【预训练语言模型】ERNIE1.0: Enhanced Representation through Knowledge Integration
主要讲解百度提出的ERNIE模型,基于知识增强的预训练语言模型
·
【预训练语言模型】ERNIE1.0: Enhanced Representation through Knowledge Integration
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | ERNIE1.0 |
| 2 | 发表位置 | - |
| 3 | 所属领域 | 自然语言处理、预训练语言模型 |
| 4 | 研究内容 | 知识增强的预训练语言模型 |
| 5 | 核心内容 | BERT改进 |
| 6 | GitHub源码 | https://github.com/PaddlePaddle/ERNIE |
| 7 | 论文PDF | https://arxiv.org/pdf/1904.09223 |
一、动机
- 先前的大部分工作只使用了文本来预测missing word,忽略了文本自身的先验信息,例如文本中的实体;
- 除了传统的single toke masking,对整个entity(multi tokens word或phrase)进行mask,在训练时则可以捕捉实体的语义信息;
二、方法
2.1 Transformer
选择多层Transformer作为基础模型,使用WordPiece进行分词,并获得token、segment和position embedding。
2.2 Knowledge Integration
并非将实体knowledge embedding融合到context word embedding(ERNIE-TsingHua版本),而是借助先验知识改进masking策略。
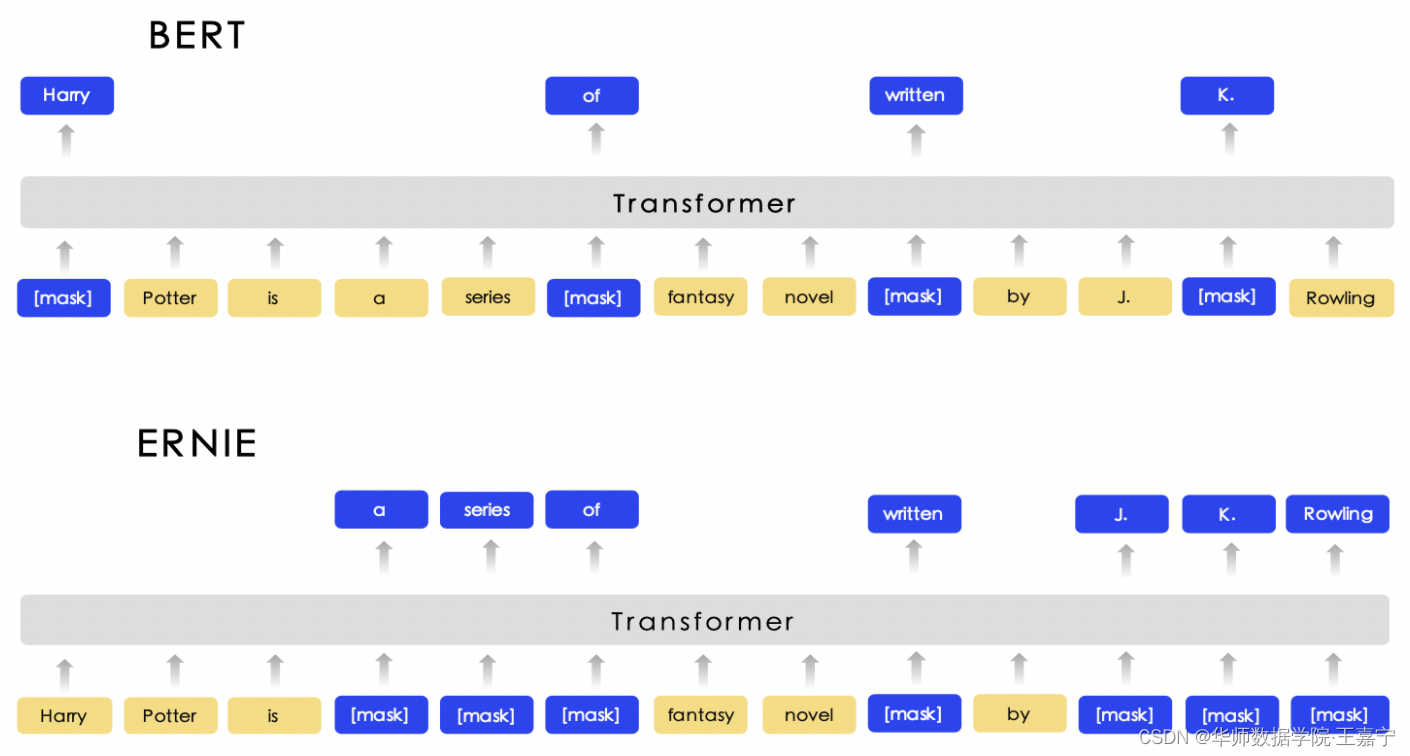
提出三种不同的Masking策略,如下图所示:
- Basic-level Masking:采用最基础的masking策略,不论文英文还是中文,以single token作为mask对象;
- Entity-level Masking:实体包含person、location和organization等;
- Phrase-level Masking:例如词法分析和chunking工具获得一个句子的所有phrase,使用dependent segmentation工具获得word、phrase的属性信息。
在训练时,依然使用word piece进行分词,但选择不同的masking策略。对于mask的token,训练让模型预测正确的token。
如下图所示,可以直观地看出ERNIE与传统BERT的区别:
三、实验
实验设置:
● 数据:选择多个不同的语料,包括中文Wikipedia、百度百科、百度贴吧和百度新闻等;
● 模型:与BERT-base完全相同;
实验任务:
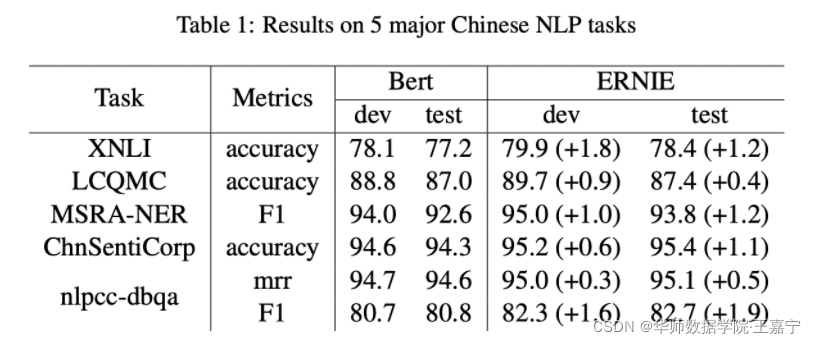
● NLI:XNLI;
● 语义相似度:LCQMC;
● 实体识别:MSRA-NER;
● 情感分析:ChnSentiCorp;
● 检索式问答:NLPCC-DBQA
实验结果
不同的Masking策略对比:
取10%的训练数据进行pre-train,并在XNLI任务验证集和测试集上进行测试:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)