基于预训练语言模型的文本向量检索方法
大语言模型LLM有强大的语义理解和文本生成能力,但仍存在许多挑战。如LLM存在幻觉问题,可能会在没有答案的情况下提供虚假信息;或者提供过时的信息。检索增强生成(Retrieval-Augmented Generation,RAG)通过引入信息检索组件,使得LLM在针对用户问题生成回复之前引用训练数据来源以外的权威知识库。
大语言模型LLM有强大的语义理解和文本生成能力,但仍存在许多挑战。如LLM存在幻觉问题,可能会在没有答案的情况下提供虚假信息;或者提供过时的信息。检索增强生成(Retrieval-Augmented Generation,RAG)通过引入信息检索组件,使得LLM在针对用户问题生成回复之前引用训练数据来源以外的权威知识库。在LLM强大能力的基础上,RAG将LLM扩展为可以访问特定的内部知识库,这不需要重新训练LLM,RAG从内部知识库中获取相关信息,将用户查询和相关信息都提供给LLM,LLM可以使用内部知识库的相关信息来生成更好的响应和回复。
文本检索是RAG的关键组件,文本检索模块会极大影响RAG生成回复的正确率。文本检索指的是对于用户输入的问题,从大量文本构成的知识库中找到最相关的文本。这里的文本可以是不同语义粒度的,可以是句子、段落、文章、甚至是文档。
1多阶段的训练范式
业界的向量模型通常以预训练好的语言模型(如Bert、RoBerta)为基座模型,这里的基座模型不是采用单向注意力机制的GPT式的生成式大语言模型,而是采用双向注意力机制的BERT式的语言模型,在预训练过程中采用了掩码语言模型(MLM,Masked Language Model)作为训练目标。在预训练语言模型基础上,再采用三阶段或者两阶段的训练方法来进一步训练向量模型。
智源研究院提出的BGE模型就采用了三阶段的训练方法:
\1. RetroMAE预训练:在大规模无标注文本语料上,通过RetroMAE方法用一个弱解码器来提升编码器模型编码文本向量的能力,帮助语言模型适配到向量表示和语义匹配任务。
\2. 弱监督对比学习训练:在大规模无标注文本对语料上进行对比学习训练,通过批次内负样本共享和跨设备负样本共享技术,极大增加了每个查询文本对应的负样本数量,帮助向量模型掌握实际场景中不同类型的语义匹配任务。
\3. 有监督对比学习训练:在小规模有标注三元组训练数据上进行对比学习训练,通过添加挖掘的难负样本(hard negative),提升了对比学习的难度,进一步增强向量模型的语义匹配能力。
微软的E5、阿里达摩院的GTE、商汤科技的piccolo则是采用了两阶段的训练方法,即弱监督对比学习和有监督对比学习。
1.1 RetroMAE 预训练
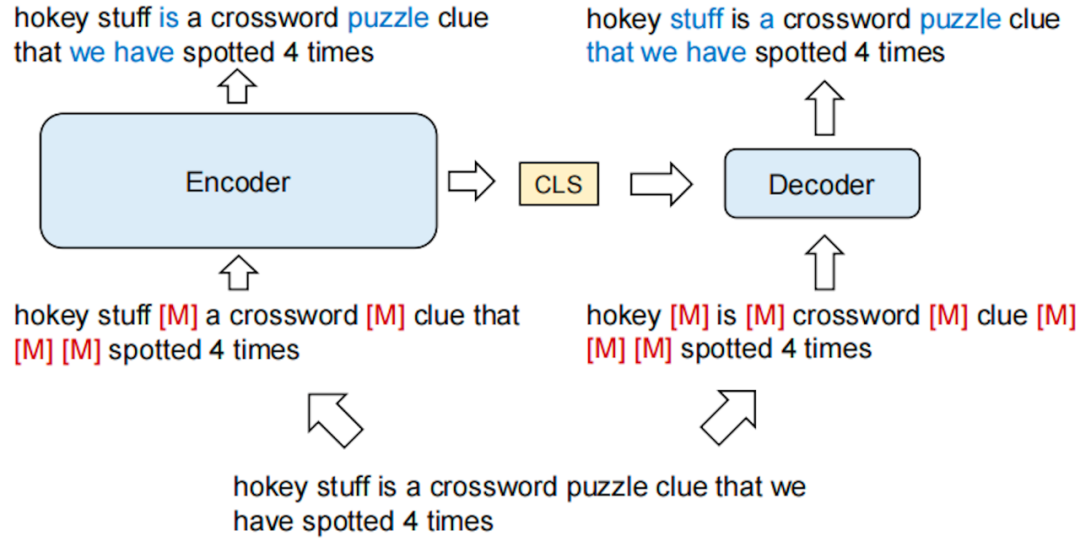
在文本检索任务中,embedding模型将文本的所有信息编码为低维的稠密向量,embedding模型的文本向量表示能力是至关重要的。以MLM训练目标的预训练语言模型专注于表示单个的独立的字符token,而不是表示整个完整的文本。RetroMAE(Retrieval-oriented Masked Auto-Encoder)预训练可以来提升基础模型的文本表示能力。在检索任务中,RetroMAE是最有效的预训练框架,RetroMAE预训练利用解码器重建扰动文本来提升编码器的文本向量表示能力,从而提高向量检索(DPR, dense passage retrieve)的效果。
● RetroMAE使用了“编码器-解码器”框架。
● 对输入文本进行两次不同的随机mask,来分别作为编码器和解码器的输入。
● 将编码器的池化文本向量(sentence embedding)拼接到解码器的输入,来重建原始的输入文本。
在MAE中,使用一个深层的编码器将文本编码为稠密向量,来作为文本向量表示(sentence embedding);使用一个浅层的解码器,基于编码器提供的向量表示,恢复和重建被mask掉的token。为了更好地预测,编码器必须把足够多的文本信息压缩到稠密向量中,由于解码器的能力更弱(1.解码器是浅层的,编码器是深层的;2.解码器采用更大的mask比例,重建难度更大),解码器必须关注到编码器的稠密向量。

深层的编码器

信息通路

弱的解码器

训练损失
在无标注文本语料上进行预训练,RetroMAE的预训练目标综合了encoder和decoder的MLM训练目标。
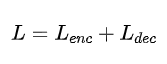
在RetroMAE框架的预训练过程中,编码器和解码器都用到了MLM训练目标。在这个框架中,为了让解码器成功地重建文本,编码器输出句子向量的质量是非常重要的。反过来,解码器重建文本任务也是提升编码器文本表示能力的关键。为了提升解码器重建任务的难度,RetroMAE预训练有两个关键点:
\1. 一个更浅层的解码器,例如编码器使用12层transformer,解码器使用1层transformer。
\2. 一个更大的mask比例,例如编码器采用0.15的mask比例,解码器采用0.3的mask比例。
相比于编码器模型,解码器层数更少,模型结构更简单,建模能力弱。另外,解码阶段的掩码比例也更高,解码器想要重建和恢复被扰动的文本是非常有难度的。这使得解码器要想恢复和重建被扰动的文本,必须关注到编码器输出的稠密句子向量,编码器模型必须捕捉到足够多输入文本的语义信息,并输出足够好的稠密句子向量,解码器才能恢复和重建扰动文本。
1.2 弱监督对比学习
对比学习指的是从其他不相关的负样本文本中识别和区分出相关的正样本文本。正样本对是相似或相关的文本对,而负样本对是不相似或不相关的文本对。对比学习的基本思想是将相关的样本(正样本)拉近,将不相关的样本(负样本)推远。对比学习的每条训练数据是一个三元组,(查询文本,正样本文档文本,负样本文档文本列表)。每个查询文本(query)对应一个正样本文档文本,对应多个负样本文档文本。下面给出了一条训练数据样例。

弱监督对比学习在大规模无标注文本对语料上进行训练。弱监督对比学习阶段使用无监督文本对作为训练数据,训练数据规模通常可以达到上亿条,阿里达摩院的GTE在弱监督阶段用了8亿条文本对数据,商汤科技的piccolo在弱监督阶段用到了4亿条文本对数据。
弱监督对比学习阶段通过批次内负采样和跨设备负样本共享技术,极大增加了每个查询文本对应的负样本数量,帮助向量模型掌握实际场景中不同类型的语义匹配任务。
● 批次内负采样(In-batch Negatives)技术指的是,在同一个训练批次内,采样其他数据来作为负样本。
● 跨设备负样本共享(cross-device negatives sharing method)技术指的是,在使用多张GPU进行数据并行训练时,通过GPU间通信在不同的GPU之间共享负样本的方法,目的是大大扩充负样本的数量。
更具体地,假设使用24长A100的GPU进行对比学习训练,单卡batch_size为1024,group_size为2,则每个查询文本query在批次中有49151(gpu_num batch_size group_size - 1)个负样本。
我们知道transformer模型训练的计算量和耗时与序列长度的二次方成正比,由于弱监督对比学习阶段的训练数据规模很大,弱监督阶段训练模型一般不需要太大的最大序列长度,一般是将最大序列长度限制在128。通过采用128这样比较小的最大序列长度,一方面可以加快训练速度,从而适应大规模训练数据;另一方面,通过减小序列长度,可以节省显存占用,从而增大batch_size,这样就可以增大训练批次中每个查询文本的负样本数量。
为了节省显存来增大训练批次中每个查询文本的负样本数量,除了将最大序列长度限制在128,通常还会采用激活检查点、混合精度训练、零冗余优化器ZeRO等技术来节省显存。
1.3 有监督对比学习
有监督对比学习在小规模有标注三元组训练数据上进行训练。有监督对比学习阶段使用有标注的高质量文本对,并且通过添加挖掘的难负样本(hard negative),提升了对比学习的难度,进一步增强向量模型的语义匹配能力。
添加挖掘的难负样本是提升向量检索效果的有效方法之一。通常可以采用BM25或现有其他的向量模型来从语料库中为查询文本挖掘难负样本。相比弱监督阶段,在有监督对比学习阶段,需要将最大序列长度从128增大到512(甚至更大长度),来适应更大长度的输入文本。另外,将group_size增大到8或16,在训练中使用更多的难负样本。
2稠密检索模型
稠密文本检索(Dense Text Retrieval)的本质是在稠密潜在语义空间中学习文本的向量表征,建模查询文本(query)和文档文本(passage)之间的语义关联和语义交互,从而计算和衡量查询文本与文档文本之间的相关性分数。基于不同的交互建模方法,稠密检索主要有两种不同的结构:双编码器(Bi-Encoder)和交叉编码器(Cross-Encoder)。
2.1 双编码器
双编码器(Bi-Encoder)独立地将查询文本和文档文本编码为稠密向量表示,而不是将它们作为一对输入。具体地,双编码器采用双塔结构,分别用两个独立的编码器来学习查询文本和文档文本的潜在语义表征,也就是查询向量和文档向量;再基于这两个向量来计算相关性分数,通过计算查询向量和文档向量之间的相关性函数(点积/余弦相似度)来得到查询文本和文档文本之间的相关性分数。双编码器结构中可以使用两个独立的编码器,也可以共享同一个编码器来编码查询文本和文档文本。业界更普遍的情况是通过共享同一个编码器来分别编码查询文本和文档文本。
以预训练语言模型为基座模型,例如可以采用预训练好的BERT模型作为基座模型,采用对比学习(Contrastive Learning)的方法来训练双编码器。
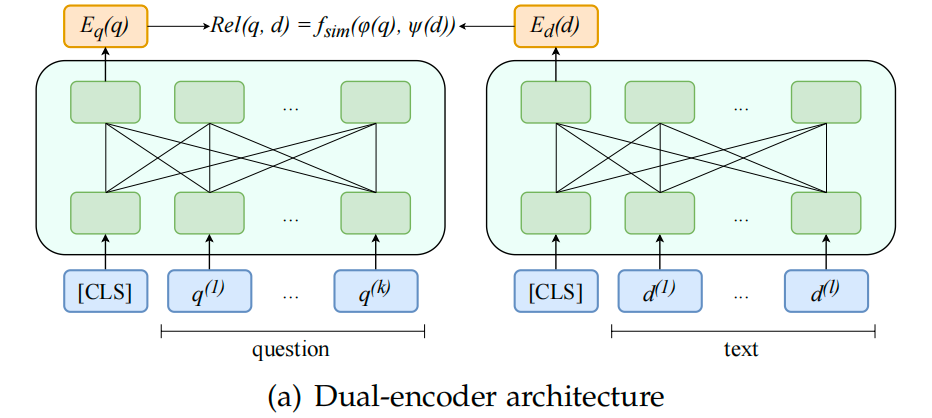

在训练过程中,通过最小化对比学习的损失函数来更新双编码器的模型参数,使得正样本的相似度尽可能高,负样本的相似度尽可能低。
双编码器结构的优点是在大规模文本检索任务中非常有效,计算效率高,耗时短。在文本检索场景中,语料库中通常有大量的文档文本,由于双编码器可以对查询文本和文档文本进行独立编码,因此双编码器可以预先编码和计算好语料库中大量文档文本的向量表示,在文本检索时,只需要计算查询文本的向量表示就可以了。
双编码器的缺点是无法捕捉查询文本和文档文本之间的微妙关联,从而导致文本检索的性能效果比较差。双编码器独立地编码查询文本和文档文本,无法捕捉这两个序列文本之间细粒度的语义交互,导致较低的性能。
2.2 交叉编码器
交叉编码器(Cross-Encoder)将查询文本和文档文本作为一个文本对,将查询文本和文档文本拼接起来,当作是一个完整的句子输入给编码器。具体地,交叉编码器用一个特殊分隔符“sep”将查询文本和文档文本拼接起来,为了获得整个拼接句子的向量表征,还要在拼接句子的开头插入一个特殊符号“cls”。接着将拼接起来的句子作为编码器模型的输入,交叉编码器模型可以细粒度地建模拼接句子中任意两个词汇之间的语义交互。一个通常的做法是将特殊符号“cls”对应的向量表示作为两个文本序列之间的语义匹配向量表示。
以预训练语言模型为基座模型,采用对比学习(Contrastive Learning)的方法来训练交叉编码器。
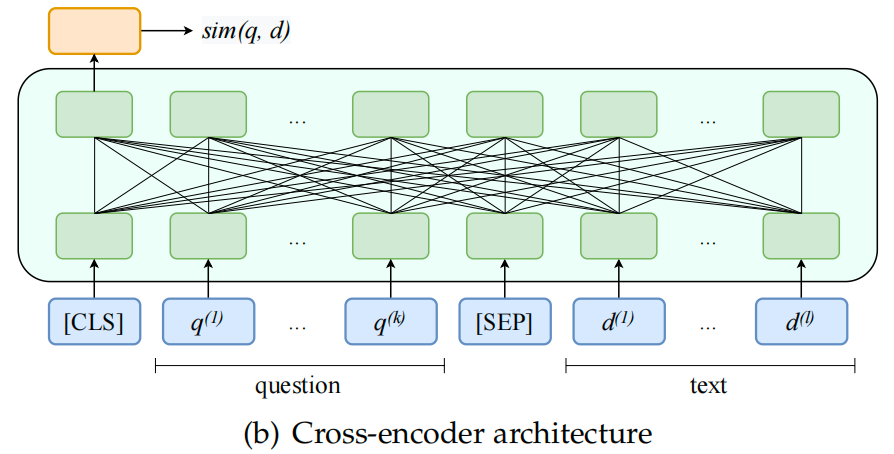

在训练过程中,通过最小化对比学习的损失函数来更新交叉编码器的模型参数,使得正样本的相似度尽可能高,负样本的相似度尽可能低。
交叉编码器的优点是文本检索的效果更好,准确性更高。交叉编码器将查询文本和文档文本作为一个文本对进行编码,可以捕捉到两个文本序列之间细粒度的语义交互,可以有效捕捉到查询文本和文档文本之间微妙的语义关联,从而在文本检索任务上有着更好的效果,更高的性能。
交叉编码器的缺点是需要对每一对查询文本和文档文本进行编码,无法预先编码和处理大量的文档文本,在文本检索任务中,交叉编码器的推理速度慢,推断耗时长。
2.3 两阶段检索
上面介绍了双编码器和交叉编码器各自的优缺点,为了更好地平衡检索效率和检索效果,可以采用“召回+精排”两阶段的方法。具体地,先用双编码器作为embedding模型进行召回,再用交叉编码器作为reranker模型进行排序,这样可以充分发挥双编码器和交叉编码器各自的优势,在保证检索效率的情况下获得更好的检索效果。
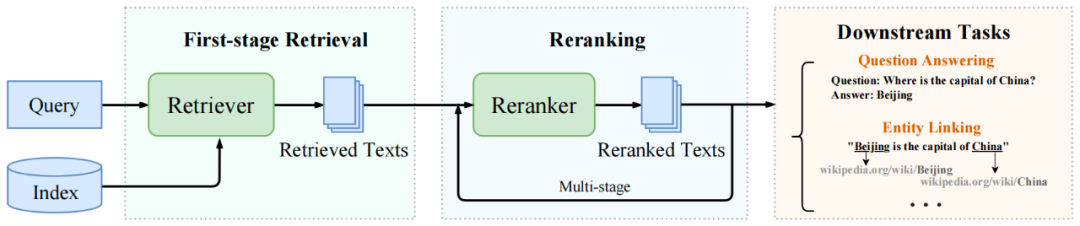
召回阶段。将双编码器作为embedding模型,在文本检索场景中,语料库中通常有大量的文档文本,由于双编码器可以对查询文本和文档文本进行独立编码,因此双编码器可以预先编码和计算好语料库中大量文档文本的向量表示,构建好向量库。在用户输入查询文本,进行检索时,只需要计算查询文本的查询向量,就可以从向量库中进行检索回最相关的top K个文档。虽然双编码器的检索效率高,但无法捕捉查询文本和文档文本之间的微妙关联,从而导致文本检索的性能效果比较差。
精排阶段。将交叉编码器作为reranker模型,对召回的top K个文档进行精排序。交叉编码器将查询文本和文档文本作为一个文本对进行编码,可以捕捉到两个文本序列之间细粒度的语义交互,可以有效捕捉到查询文本和文档文本之间微妙的语义关联,从而在文本检索任务上有着更好的效果。
3知识蒸馏提升双编码器
人工标注得到的高质量文本对数据是有限的,知识蒸馏是一种提升双编码器模型性能的重要方法。在机器学习领域中,知识蒸馏指的是把知识从性能更好更强的模型(教师模型)迁移到性能更差更弱的模型(学生模型)的过程。在向量检索的场景中,知识蒸馏的目标是在给定的有标注数据上,用性能更强的模型(教师模型)来提升标准双编码器模型(学生模型)的效果。
在稠密向量检索的场景中,双编码器独立地编码查询文本和文档文本,无法捕捉这两个序列文本之间细粒度的语义交互,文本检索效果比较差。交叉编码器将查询文本和文档文本作为一个文本对进行编码,可以有效捕捉到查询文本和文档文本之间微妙的语义关联,从而在文本检索任务上有着更好的效果。
将性能更强检索效果更好的交叉编码器作为教师模型,将性能更弱检索效果更差的双编码器作为学生模型,通过知识蒸馏的方法,把语义匹配知识从性能更强的交叉编码器迁移到性能更差的双编码器,从而来提升双编码器的文本检索效果。
一般来说,教师模型的训练是独立于学生模型的训练的。教师模型不一定要是交叉编码器,任何比学生模型效果好的模型都可以作为教师模型。例如可以用效果更好的深层双编码器作为教师模型进行知识蒸馏,来提升浅层双编码器模型的效果。


在知识蒸馏时,通过最小化KL散度损失函数来更新双编码器的模型参数,从而将语义匹配知识从性能更强的交叉编码器迁移到性能更差的双编码器,来提升双编码器的文本检索效果。
4稠密检索对比稀疏检索
稠密检索(Dense Retrieval)和稀疏检索(Sparse Retrieval)是两种常见的文本检索方法,它们在信息检索中都有广泛应用。
1. 稀疏检索
稀疏检索是一种基于词汇匹配(lexical matching)或关键词匹配的检索方法。它使用简单的词频统计(如TF-IDF)来衡量文档与查询之间的相关性。在稀疏检索中,检索空间由文档和查询中的词组成,因此被称为“稀疏”。
稀疏检索的优点是擅长处理字符串精确匹配,尤其是query与正确答案之间的重叠词汇比较多时,这种情况下稀疏检索的效果更好。另外,稀疏检索的计算简单、速度快。
稀疏检索的缺点是无法捕捉语义相似性。由于稀疏检索主要依赖词汇匹配,它在捕捉同义词、词义相近的词汇以及不同表达方式的语义相似性方面有局限性。
2. 稠密检索
稠密检索是一种基于向量表示和语义匹配(semantic matching)的检索方法。它使用深度学习模型(如BERT、GPT等)将文档和查询嵌入到稠密向量空间中,然后使用余弦相似度等度量来衡量它们之间的相似性。
稠密检索的优势是擅长深度语义匹配,尤其是复杂query的场景,复杂query与正确答案之间的重叠词汇非常少,需要深度语义匹配,这种情况下稠密检索的效果更好。与稀疏检索相比,稠密检索能更好地捕捉语义层面的相似性,因此在许多任务中表现更优。
然而,稠密检索的缺点是无法很好地处理字符串精确匹配的case。另外,稠密检索的计算复杂度通常较高,需要更多的计算资源。
此外,稠密检索的一个局限是需要在有标注数据上学习模型参数。如果训练数据中不包含目标领域的训练数据,稠密检索的效果就会变差。
下面是一个适合用稀疏检索进行词汇匹配的case:
查询文本:介绍下货号T12W135211F的卖点。
正确切片:货号T12W135211F的面料是织物/合成革,卖点是FILA厚底家族硬糖鞋,专为女性打造,该款式稳健4.5CM左右厚底增高设计,视觉上拉高比例,增高显瘦,轻便大底,日常休闲出街无负担,EVA橡胶大底回弹耐磨。
当文档库中有非常多不同货号时,货号由数字或字母组合而成,没有明确的语义信息,稠密检索无法很好地处理这种case,这时就需要用到稀疏检索。在RAG中,可以组合稠密检索和稀疏检索进行混合检索,来充分发挥这两种检索方法各自优势,来提升文本检索的效果。
5扩展向量模型的序列长度
目前业界大多数向量模型只支持最大序列长度512的输入文本。限制向量模型最大序列长度可能有以下几方面原因:
\1. 向量模型大多是基于Bert、RoBerta等预训练语言模型来进行训练的。Bert等预训练语言模型采用了训练式的绝对位置编码,在MLM预训练阶段的最大序列长度就是512。从头训练一个更大序列长度的BERT模型成本是比较大的。
\2. 计算复杂度限制和显存占用限制:transformer的计算量是序列长度的二次方,显存占用也是序列长度的二次方。
\3. 实际文本数据中,大多数句子和段落的长度小于512个词。512的最大序列长度可以满足文本检索的大部分需要。如果设置更大的序列长度,训练过程中,要处理大量的pading数据,会降低训练效率。
\4. 较长的序列中可能包含了更多的噪音和无关信息,处理过长的序列可能会影响模型的泛化能力。这可能是为什么openai的embedding模型虽然上下文长度更长,但在短文本上效果要比其他embedding模型差。
只支持最大序列长度512的向量模型不能满足长文本检索的需要,扩展向量模型的最大序列长度是非常有必要的。扩展向量模型的最大序列长度有几种不同的方法。
对于采用训练式位置编码的Bert模型,模型将输入序列的位置信息作为可训练的位置编码(position embedding)矩阵,将词向量与位置向量相加起来作为transformer层的输入。以google-bert/bert-large-uncased模型为例,位置编码矩阵的形状是[512, 1024],512是序列长度维度,1024是向量维度。当序列长度超过512时,就没有对应的位置编码向量,模型也就无法处理序列长度超过512的输入文本。
对于采用训练式位置编码的Bert模型,要向量扩展模型的最大序列长度,最简单的方法是直接扩展模型的位置编码矩阵。具体地,要想把向量模型的最大序列长度从512扩展到4096,需要将位置编码矩阵从[512, 1024]扩展到[4096,1024]。接下来的问题就是如何训练新扩展的512-4096的位置编码,可以采用两阶段的训练方法。
第一个阶段,部分参数训练。该阶段训练向量模型时,只训练随机初始化的512-4096的位置编码,冻结稠密向量模型其他部分的模型参数。通过训练部分参数的方法,只训练新扩展的随机初始化的位置编码,一方面,可以保留预训练好的向量模型学习到的丰富的语言知识,避免在学习过程中损害向量模型的效果;另一方面,只训练新增的随机初始化的模型参数可以减少训练时间,由于原模型参数被冻结,训练过程中需要更新的参数数量减少,从而加快训练速度。
第二阶段,全参数训练。经过部分参数训练的阶段,已经学习了新扩展的位置编码,扩展了向量模型可以处理的最大序列长度。为了进一步提升了稠密向量模型在长文本序列上的效果,还需要进行全参数微调。
向量模型扩展位置编码矩阵的过程,有点类似于Chinese LLaMA等工作基于开源大模型扩展中文词表再进行训练的过程。stella就采用了扩展位置编码矩阵的方法来扩展向量模型的最大序列长度。
6基于大语言模型的向量模型
现有的大多数向量模型都是采用BERT式的编码器作为基座模型,如果训练数据中不包含目标领域的训练数据,向量模型的检索效果就会变差。另一个思路是基于GPT式的大语言模型来训练向量模型,基于LLM来训练向量模型有着诸多优势。LLM有着更大的参数规模(例如7B),LLM也在大量的文本语料上进行了预训练,有着更强的语义理解能力。另外,LLM有着更长的最大序列长度(例如8K/32K,甚至更长),LLM通常会在多语言的文本语料上进行预训练,LLM有着更好的多语言理解能力。
不同于BERT式的编码器采用双向注意力机制,GPT式的LLM采用单向注意力机制。基于LLM来训练向量模型时是否保持使用单向注意力机制?这有着不同的选择。
一种做法是仍使用单向注意力机制。对于BERT式的编码器,获取句子向量的一种池化方法是CLS池化,也就是在query或passage前添加一个特殊符号[CLS],作为编码器模型的输入,将[CLS]位置上最后一个transformer层的输出向量作为句子向量。对于GPT式的LLM,由于采用单向注意力机制,获取句子向量的方法则有所不同,在query或passage后添加一个特殊符号[EOS],作为语言模型的输入,将[EOS]位置上最后一个transformer层的输出向量作为句子向量。接着就可以通过对比学习的方法来训练基于LLM的向量模型,可以采用全参数训练或LoRA方法来微调模型。
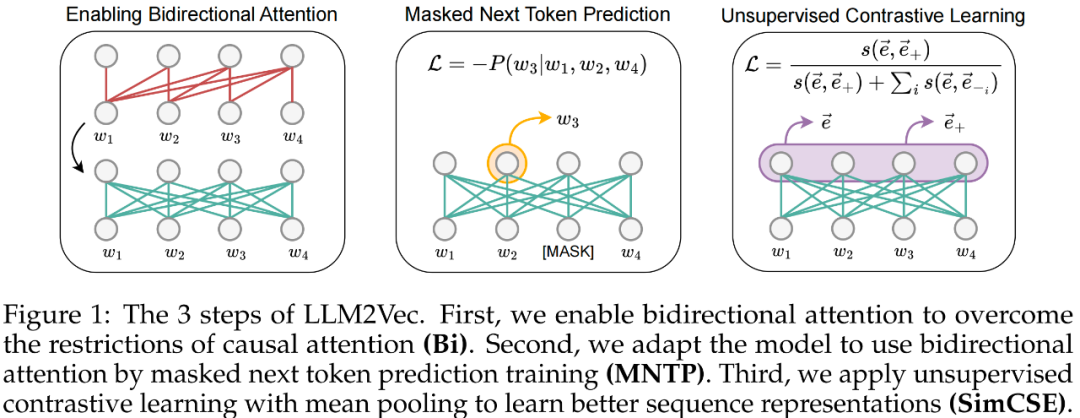
另一种方法是使用双向注意力机制。LLM2Vec提出了在保持原生LLM通用能力的情况下,通过自监督的方法来提升LLM的句子向量表示能力。如上图所示,对于任何一个LLM,都可以通过以下三个步骤来提升LLM的句子向量表示能力。
\1. 将LLM的单向注意力机制(causal attention)修改成双向注意力机制(bidirectional attention)。
\2. 掩码语言模型MLM训练。以LoRA方法来微调模型,采用自监督的方法预测被mask掉的词,文中称为Masked Next Token Prediction,简称MNTP。实际上就是BERT的MLM训练任务。
\3. 继续以LoRA方法来微调模型,采用平均池化方法来获取句子向量表示,来进行对比学习训练,提升LLM的句子向量表示能力。
基于LLM来训练向量模型可以获得更好的检索效果,但存在一个重要的问题是LLM的推理速度。google-bert/bert-large-uncased模型的参数量约为325M,即使小尺寸的LLM参数量也有7B,是bert-large模型参数量的20倍,推理耗时也可以近似估计为bert-large模型的20倍。RAG检索需要尽可能快的响应速度,用基于LLM的向量模型进行检索推理速度太慢,在工程上是难以接受的。
7序列长度对检索效果的影响
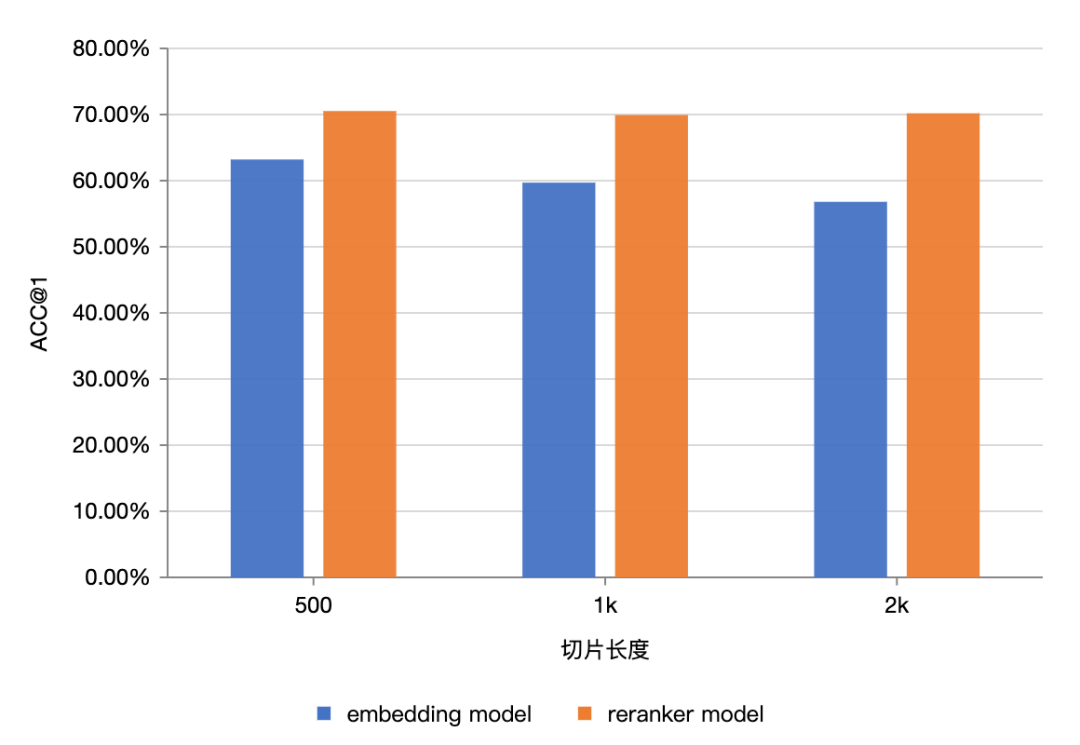
文本切片的序列长度越长,文本切片中可能包含了更多的噪音和无关信息,处理过长的序列可能会影响模型的泛化能力。从下图来看,对于embedding模型(双编码器)来说,随着切片长度增大,从500–>1k–>2k,embedding模型的检索准确率有比较明显的下降。随着切片的序列长度增大,切片中包含的与query无关的噪声信息变多了,embedding模型的检索准确率自然下降了。
从下图来看,对于reranker模型(交叉编码器)来说,随着切片长度增大,从500–>1k–>2k,reranker模型的检索准确率并没有下降,几乎持平。这说明了交叉编码器对长序列中噪声信息的容忍性更强,这可能得益于交叉编码器可以细粒度地建模query和passage之间的语义交互。
8参考文献
滑动查看参考文献
1. Zhao W X, Liu J, Ren R, et al. Dense text retrieval based on pretrained language models: A survey[J]. ACM Transactions on Information Systems, 2024, 42(4): 1-60.
2. Chen J, Xiao S, Zhang P, et al. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation[J]. arXiv preprint arXiv:2402.03216, 2024.
3. BehnamGhader P, Adlakha V, Mosbach M, et al. Llm2vec: Large language models are secretly powerful text encoders[J]. arXiv preprint arXiv:2404.05961, 2024.
4. Wang L, Yang N, Huang X, et al. Improving text embeddings with large language models[J]. arXiv preprint arXiv:2401.00368, 2023.
5. Xiao S, Liu Z, Shao Y, et al. RetroMAE: Pre-training retrieval-oriented language models via masked auto-encoder[J]. arXiv preprint arXiv:2205.12035, 2022.
6. Li Z, Zhang X, Zhang Y, et al. Towards general text embeddings with multi-stage contrastive learning[J]. arXiv preprint arXiv:2308.03281, 2023.
7. Xiao S, Liu Z, Zhang P, et al. C-pack: Packaged resources to advance general chinese embedding[J]. arXiv preprint arXiv:2309.07597, 2023.
8. Muennighoff N. Sgpt: Gpt sentence embeddings for semantic search. arXiv 2022[J]. arXiv preprint arXiv:2202.08904.
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 29
29 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)