语言模型
NLP语言模型NLP语言模型包括概率语言模型和神经网络语言模型统计语言模型:N-gram神经网络语言模型:word2vec,fasText,GloveN-gram基于概率的判别模型,输入为一句话输出为这句话的概率,即单词的联合概率特点:某个词的出现依赖于其他若干个词,获得的信息越多预测越准确。n-gram本身是指一个由n个单词组成的集合,各单词之间有先后顺序且不要求单词...
NLP语言模型
NLP语言模型包括概率语言模型和神经网络语言模型
统计语言模型:N-gram
神经网络语言模型:word2vec,fasText,Glove
N-gram
基于概率的判别模型,输入为一句话输出为这句话的概率,即单词的联合概率
特点:某个词的出现依赖于其他若干个词,获得的信息越多预测越准确。
n-gram本身是指一个由n个单词组成的集合,各单词之间有先后顺序且不要求单词之间互不相同,一般有Bi-gram和Tri-gram
n-gram中的概率计算:假设我们有一个由n个词组成的句子S=(w1,w2,⋯,wn)如何衡量它的概率呢?我们假设每个单词wi都要依赖从第一个单词w1到前一个单词wi-1的影响。
p(S)=p(w1w2⋯wn)=p(w1)p(w2∣w1)⋯p(wn∣wn−1⋯w2w1)
这个衡量方法的两个弊端
-
会造成参数过大
-
数据稀疏严重。
针对参数过大我们引入马尔科夫假设:一个词的出现只与他之前的若干个词相关
![]()
如果一个词的出现仅依赖于它前面出现的一个词那么我们就称他为Bi-gram:
![]()
- 如果一个词的出现仅依赖于他前面的两个词,那我们就称之为Tri-gram:
![]()
现实中一般二元(N=2)模型或三元模型(N=3)就够了
计算其中每一项的条件概率我们采用极大似然估计MLE(Maximum Likelihood Estimation):
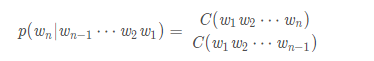
c为该词在语料中出现的频率
N-gram中的数据平滑问题
n-gram最大的问题就是稀疏问题(Sparsity)例如,在bi-gram中,若词库中有20k个词,那么两两组合就有近2亿个组合。其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的
-
使所有的N-gram概率之和为1
-
使所有的n-gram概率都不为0
-
它的本质,是重新分配整个概率空间,使已经出现过的n-gram的概率降低,补充给未曾出现过的n-gram。
参考链接:https://blog.csdn.net/songbinxu/article/details/80209197
word2vec
词向量的表示有one-hot与distribute Representation两种
distribute Representation的思想:
-
通过训练某种语言中的每一个词映射成一个用固定长度的短向量,所有这些向量构成一个向量空间,而每个向量视为该向量空间中的一个点
-
在空间中引入距离,可以根据距离判断它们之间的相似性
word2vec为神经网络语言模型的一种,应用distribute Representation的向量表示,有两套框架Hierarchical Softmax与Negative Sampling,word2vec有两个模型CBOW和Skip-gram
-
CBOW思想为通过已知上下文词来预测中心词
-
Skip-gram思想为通过已知词来预测周边上下文词
Hierarchical Softmax
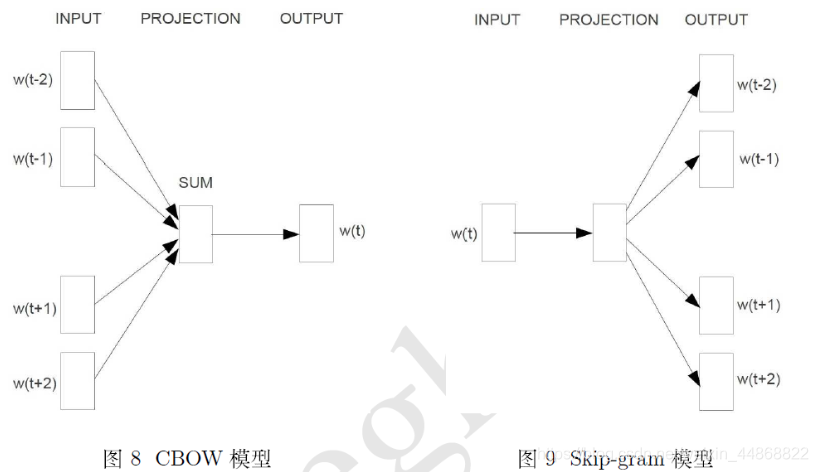
CBOW模型分为输入层、投影层、和输出层
-
输入层为已知的上下文词向量
-
投影层则将输入的上下文的词向量累加为一个长向量
-
输出层对应一个huffman树(层次softmax)
构建huffman树:
-
以预料中出现的词当作叶子节点
-
以各词在预料中出现的次数当权值
梯度下降进行参数学习
小结:对于字典中任意词w,huffman树中必定存在一条从根节点到词w对应结点的路径,存在路径的分支将每个分支看作一次二分类,每次分类就产生一个概率将所有概率连乘就得到了最终的预测概率然后进行梯度下降来学习参数。
Skip-gram与CBOW的方法大同小异。
Negative Sampling
不再使用huffman树而是采用随机负采样的方法大幅提升了性能
负采样的算法
给定中心词w为正样本则其它词为负样本。
流程:

形成一个长度为1的非等距的抛分节点为N个,再引入一个[0,1]上的等距抛分节点为M个(M>>N)形成如下图:
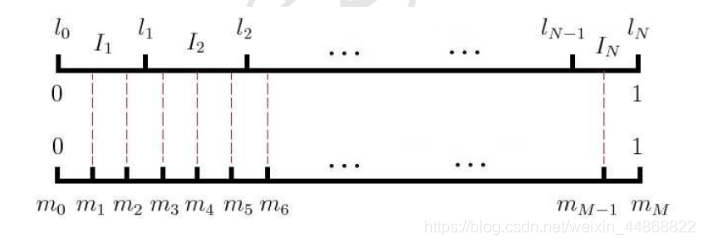
由此形成一个映射关系:
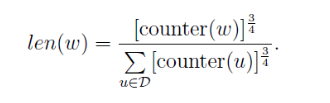
有了此映射关系后采样时每次生成一个[1,m-1]的一个随机数i,则table(i)就为一个样本,当对w进行采样时遇到w则直接跳过。word2vec的源码中词的权值设置为:
经过采样后的出类似LR的而分类优化目标,再对优化目标进行梯度上升进行参数的学习
参考链接:https://blog.csdn.net/u014038273/article/details/79859704
Fastext
fast为词向量和文本分类工具,包括三部分:模型架构、层次softmax、n-gram特征。与word2vec的CBOW模型类似为word2vec衍生出来的。
-
CBOW的架构:输入的是个词,经过隐藏层后,输出的是x_1,x_2,...,x_{N-1},x_N表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
-
层次softmax:fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
-
n-gram特征:fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
Fastext与word2vec的区别
-
相似处:
-
图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
-
都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
-
不同处:
-
模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用。
-
模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容。
-
两者本质的不同,体现在 h-softmax的使用:
-
Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax也会生成一系列的向量,但最终都被抛弃,不会使用。
-
fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)