【Hugging Face】Hugging Face数据集的基本使用
前面我们了解了Hugging Face Space空间的基本使用方式,今天我们探索一下Hugging Face DataSets的基本使用方式。
前言
前面我们了解了Hugging Face Space空间的基本使用方式,今天我们探索一下Hugging Face DataSets的基本使用方式。对往期内容感兴趣的小伙伴也可以看往期:
- 【Hugging Face】初识Hugging Face
- 【Hugging Face】Hugging Face Hub与Hugging Face CLI
- 【Hugging Face】Hugging Face Space空间的基本使用方式
查找DataSets
在Hugging Face首页点击【DataSets】进入数据集列表,通过Hugging Face提供的筛选过滤找到自己想要的数据集
点击某个数据集可以看到数据集的详细介绍,这里以 ruozhiba_gpt4 为例
点击数据集的【复制】按钮可以复制数据集的名称

设置镜像源
由于HuggingFace的数据集存储在谷歌云盘上,在国内加载时可能会遇到网络问题,如遇到问题可以将镜像源切换到国内镜像
国内镜像地址:https://hf-mirror.com
对于huggingface-cli不了解的小伙伴可以看往期:【Hugging Face】Hugging Face Hub与Hugging Face CLI
在命令行终端执行以下命令
$ huggingface-cli env
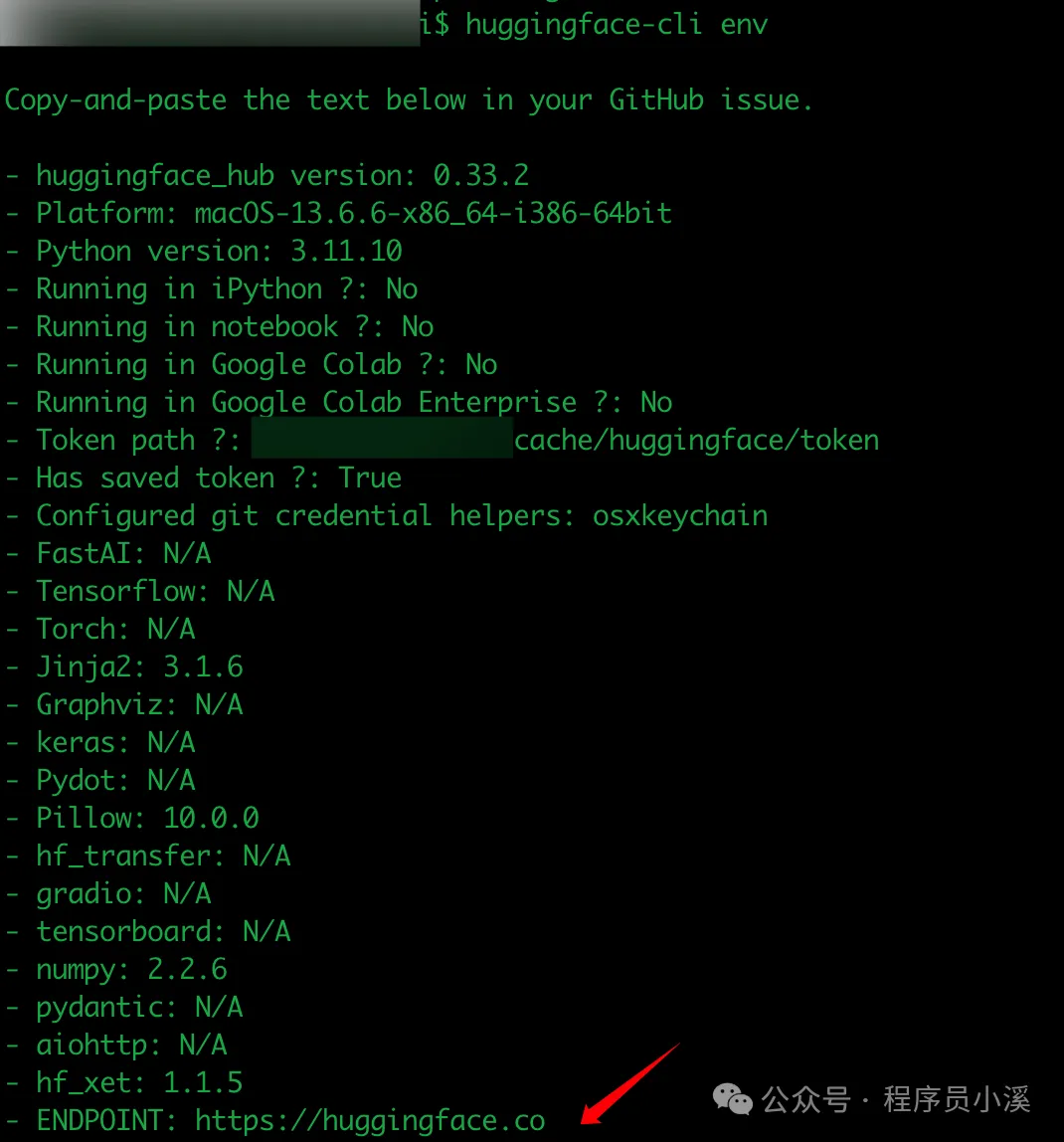
可以看到endpoint默认指向的是Hugging Face,我们可以通过两种方式指定国内镜像。
HF-Mirror官网地址:https://hf-mirror.com
命令行方式
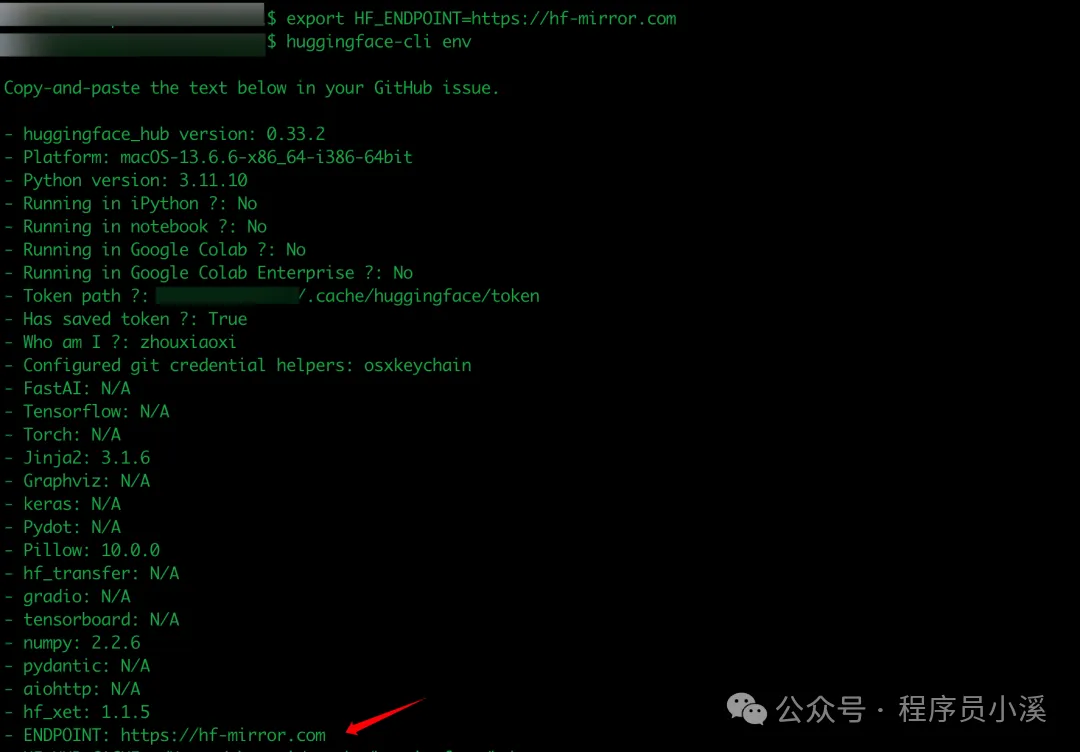
在命令行中直接配置导出环境变量 HF_ENDPOINT 的值
# Linux
$ export HF_ENDPOINT=https://hf-mirror.com
# Windows
$ $env:HF_ENDPOINT = "https://hf-mirror.com"
配置完成后即可看到指定的新镜像地址
代码方式
在Python中直接使用代码设置
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
下载数据集
命令行方式
$ huggingface-cli download hfl/ruozhiba_gpt4 --repo-type dataset --local-dir ./tmp
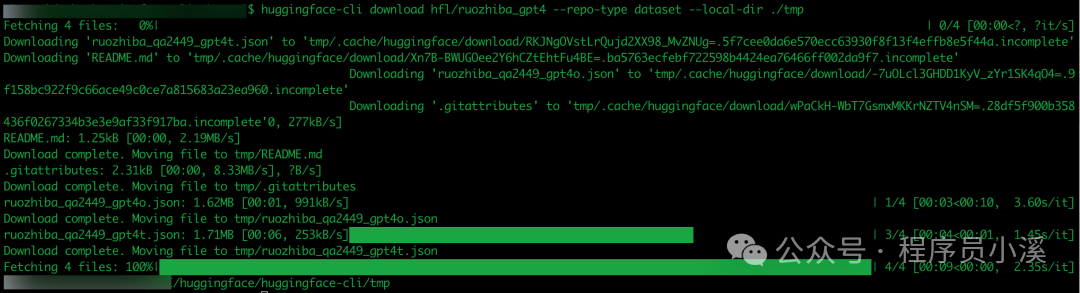
下载完成后即可看到下载的数据集内容
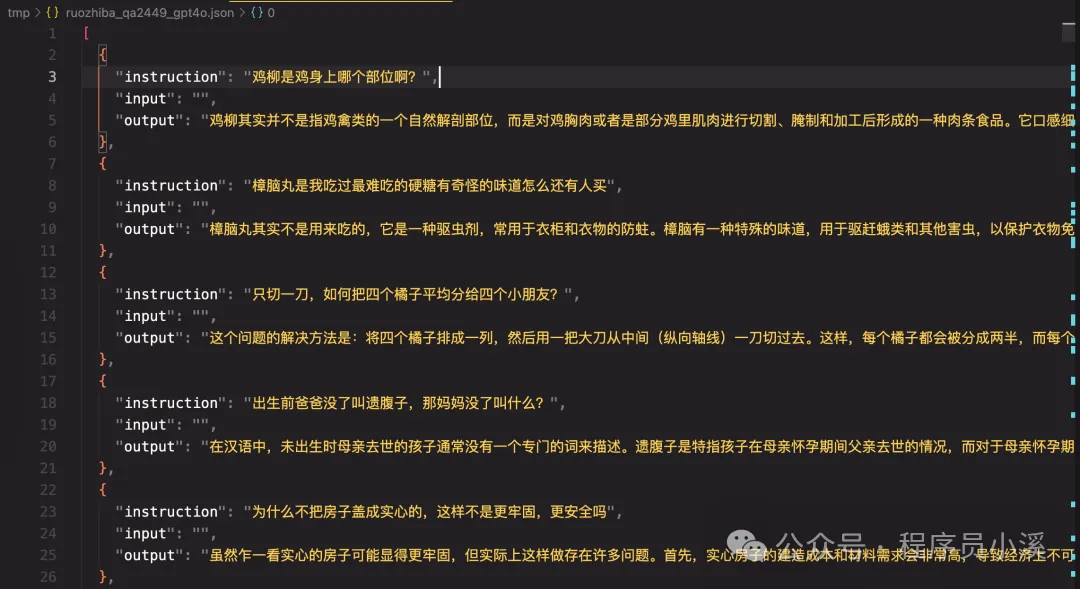
代码方式
安装datasets模块
$ pip install datasets
或者
$ uv add datasets
from datasets import load_dataset
# 下载数据集
dataset = load_dataset("hfl/ruozhiba_gpt4")
print(dataset)
该段代码会执行下载和加载数据集操作,加载完成后打印结果如下:

当前操作数据集存储在缓存目录,如需保存数据集可以使用下面代码
# 保存到本地
dataset.save_to_disk("ruozhiba_gpt4")
下载完成后,我们将得到如下结构的数据集目录

使用数据集
使用远程数据集
加载远程数据集使用了缓存机制,没有下载过会从云上下载到本地,下载完成后加载数据集
from datasets import load_dataset
# 下载数据集
dataset = load_dataset("hfl/ruozhiba_gpt4")
print(dataset)
使用本地数据集
直接从本地数据集文件加载
from datasets import load_from_disk
# 加载本地数据集
dataset = load_from_disk("ruozhiba_gpt4")
print(dataset)
数据集基本操作
查看数据集
from datasets import load_from_disk
# 加载本地数据集
dataset = load_from_disk("ruozhiba_gpt4")
dataset = dataset["train"]
print(dataset)
# 查看数据集样本
print(dataset[0])

数据过滤
数据集数据是十分庞大的,可以通过筛选过滤出满足特定条件的数据
from datasets import load_from_disk
# 加载本地数据集
dataset = load_from_disk("ruozhiba_gpt4")
dataset = dataset["train"]
def f(data):
return data['instruction'][0].startswith('鸡')
new_dataset = dataset.filter(f)
# 遍历
for i in new_dataset:
print(i)
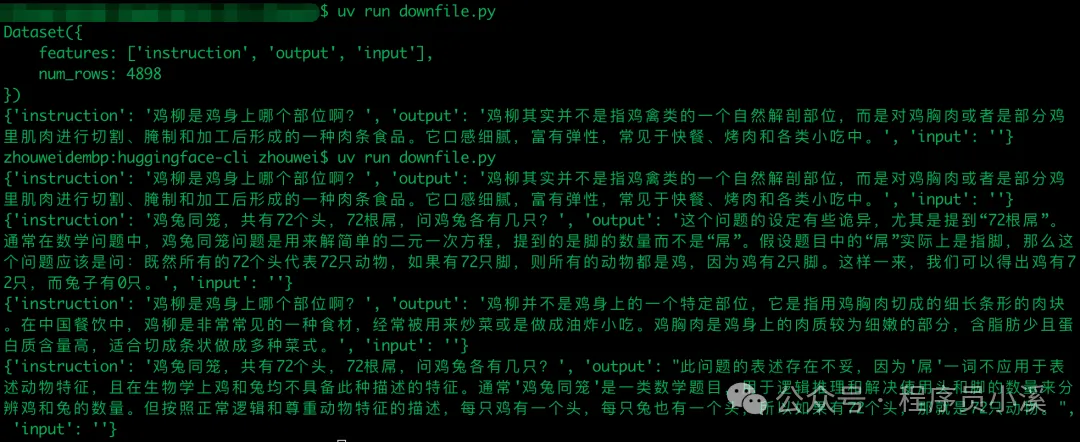
测试集拆分
from datasets import load_from_disk
# 加载本地数据集
dataset = load_from_disk("ruozhiba_gpt4")
dataset = dataset["train"]
# 数据集拆分, 拆分后将会返回一个字典, 字典中包含训练集和测试集
test_dataset = dataset.train_test_split(test_size=0.1)
print(dataset)
print("======= 拆分后的训练集 ========")
print(test_dataset)
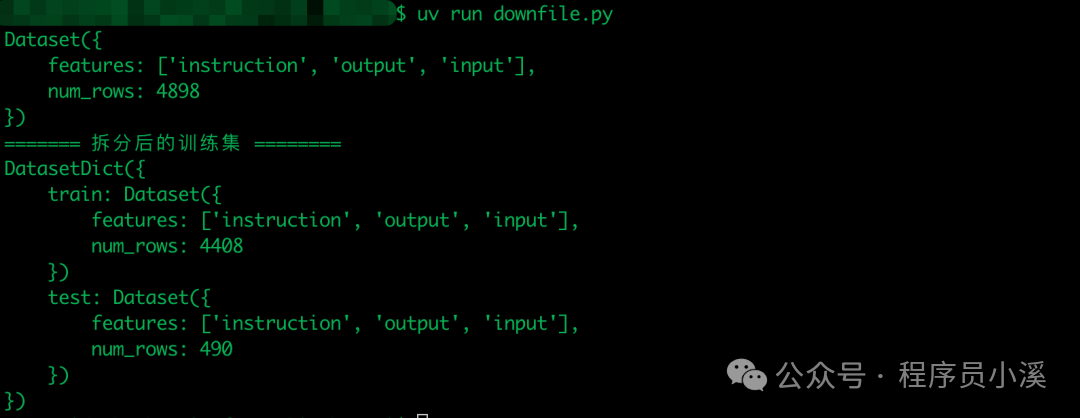
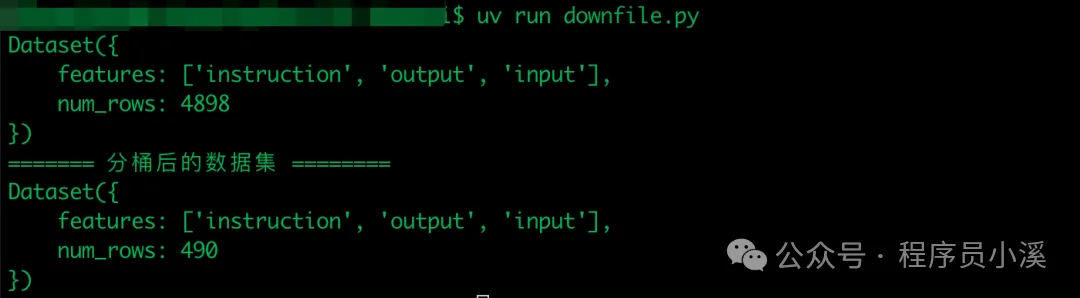
数据分桶
有时我们想将数据分成几份处理,可以使用到这里数据分桶
from datasets import load_from_disk
# 加载本地数据集
dataset = load_from_disk("ruozhiba_gpt4")
dataset = dataset["train"]
# 数据分桶处理, 将数据集分成10个桶,每个桶包含10%的数据
dataset_bucket = dataset.shard(num_shards=10, index=0)
print(dataset)
print("======= 分桶后的数据集 ========")
print(dataset_bucket)
数据格式设定
from datasets import load_from_disk
# 加载本地数据集
dataset = load_from_disk("ruozhiba_gpt4")
dataset = dataset["train"]
# 将数据集转换为, 常用的数据集格式有 torch, numpy, pandas, tensorflow等
# 默认情况下,数据集的格式为 pandas
dataset.set_format(type="numpy", columns=["instruction"], output_all_columns=True)
print(dataset[0])
print("======= 转换的训练集 ========")
print(dataset[0])
暂未用到其他场景,用到再补充
友情提示
见原文:【Hugging Face】Hugging Face数据集的基本使用【Hugging Face】Hugging Face数据集的基本使用

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)