Y2周:使用YOLOv5训练自己的数据集
1.会出现很多报错,首先是:module ‘PIL.Image‘ has no attribute ‘ANTIALIAS‘,解决:进入相应的.py文件中,将Image.ANTIALIAS改为Image.LANCZOS。2.其次是:AttributeError: ‘NoneType‘ object has no attribute ‘_free_weak_ref‘,解决:降级torch版本。具体版本
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、环境准备:
因为高版本的pytorch可能会出现报错(并不影响运行)、因此重新布置cuda和torch的环境
python=3.8.0
torch==1.10.0+cu113
torchvision==0.11.1+cu113
二、准备自己的数据集
这里使用的是kaggle上面的水果检测数据集,如果有需要的可以自行搜索进行下载。
下载图片后,设置好目录结构。
- 主目录
- fruitdata(自己创建一个文件夹,将数据放到这里)
- Annotations(放置我们的.xml文件)
- images(放置图片文件)
- lmageSets
- Main(会在该文件夹内自动生成 train.txt、val.txt、test.txt 和 trainval.txt 四个文件存放训练集、验证集、测试集图片的名字)
目录结构如图所示:
Annotations文件夹为xml文件,我的文件如下:
images 文件夹:
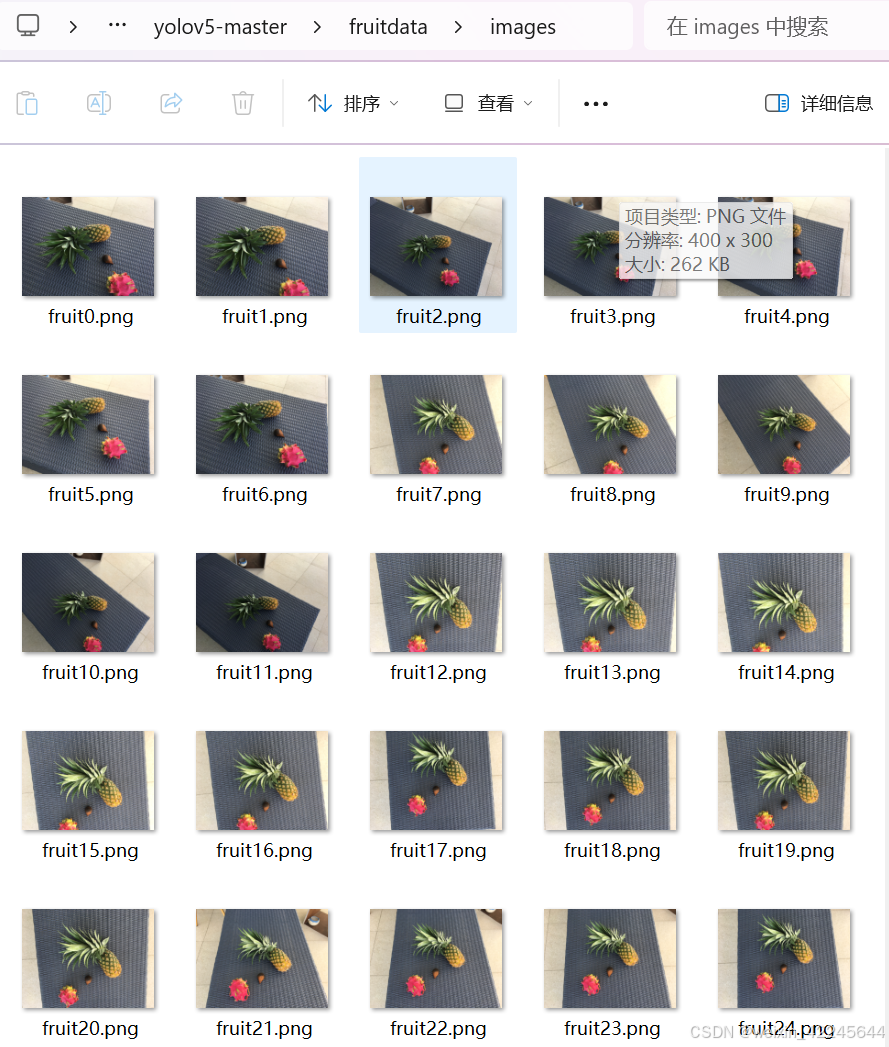
我images文件位.png格式,官方的为.jpg,不过问题不大后面改一下代码即可。
三、将数据集进行分割
#导入必要的库
import os
import random
import argparse
#创建一个参数解析器
parser = argparse.ArgumentParser()
# 添加命令行参数,用于指定XML文件的路径,默认为'Annotations'文件夹
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
# 添加命令行参数,用于指定输出txt标签文件的路径,默认为'ImageSets/Main'文件夹
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
# 解析命令行参数
opt = parser.parse_args()
#定义训练验证集和测试集的划分比例
trainval_percent = 0.9 # 使用全部数据
train_percent = 8/9 # 训练集占训练验证集的90%
# 设置XML文件夹的路径,根据命令行参数指定
xmlfilepath =opt.xml_path
# 设置输出txt标签文件的路径,根据命令行参数指定
txtsavepath =opt.txt_path
# 获取XML文件夹中的所有XML文件列表
total_xml =os.listdir(xmlfilepath)
# 如果输出txt标签文件的文件夹不存在,创建它
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
# 获取XML文件的总数
num = len(total_xml)
# 创建一个包含所有XML文件索引的列表
list_index= range(num)
# 计算训练验证集的数量
tv = int(num *trainval_percent)
#计算训练集的数量
tr =int(tv*train_percent)
# 从所有XML文件索引中随机选择出训练验证集的索引
trainval=random.sample(list_index, tv)
# 从训练验证集的索引中随机选择出训练集的索引
train =random.sample(trainval, tr)
# 打开要写入的训练验证集、测试集、训练集、验证集的txt文件
file_trainval =open(txtsavepath +'/trainval.txt', 'w')
file_test =open(txtsavepath +'/test.txt', 'w')
file_train =open(txtsavepath +'/train.txt', 'w')
file_val =open(txtsavepath +'/val.txt', 'w')
# 遍历所有XML文件的索引
for i in list_index:
name =total_xml[i][:-4]+'\n' # 获取XML文件的名称(去掉后缀.xm1),并添加换行符
#如果该索引在训练验证集中
if i in trainval:
file_trainval.write(name) # 写入训练验证集txt文件
if i in train: #如果该索引在训练集中
file_train.write(name) # 写入训练集txt文件
else:
file_val.write(name) # 否则写入验证集txt文件
else:
file_test.write(name) # 否则写入测试集txt文件
#关闭所有打开的文件
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()运行成功后,Main文件夹下面会出现4个txt文件,将整个图片数据集分为训练集:验证集:测试集=8:1:1
四、生成 train.txt、test.txt、val.txt 文件以及labels文件(这三个文件在fruitdata文件夹下)
这几个txt文件包含的是xml文件中的标注信息。相当于把xml格式转化为txt格式。
# -*- coding:utf-8 -*-
# 导入必要的库
import xml.etree.ElementTree as ET
import os
from os import getcwd
# 定义数据集的名称
sets = ['train', 'val', 'test']
# 定义类别列表,这里有两个类别,可以根据需要添加更多类别
classes = ["pineapple", "snake fruit", "dragon fruit", "banana"] # 请根据您的数据集修改这些类别名称
# 获取当前工作目录的绝对路径
abs_path = os.getcwd()
print(abs_path)
# 定义一个函数,将边界框的坐标从绝对值转换为相对于图像大小的比例
def convert(size, box):
dw = 1. / (size[0]) # 计算图像宽度的倒数
dh = 1. / (size[1]) # 计算图像高度的倒数
x = (box[0] + box[1])/2.0-1 # 计算中心点的x坐标
y = (box[2] + box[3])/2.0-1 # 计算中心点的y坐标
w = box[1] - box[0] # 计算边界框的宽度
h = box[3] - box[2] # 计算边界框的高度
x = x*dw # 缩放x坐标
w = w*dw # 缩放宽度
y = y*dh # 缩放y坐标
h = h*dh # 缩放高度
return x, y, w, h
# 定义一个函数,将标注文件从XML格式转换为YOLO格式
def convert_annotation(image_id):
in_file = open('./Annotations/%s.xml' % (image_id) ,encoding='UTF-8') #打开XML标注文件
out_file = open('./labels/%s.txt' % (image_id) ,'w') # 打开要写入的YOLO格式标签文件
tree = ET.parse(in_file) # 解析XML文件
root = tree.getroot()
filename = root.find('filename').text # 获取图像文件名
filenameFormat = filename.split(".")[1] # 获取文件格式
size = root.find('size') # 获取图像尺寸信息
w = int(size.find('width').text) # 获取图像宽度
h = int(size.find('height').text) # 获取图像高度
for obj in root.iter('object'):
difficult = obj.find('difficult').text # 获取对象的难度标志
cls = obj.find('name').text # 获取对象的类别名称
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls) # 获取类别的索引
xmlbox = obj.find('bndbox') # 获取边界框坐标信息
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b) # 调用convert函数,将边界框坐标转换为YOLO格式
out_file.write(str(cls_id)+" "+" ".join([str(a)for a in bb])+'\n') # 写入YOLO格式标签文件
return filenameFormat
# 获取当前工作目录
wd = getcwd()
# 遍历每个数据集(train、val、test)
for image_set in sets:
# 如果labels目录不存在,创建它
if not os.path.exists('./labels/'):
os.makedirs('./labels/')
# 从数据集文件中获取图像ID列表
image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split() # 打开要写入的文件,写入图像的文件路径和格式
list_file = open('./%s.txt' % (image_set),'w')
for image_id in image_ids:
filenameFormat =convert_annotation(image_id)
list_file.write(abs_path +'/images/%s.%s\n' % (image_id, filenameFormat)) # 注意你的图片格式,如果是.jpg记得修改
list_file.close()转换后,会生成上述所示的三个文件,以及labels文件,里面包含的是类别、中心点坐标、长度和宽度数据。
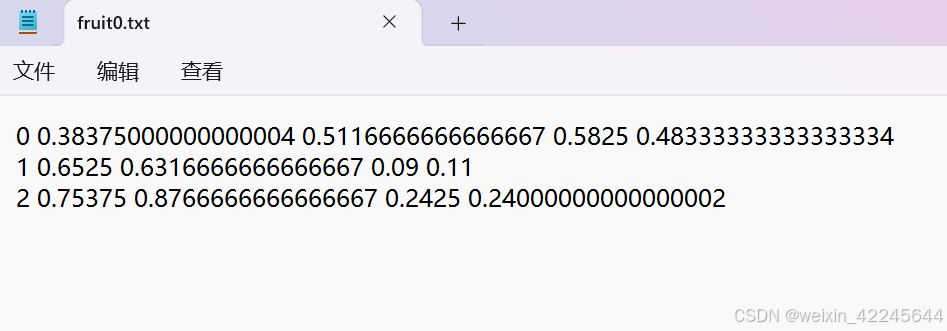
五、创建fruit.yaml和fruit.yaml文件(分别在data和models文件夹下)
两个文件分别为:
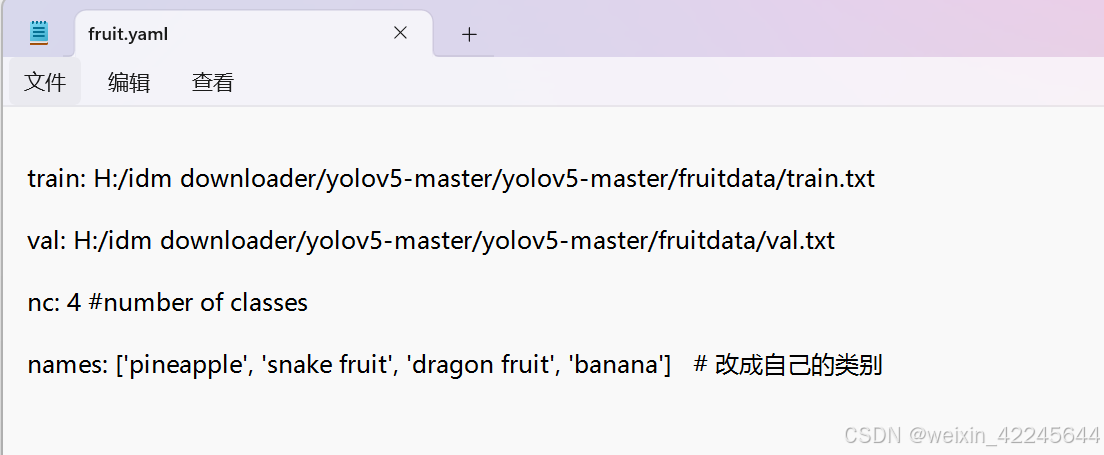
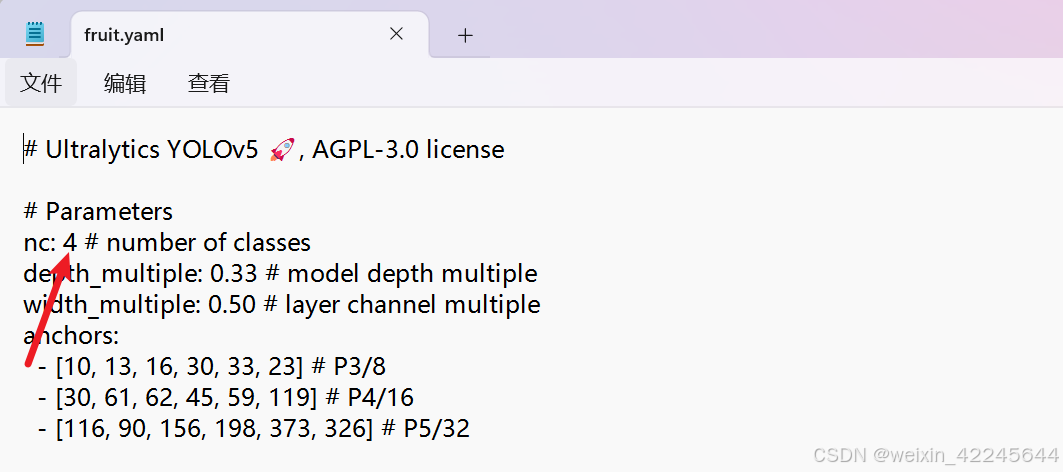
六、开始用模型训练自己的数据集
在终端输入命令:python train.py --img 900 --batch 2 --epoch 100 --data data/fruit.yaml --cfg models/fruit.yaml --weights weights/yolov5s.pt
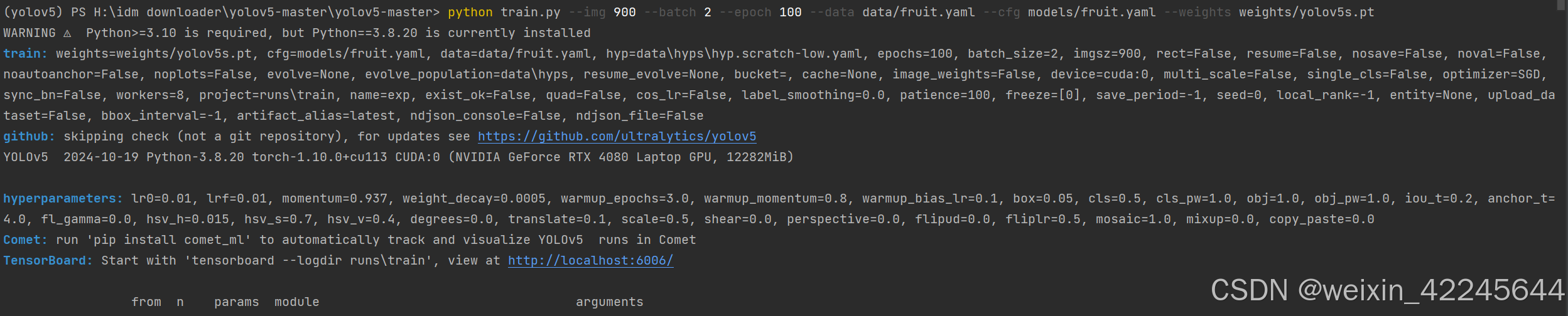
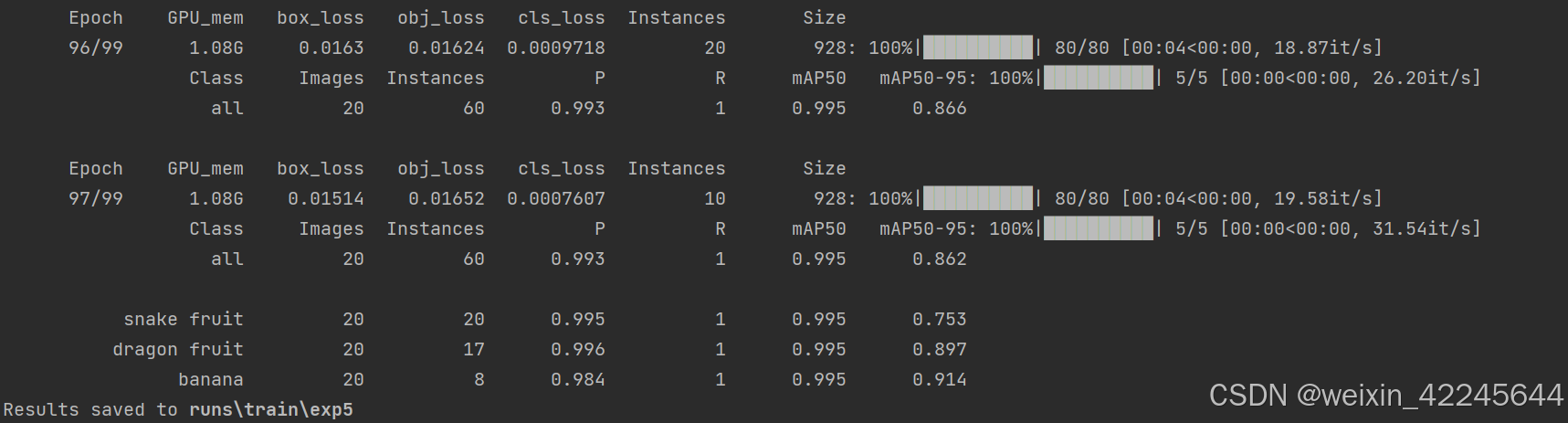
结果会保存在相应的文件夹中。
七、心得总结
1.会出现很多报错,首先是:module ‘PIL.Image‘ has no attribute ‘ANTIALIAS‘,解决:进入相应的.py文件中,将Image.ANTIALIAS改为Image.LANCZOS。
2.其次是:AttributeError: ‘NoneType‘ object has no attribute ‘_free_weak_ref‘,解决:降级torch版本。具体版本可参考一、环境搭建。
3.再次是:
COMET INFO: Using ‘D:\pycharmProject\yolov5-master-6.2\.cometml-runs’ path as offline directory. Pass ‘offline_directory’ parameter into constructor or set the ‘COMET_OFFLINE_DIRECTORY’ environment variable to manually choose where to store offline experiment archives. 解决:卸载comet-ml 输入命令:pip uninstall comet-ml
4.还有xml文件和yolo文件之间的转换。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)