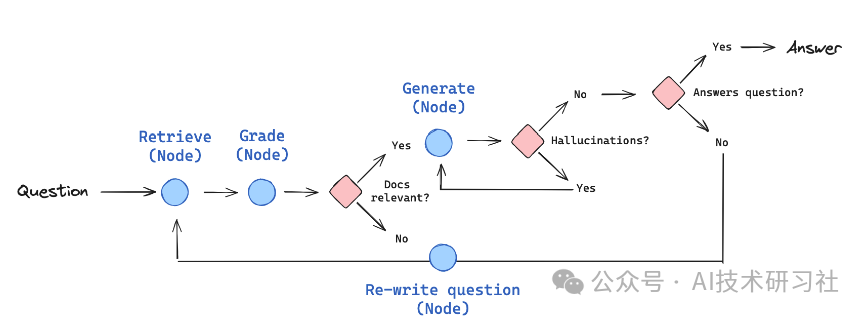
这种工作流的设计使得各节点可以独立处理不同的任务,并根据上下文动态调整执行顺序,提高了模型生成回答的质量和适应性。每个节点代表一个特定的处理步骤(如检索、生成、评估等),而边则定义了各步骤之间的依赖关系和数据流向。
关键代码:
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
完整代码参考:https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_self_rag.ipynb
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

{kind=link}
所有评论(0)