4-大语言模型—理论基础:LLaMA模型(让代码“活过来”)
RMSNorm:给数据 “定规矩”,让模型训练更稳定,计算更快;SwiGLU:带 “智能开关”,让模型更灵活地抓重点,学习复杂语言模式;RoPE:用 “旋转魔法” 给词加位置标签,让模型更懂词的顺序和相对关系。看例子(数据处理):把文本拆成字符,建立字符和数字的对应。练基础(模型搭建):用 Transformer 和 LLaMA 的核心技术,让模型能理解字符的关系和位置。反复练(训练):通过预测下
目录
2.1、 RMSNorm 归一化函数:给数据 “定规矩” 的简化版工具
2.1.2、RMSNorm 的原理:简化版的 “数据稳定器”
2.2、SwiGLU 激活函数:让模型学会 “抓重点” 的 “智能阀门”
2.2.2、SwiGLU 的原理:带 “智能开关” 的信息过滤器
2.3.3、RoPE 的原理:用 “旋转” 表示位置,让相对关系更稳定
二、 step1:数据处理 —— 把文本 “翻译” 成计算机能懂的语言
三、 step2:模型搭建 —— 模拟 “理解字符关系” 的神经网络
1、LLAMA的模型结构(GPT2模型)
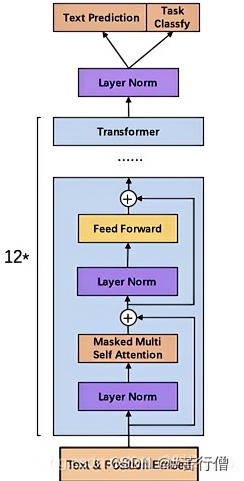
2、重点内容
2.1、 RMSNorm 归一化函数:给数据 “定规矩” 的简化版工具
2.1.1、为什么需要归一化?
想象你在训练一个 “深度学习模型”,就像教一个学生做数学题。如果题目中的数字忽大忽小(比如一会儿是 1000,一会儿是 0.001),学生很难找到规律,学习效率会很低。 归一化的作用就是把这些 “忽大忽小” 的数据变得 “大小适中、分布稳定”,让模型更容易学习。
2.1.2、RMSNorm 的原理:简化版的 “数据稳定器”
LLaMA 用的 RMSNorm,是对传统 LayerNorm(层归一化)的简化。 传统 LayerNorm 的步骤是:
- 计算数据的 “平均值”;
- 计算数据的 “方差”(衡量数据波动程度);
- 用 “(数据 - 平均值)/ 方差开根号” 把数据归一化;
- 最后用可学习的参数调整(缩放和平移)。
但 RMSNorm 觉得:“步骤 1 太麻烦了,能不能省掉?” 实际测试发现,去掉 “减平均值” 这一步,效果差不多,还能少算很多次减法,速度更快。
所以 RMSNorm 的核心逻辑是:只关注数据的 “波动幅度”,不关注 “整体偏移”,用 “均方根”(Root Mean Square)来衡量波动,然后归一化。
2.1.3、数学公式(分步解释)
假设输入是一组数据(比如一个词向量):\(x = [x_1, x_2, ..., x_d]\)(d是向量维度)。
RMSNorm 的计算分 3 步:
-
算 “均方根”(RMS):先把每个数平方,求平均值,再开根号。 公式:
(直观理解:这一步是在算 “数据整体波动的平均水平”,比如数据全是 0 时,RMS 是 0;数据波动大时,RMS 会变大。)
-
归一化:用原始数据除以 RMS,让数据的 “波动幅度” 统一。 公式:
(直观理解:比如原来数据是 [10, 20, 30],RMS 约为 21.6,归一化后变成 [0.46, 0.92, 1.39],波动幅度变小了。)
-
缩放调整:最后用一个可学习的参数\(\alpha\)(类似 “放大镜”)调整归一化后的数据,让模型可以自主决定 “波动幅度需要多大”。 公式:
2.1.4、通俗理解:为什么 RMSNorm 好用?
- 传统 LayerNorm 像 “严格的老师”:既管数据的 “整体偏移”(减平均值),又管 “波动幅度”(除方差),但计算费时间。
- RMSNorm 像 “灵活的助教”:只管 “波动幅度”(除 RMS),不管 “整体偏移”,计算更快,还能达到差不多的效果。
- 在 LLaMA 这种超大规模模型中,“快一点” 意味着训练和推理效率提升很多,所以 RMSNorm 成了更好的选择。
2.2、SwiGLU 激活函数:让模型学会 “抓重点” 的 “智能阀门”
2.2.1、激活函数的作用:给模型 “拐弯” 的能力
模型处理数据时,基本操作是 “线性变换”(比如y = 2x + 3),但线性变换只能处理简单关系(比如 “x 增大,y 一定增大”)。而语言规律是复杂的(比如 “‘好’和‘不好’意思相反”),需要 “非线性” 能力 —— 这就是激活函数的作用:给模型 “拐弯” 的能力,让它能学习复杂模式。
2.2.2、SwiGLU 的原理:带 “智能开关” 的信息过滤器
SwiGLU 是激活函数的 “升级版”,核心是 “门控机制”—— 像一个 “智能开关”,能根据输入内容决定 “哪些信息通过,哪些信息过滤”。
传统激活函数(如 ReLU)像 “固定开关”:比如 ReLU 规定 “负数全关掉,正数全通过”,不够灵活。而 SwiGLU 的 “开关” 是 “可调节” 的,能根据输入内容动态变化。
2.2.3、数学公式(分步解释)
SwiGLU 的计算分 3 步,假设输入是一个词向量x:
-
做两次线性变换:把x变成两个新向量a和b(相当于给信息 “换个形式”)。 公式:
;
(
是可学习的权重矩阵,
是偏置,类似 “不同的过滤器”。)
-
算 “门控值”:用 GELU 函数(一种平滑的激活函数,近似于 “概率”)把a变成 “开关的开合程度”(范围 0~1)。 公式:
(GELU 的作用:比如输入a很大时,gate≈1(开关全开);输入a很小时,gate≈0(开关全关);中间值时,gate 在 0~1 之间(半开)。)
-
信息过滤:用 “门控值” 乘以b,决定b中哪些信息通过。 公式:
2.2.4、通俗理解:SwiGLU 如何 “抓重点”?
比如模型处理句子 “猫喜欢吃鱼,狗喜欢吃骨头”:
- 当处理 “猫” 时,SwiGLU 的 “门控” 会打开与 “动物”“鱼” 相关的信息通道,关掉 “狗”“骨头” 的通道;
- 当处理 “狗” 时,门控又会切换,打开 “骨头” 相关通道,关掉 “鱼” 的通道。
这种 “动态开关” 让模型能更精准地捕捉不同输入的特点,比固定开关的激活函数更灵活 —— 这也是 LLaMA 能理解复杂语言的原因之一。
2.3、RoPE:让模型 “记住词序” 的 “旋转魔法”
2.3.1、位置编码的作用:告诉模型 “谁先谁后”
语言中,词的顺序至关重要:“我打你” 和 “你打我” 意思完全相反。但 Transformer 等模型的 “自注意力” 机制本身不关心顺序(输入词向量打乱后,计算结果不变),所以需要 “位置编码” 给每个词加上 “位置标签”,让模型知道 “谁在前,谁在后”。
2.3.2、传统位置编码的问题:“记不住长句子”
早期用 “绝对位置编码”:给第 1 个词加 [1,0,0...],第 2 个词加 [0,1,0...]…… 但这种方式有两个问题:
- 句子太长时,模型没见过这么大的位置标签,会 “懵”;
- 无法体现 “相对位置”:比如 “第 3 个词和第 5 个词” 与 “第 103 个词和第 105 个词” 的相对距离都是 2,但绝对位置编码让它们看起来完全不同,模型学不会这种共性。
2.3.3、RoPE 的原理:用 “旋转” 表示位置,让相对关系更稳定
RoPE(旋转位置编码)的核心想法是:用 “旋转角度” 表示位置。
想象每个词向量是平面上的一个点(比如 2D 向量(x,y)),第n个词的位置用 “旋转n个角度” 来表示:
- 第 1 个词:旋转
度;
- 第 2 个词:旋转
度;
- 第n个词:旋转
度;
这样,两个词的相对位置(比如差k个位置)就对应 “旋转角度差”,不管它们在句子的开头还是结尾,这个 “角度差” 都不变 —— 解决了绝对位置编码的问题。
2.3.4、数学公式(2D 例子,直观易懂)
对于一个 2D 词向量(x, y),第n个位置的 RoPE 编码就是把它旋转度,旋转后的向量(x', y')计算如下:
- 其中
,k是维度索引,d是向量维度,确保不同维度旋转速度不同)。
扩展到高维:词向量通常是几百维(比如 512 维),RoPE 把高维向量拆成多个 2D “对子”(比如第 1 和第 2 维一组,第 3 和第 4 维一组……),每组都用上面的公式旋转,这样就给整个高维向量加上了位置信息。
2.3.5、通俗理解:RoPE 如何让模型 “懂顺序”?
- 旋转角度直接和位置挂钩:位置越靠后,旋转角度越大,模型能通过向量的 “朝向” 判断词的顺序。
- 相对位置更稳定:比如 “词 A 在词 B 前 2 个位置”,不管在句子的任何地方,A 的旋转角度都比 B 小
- 比如处理 “我爱你” 和 “你爱我” 时,RoPE 会给 “我”“爱”“你” 不同的旋转角度,模型通过角度差异就能区分顺序,理解两句话的不同意思。
2.4、总结:三个组件如何让 LLaMA 更 “聪明”?
- RMSNorm:给数据 “定规矩”,让模型训练更稳定,计算更快;
- SwiGLU:带 “智能开关”,让模型更灵活地抓重点,学习复杂语言模式;
- RoPE:用 “旋转魔法” 给词加位置标签,让模型更懂词的顺序和相对关系。
3、完整代码
"""
文件名: improved_llama_char_level
作者: 墨尘
日期: 2025/7/19
项目名: dl_env
备注: 优化版LLaMA简化模型(字符级分词,无需额外依赖)
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import time
import math
from typing import Optional, Tuple
from collections import Counter # 用于构建词汇表
# --------------------------- 1. 核心组件:RMSNorm归一化 ---------------------------
class RMSNorm(nn.Module):
"""
RMSNorm归一化:LLaMA中使用的简化版LayerNorm
作用:稳定训练过程中的数据分布,加速收敛
与传统LayerNorm的区别:不减去均值,仅通过均方根归一化,计算更快
"""
def __init__(self, hidden_size: int, eps: float = 1e-6):
super().__init__()
self.eps = eps # 防止除零的小常数
self.alpha = nn.Parameter(torch.ones(hidden_size)) # 可学习的缩放参数(控制整体幅度)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x形状:(batch_size, seq_len, hidden_size)
# 1. 计算均方根(RMS):衡量数据的整体波动幅度
rms = torch.sqrt(torch.mean(x**2, dim=-1, keepdim=True) + self.eps)
# 2. 归一化 + 缩放:让数据波动幅度统一,再通过alpha调整
return x / rms * self.alpha
# --------------------------- 2. 核心组件:SwiGLU激活函数 ---------------------------
class SwiGLU(nn.Module):
"""
SwiGLU激活函数:带门控机制的非线性激活函数
作用:动态过滤信息,让模型更关注重要特征,增强表达能力
相比传统激活函数(如ReLU):通过门控机制实现更灵活的信息选择
"""
def __init__(self, hidden_size: int, intermediate_size: int):
super().__init__()
self.w1 = nn.Linear(hidden_size, intermediate_size) # 门控线性变换(决定"开关程度")
self.w2 = nn.Linear(intermediate_size, hidden_size) # 输出变换(确保维度与输入一致)
self.w3 = nn.Linear(hidden_size, intermediate_size) # 信息线性变换(待过滤的信息)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x形状:(batch_size, seq_len, hidden_size)
gate = F.gelu(self.w1(x)) # 门控值(范围0~1,控制信息通过比例)
info = self.w3(x) # 信息值(原始特征经过变换)
return self.w2(gate * info) # 门控过滤(重要信息通过,次要信息抑制)
# --------------------------- 3. 核心组件:RoPE位置编码 ---------------------------
def rope_position_encoding(x: torch.Tensor, max_seq_len: int) -> torch.Tensor:
"""
RoPE(旋转位置编码):将位置信息通过旋转操作融入词向量
作用:让模型理解词的顺序和相对位置关系(如"我打你"和"你打我"的区别)
优势:相比传统位置编码,能更好地处理长序列,保留相对位置信息
"""
batch_size, seq_len, hidden_size = x.shape
assert hidden_size % 2 == 0, "hidden_size必须为偶数(RoPE按2D对子处理)"
# 1. 计算旋转角度θ(不同维度旋转速度不同,避免位置信息混淆)
dim_idx = torch.arange(hidden_size // 2, device=x.device) # 维度索引(0,1,...,hidden_size/2-1)
theta = 1.0 / (10000 ** (2 * dim_idx / hidden_size)) # 角度随维度增大而减小(旋转速度变慢)
# 2. 计算每个位置的旋转角度(位置n的角度 = n * θ)
positions = torch.arange(seq_len, device=x.device) # 位置索引(0,1,...,seq_len-1)
freqs = torch.outer(positions, theta) # 外积:(seq_len, hidden_size//2),每个位置的旋转角度
# 3. 生成cos和sin矩阵(扩展到批次维度)
cos = freqs.cos().unsqueeze(0).expand(batch_size, -1, -1) # (batch, seq_len, hidden_size//2)
sin = freqs.sin().unsqueeze(0).expand(batch_size, -1, -1) # (batch, seq_len, hidden_size//2)
# 4. 拆分词向量为2D对子并应用旋转(核心操作)
x1, x2 = x[..., ::2], x[..., 1::2] # 奇数维和偶数维拆分(如(x1,x2), (x3,x4)...)
x1_rot = x1 * cos - x2 * sin # 旋转后的第一分量
x2_rot = x1 * sin + x2 * cos # 旋转后的第二分量
# 5. 合并旋转后的向量,恢复原维度
return torch.cat([x1_rot, x2_rot], dim=-1) # (batch_size, seq_len, hidden_size)
# --------------------------- 4. 改进版LLaMA模型 ---------------------------
class ImprovedLLaMA(nn.Module):
"""
改进版LLaMA模型(字符级):基于LLaMA核心架构简化实现
特点:增大模型容量,适配字符级输入,保留RMSNorm、SwiGLU、RoPE核心组件
用途:文本生成任务(根据输入前缀预测后续字符)
"""
def __init__(
self,
vocab_size: int, # 字符级词汇表大小
hidden_size: int = 512, # 隐藏层维度(增大容量)
num_layers: int = 6, # Transformer层数(增加深度)
num_heads: int = 8, # 注意力头数(增强并行性)
max_seq_len: int = 128, # 最大序列长度(支持更长文本)
dropout: float = 0.1, # Dropout率(防止过拟合)
):
super().__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.max_seq_len = max_seq_len # 限制输入长度,避免位置编码超限
# 1. 字符嵌入层:将字符ID转换为向量(字符级语义表示)
self.embedding = nn.Embedding(vocab_size, hidden_size)
# 2. Transformer块序列(模型核心,多层堆叠)
self.layers = nn.ModuleList()
for _ in range(num_layers):
self.layers.append(nn.ModuleDict({
# 多头自注意力:捕捉字符间的依赖关系(如"天"和"气"常搭配)
"attn": nn.MultiheadAttention(
embed_dim=hidden_size,
num_heads=num_heads,
batch_first=True, # 输入格式:(batch, seq, dim)
dropout=dropout
),
"norm1": RMSNorm(hidden_size), # 注意力后归一化
"dropout1": nn.Dropout(dropout), # 注意力后dropout
# 前馈网络:通过SwiGLU处理局部特征
"ffn": SwiGLU(hidden_size, intermediate_size=hidden_size * 4), # 中间维度为4倍隐藏层
"norm2": RMSNorm(hidden_size), # 前馈网络后归一化
"dropout2": nn.Dropout(dropout), # 前馈网络后dropout
}))
# 3. 输出层:将隐藏向量映射到字符表概率分布
self.output_layer = nn.Linear(hidden_size, vocab_size)
# 初始化权重(加速训练收敛)
self._init_weights()
def _init_weights(self):
"""权重初始化:线性层和嵌入层使用正态分布初始化"""
for param in self.parameters():
if param.dim() > 1: # 仅对矩阵参数初始化(忽略偏置等1D参数)
nn.init.normal_(param, mean=0.0, std=0.02) # 小标准差,避免初始值过大
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
"""
前向传播:将字符ID序列转换为下一个字符的概率分布
input_ids: 输入字符ID序列,形状为(batch_size, seq_len)
return: 每个位置的字符概率分布,形状为(batch_size, seq_len, vocab_size)
"""
# 1. 字符嵌入:ID→向量(加入语义信息)
x = self.embedding(input_ids) # (batch_size, seq_len, hidden_size)
# 2. 添加RoPE位置编码:融入位置信息(让模型知道字符顺序)
x = rope_position_encoding(x, self.max_seq_len)
# 3. 逐层通过Transformer块(特征提取)
for layer in self.layers:
# 自注意力机制 + 残差连接 + 归一化 + Dropout
residual = x # 残差连接:保留原始特征
x = layer["norm1"](x) # 先归一化(RMSNorm)
attn_output, _ = layer["attn"](x, x, x) # 自注意力(查询=键=值)
x = residual + layer["dropout1"](attn_output) # 残差更新 + Dropout
# 前馈网络 + 残差连接 + 归一化 + Dropout
residual = x # 残差连接
x = layer["norm2"](x) # 归一化
ffn_output = layer["ffn"](x) # SwiGLU处理
x = residual + layer["dropout2"](ffn_output) # 残差更新 + Dropout
# 4. 输出层:预测下一个字符的概率
return self.output_layer(x)
@torch.no_grad() # 生成时不计算梯度,节省内存和时间
def generate(
self,
input_ids: torch.Tensor,
max_new_tokens: int = 50, # 生成的最大字符数
temperature: float = 0.5, # 温度(控制随机性:值越小越确定)
top_k: int = 50, # 仅保留概率最高的top_k个字符
) -> torch.Tensor:
"""
文本生成:根据输入前缀生成后续字符
策略:采样(结合temperature和top_k,平衡多样性和合理性)
"""
for _ in range(max_new_tokens):
# 1. 截断长序列(仅保留最后max_seq_len个字符,避免位置编码超限)
input_ids_cond = input_ids[:, -self.max_seq_len:]
# 2. 模型预测:获取最后一个字符的概率分布
logits = self(input_ids_cond)[:, -1, :] # 取最后一个位置的预测:(batch_size, vocab_size)
logits = logits / temperature # 温度调整(降低温度=增强高概率字符的权重)
# 3. Top-k过滤:仅保留概率最高的k个字符,减少低概率字符的干扰
if top_k is not None:
v, _ = torch.topk(logits, top_k) # 取top_k的阈值
logits[logits < v[:, [-1]]] = -float('inf') # 低于阈值的字符概率设为负无穷
# 4. 计算概率分布并采样下一个字符
probs = F.softmax(logits, dim=-1) # 归一化为概率
next_token = torch.multinomial(probs, num_samples=1) # 按概率采样
# 5. 将新字符添加到序列中
input_ids = torch.cat([input_ids, next_token], dim=1)
return input_ids
# --------------------------- 5. 训练辅助函数 ---------------------------
def train_model(
model: nn.Module,
train_loader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
scheduler,
num_epochs: int,
device: torch.device
) -> None:
"""
模型训练函数:
- 输入:模型、数据加载器、优化器、调度器、训练轮数、设备
- 功能:执行训练循环,打印每轮的损失和困惑度
"""
model.train() # 切换到训练模式(启用Dropout等)
for epoch in range(num_epochs):
start_time = time.time() # 记录本轮开始时间
total_loss = 0.0 # 累计损失
steps = 0 # 累计步数
# 遍历训练数据
for input_ids, labels in train_loader:
# 移动数据到设备(GPU/CPU)
input_ids, labels = input_ids.to(device), labels.to(device)
# 前向传播:计算预测结果和损失
outputs = model(input_ids) # 模型输出:(batch_size, seq_len, vocab_size)
# 计算交叉熵损失(将三维输出展平为二维:(batch*seq_len, vocab_size))
loss = F.cross_entropy(
outputs.view(-1, model.vocab_size),
labels.view(-1) # 标签展平为一维:(batch*seq_len,)
)
# 反向传播:更新模型参数
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
if scheduler:
scheduler.step() # 学习率调度
# 累计损失和步数
total_loss += loss.item()
steps += 1
# 计算本轮平均损失和困惑度
avg_loss = total_loss / steps
# 困惑度(Perplexity):衡量预测难度,值越小越好(=exp(平均损失))
perplexity = math.exp(avg_loss) if avg_loss < 30 else float('inf') # 避免数值溢出
# 打印训练进度
end_time = time.time()
print(f"Epoch {epoch+1}/{num_epochs} | Loss: {avg_loss:.4f} | Perplexity: {perplexity:.4f} | Time: {end_time - start_time:.2f}s")
# --------------------------- 6. 数据处理(字符级分词) ---------------------------
def load_corpus_and_tokenize(file_path=None):
"""
加载语料并进行字符级分词:
- 输入:可选的文件路径(默认使用内置语料)
- 输出:字符列表(如"你好"→["你", "好"])
"""
# 内置训练语料(扩充版,包含更多场景)
if file_path is None:
corpus = """
从前有座山,山里有座庙,庙里有个老和尚和一个小和尚。
老和尚在给小和尚讲故事:"从前有座山,山里有座庙,庙里有两个和尚,一个老一个小。
小和尚问老和尚:'师父,我们为什么要住在山里?'老和尚说:'因为山里有清净,适合修行。'
春天来了,公园里的花儿开了,有红色的玫瑰,黄色的迎春花,还有紫色的丁香。
小朋友们在草地上放风筝,风筝飞得很高,像小鸟一样在天上飞。
夏天的时候,天气很热,人们喜欢去游泳池游泳,或者在树荫下吃西瓜。
晚上,萤火虫提着小灯笼在空中飞,像一颗颗小星星。
秋天是收获的季节,农民伯伯在田里收割稻子,果园里的苹果、梨子都熟了,红彤彤的。
树叶变黄了,一片片落下来,像蝴蝶在跳舞。
冬天会下雪,大地盖上了一层厚厚的白被子。小朋友们穿着厚厚的棉袄,在雪地里堆雪人、打雪仗,可开心了。
太阳每天从东边升起,西边落下。早上的太阳红红的,不刺眼;中午的太阳很晒,要戴帽子;傍晚的太阳会变成金黄色,很美。
月亮有时候圆,有时候弯。圆圆的月亮像盘子,弯弯的月亮像小船。晚上,月亮和星星一起照亮夜空。
"""
else:
# 从文件加载语料(需确保文件编码为utf-8)
with open(file_path, 'r', encoding='utf-8') as f:
corpus = f.read()
# 清理语料:去除多余换行和空格
corpus = corpus.replace('\n', ' ').replace(' ', ' ').strip()
# 字符级分词:直接按字符拆分(无需额外库)
tokenized_corpus = list(corpus) # 如"abc"→["a", "b", "c"]
return tokenized_corpus
def build_vocab(tokenized_corpus, min_freq=1):
"""
构建字符级词汇表:
- 输入:字符列表、最小出现频率(过滤低频字符)
- 输出:字符到ID的映射(如{"你":0, "好":1, ...})
"""
# 统计字符频率
char_counts = Counter(tokenized_corpus) # 如{",":10, "山":5, ...}
# 过滤低频字符(仅保留出现次数≥min_freq的字符)
filtered_chars = [char for char, count in char_counts.items() if count >= min_freq]
# 添加特殊符号(填充、未知字符等)
special_tokens = ["<pad>", "<unk>", "<bos>", "<eos>"] # 填充、未知、句首、句尾
# 构建词汇表(特殊符号+过滤后的字符)
vocab = {token: idx for idx, token in enumerate(special_tokens + filtered_chars)}
return vocab
class CharDataset(torch.utils.data.Dataset):
"""
字符级数据集:
- 功能:将字符ID序列转换为训练样本(输入→目标)
- 样本格式:输入为[char1, char2, ..., chark],目标为[char2, ..., chark+1](预测下一个字符)
"""
def __init__(self, token_ids, block_size):
self.token_ids = token_ids # 字符ID序列
self.block_size = block_size # 序列长度(如64)
def __len__(self):
# 数据集大小:总长度 - 序列长度(确保能取到完整样本)
return len(self.token_ids) - self.block_size
def __getitem__(self, idx):
# 输入序列:从idx开始,取block_size个字符ID
x = self.token_ids[idx:idx + self.block_size].clone().detach()
# 目标序列:输入序列的下一个字符(用于训练预测)
y = self.token_ids[idx + 1:idx + self.block_size + 1].clone().detach()
return x, y
# --------------------------- 7. 主函数(完整版) ---------------------------
if __name__ == "__main__":
# --------------------------- 配置参数(增大模型+优化生成) ---------------------------
config = {
"hidden_size": 512, # 隐藏层维度(从128增至512,提升容量)
"num_layers": 6, # Transformer层数(从3增至6,加深模型)
"num_heads": 8, # 注意力头数(从4增至8,增强并行性)
"max_seq_len": 128, # 最大序列长度(支持更长文本)
"block_size": 64, # 训练用序列长度(一次输入64个字符)
"batch_size": 4, # 批次大小(模型增大,减小批次避免显存不足)
"dropout": 0.1, # Dropout率(防止过拟合)
"learning_rate": 2e-4, # 学习率(稍降低,配合大模型)
"num_epochs": 30, # 训练轮数(增加轮数,让模型充分学习)
"max_new_tokens": 50, # 生成时最多新增50个字符
"temperature": 0.5, # 生成温度(降低至0.5,减少随机性)
"top_k": 50, # 生成时保留前50个高概率字符
}
# --------------------------- 设备配置 ---------------------------
# 自动选择设备(优先GPU,无GPU则用CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device} (GPU可用: {torch.cuda.is_available()})")
# --------------------------- 数据准备(字符级) ---------------------------
# 1. 加载语料并进行字符级分词
tokenized_corpus = load_corpus_and_tokenize() # 返回字符列表
print(f"\n字符级语料长度: {len(tokenized_corpus)} 个字符")
print(f"字符预览: {tokenized_corpus[:10]}...") # 前10个字符
# 2. 构建字符级词汇表
vocab = build_vocab(tokenized_corpus, min_freq=1) # 保留所有出现过的字符
vocab_size = len(vocab) # 词汇表大小
reverse_vocab = {idx: char for char, idx in vocab.items()} # ID→字符映射(用于生成时解码)
print(f"字符级词汇表大小: {vocab_size}(包含特殊符号和所有出现的字符)")
# 3. 将字符转换为ID序列(模型只能处理数字ID)
unk_idx = vocab["<unk>"] # 未知字符的ID
token_ids = [vocab.get(char, unk_idx) for char in tokenized_corpus] # 字符→ID
token_ids = torch.tensor(token_ids, dtype=torch.long) # 转换为tensor
# 4. 创建训练数据集和数据加载器
dataset = CharDataset(token_ids, block_size=config["block_size"]) # 字符级数据集
train_loader = torch.utils.data.DataLoader(
dataset,
batch_size=config["batch_size"], # 每批4个样本
shuffle=True, # 打乱数据
drop_last=True # 丢弃最后一个不完整的批次
)
print(f"训练批次数量: {len(train_loader)}(每批{config['batch_size']}个样本)")
# --------------------------- 初始化模型 ---------------------------
model = ImprovedLLaMA(
vocab_size=vocab_size,
hidden_size=config["hidden_size"],
num_layers=config["num_layers"],
num_heads=config["num_heads"],
max_seq_len=config["max_seq_len"],
dropout=config["dropout"]
).to(device) # 移动模型到设备
print(f"\n模型结构: ImprovedLLaMA(vocab_size={vocab_size}, hidden_size={config['hidden_size']}, layers={config['num_layers']})")
# --------------------------- 配置优化器和调度器 ---------------------------
# 优化器:AdamW(带权重衰减,防止过拟合)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=config["learning_rate"], # 学习率
weight_decay=0.01 # 权重衰减(正则化)
)
# 学习率调度器:余弦退火(训练后期逐渐降低学习率)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=config["num_epochs"] * len(train_loader), # 总迭代步数
eta_min=1e-5 # 最小学习率
)
# --------------------------- 训练模型 ---------------------------
print("\n" + "="*50)
print("开始训练模型...")
print(f"训练轮数: {config['num_epochs']}, 每轮批次: {len(train_loader)}")
print("="*50 + "\n")
# 记录训练开始时间
start_train_time = time.time()
# 调用训练函数
train_model(
model=model,
train_loader=train_loader,
optimizer=optimizer,
scheduler=scheduler,
num_epochs=config["num_epochs"],
device=device
)
# 计算总训练时间
total_train_time = time.time() - start_train_time
print(f"\n训练完成! 总耗时: {total_train_time:.2f}秒 ({total_train_time/60:.2f}分钟)")
# --------------------------- 生成测试 ---------------------------
print("\n" + "="*50)
print("文本生成测试(字符级)")
print("="*50)
model.eval() # 切换到评估模式(关闭Dropout)
# 测试输入(多个示例)
test_inputs = [
"从前有座山,",
"春天来了,",
"太阳从东边",
"月亮像一只"
]
# 对每个输入生成文本
for input_text in test_inputs:
# 1. 输入文本转换为字符ID
input_ids = [vocab.get(char, unk_idx) for char in input_text] # 字符→ID
input_ids = torch.tensor(input_ids, dtype=torch.long).unsqueeze(0).to(device) # 增加批次维度
# 2. 生成文本
generated_ids = model.generate(
input_ids=input_ids,
max_new_tokens=config["max_new_tokens"],
temperature=config["temperature"],
top_k=config["top_k"]
)
# 3. 生成的ID转换回文本
generated_chars = [reverse_vocab[idx.item()] for idx in generated_ids[0]] # ID→字符
generated_text = "".join(generated_chars) # 拼接字符为文本
# 4. 打印结果
print(f"\n输入: {input_text}")
print(f"生成: {generated_text}")
print("\n所有测试完成!")4、实验结果


5、代码“活”起来
用计算机 “学习” 文本中字符的排列规律,然后根据输入的前缀 “续写” 出合理的内容。整个过程就像人学习写字 —— 先看大量例子(训练),再自己尝试写(生成),只不过这里的 “字” 是单个字符(如 “山”“,”“春” 等)。
一、整体流程:从数据到生成的 4 步走
- 准备数据:把文本拆成单个字符,建立 “字符 - 数字” 对应表(让计算机能理解字符)。
- 搭建模型:用神经网络模拟 “理解字符关系” 的能力(比如 “春” 后面常跟 “天”,“月” 后面常跟 “亮”)。
- 训练模型:让模型通过 “预测下一个字符” 来学习规律(错了就调整,直到越来越准)。
- 生成文本:给模型一个开头(如 “从前有座山,”),让它按学过的规律续写下去。
二、 step1:数据处理 —— 把文本 “翻译” 成计算机能懂的语言
计算机只认数字,所以第一步要把文本转换成数字序列,具体分 3 步:
拆字符:把整篇文本拆成单个字符。
例:“春天来了” →["春", "天", "来", "了"]建词汇表:给每个字符分配一个唯一数字(类似字典)。
例:{"春":1, "天":2, "来":3, "了":4, "<unk>":0}(<unk>代表没见过的字符)转数字序列:用词汇表把字符换成数字,方便模型计算。
例:“春天来了” →[1, 2, 3, 4]做训练样本:把数字序列切成固定长度的片段,让模型学习 “前 n 个字符→第 n+1 个字符” 的映射。
例:片段[1,2,3](输入)→ 目标[2,3,4](预测下一个字符)三、 step2:模型搭建 —— 模拟 “理解字符关系” 的神经网络
模型的核心是Transformer(一种能 “关注上下文” 的神经网络),这里基于 LLaMA 的简化版做了优化,主要包含 4 个关键部分:
1. 字符嵌入层:给字符 “赋予意义”
- 作用:把字符对应的数字(如 “春”=1)转换成向量(一串数字),让相似的字符向量更接近(比如 “春” 和 “夏” 的向量比 “春” 和 “山” 更像)。
- 类比:就像给每个字贴标签,“春” 贴 “季节、温暖”,“山” 贴 “自然、高大”,方便模型区分。
2. 核心组件:让模型 “懂规律” 的 3 大技术
这三个组件是 LLaMA 的精髓,让模型能理解字符的顺序和关系:
组件 通俗理解 例子 RMSNorm 归一化 让数据 “稳定”,避免计算时数值忽大忽小,方便模型学习。 就像给学生打分时 “标准化”(比如都按满分 100 分算,避免有的卷难有的简单)。 SwiGLU 激活函数 带 “开关” 的过滤器,让模型只关注重要信息(比如 “春天” 中 “春” 和 “天” 更重要)。 类似看书时跳过无关段落,只看重点句子。 RoPE 位置编码 告诉模型字符的 “位置”(比如 “我打你” 和 “你打我” 位置不同,意思相反)。 给每个字标上序号(第 1 个、第 2 个...),让模型知道顺序。 3. Transformer 层:堆叠 “理解能力”
模型的核心是多个 Transformer 层堆叠(代码里用了 6 层),每一层包含:
- 多头注意力:让模型同时关注不同位置的字符(比如 “春天来了,花儿开了” 中,“花儿” 和 “春天” 有关联)。
- 前馈网络:用 SwiGLU 进一步处理注意力的结果,提炼更重要的特征。
类比:每一层就像一个 “理解小模块”,多层堆叠后,模型能从简单规律(如 “春” 后接 “天”)学到复杂规律(如 “春天” 后接 “来了,花儿开了”)。
4. 输出层:预测下一个字符
最后通过一个线性层,把模型学到的特征转换成 “每个字符的出现概率”(比如 “春天” 后面,“来” 的概率是 80%,“天” 是 5%)。
四、 step3:训练模型 —— 让模型 “学会预测”
训练的目标是让模型 “预测下一个字符” 的能力越来越强,具体过程:
- 喂数据:给模型输入一段字符序列(如 “春天来”),模型输出每个可能的下一个字符的概率(“了” 80%,“去” 5%...)。
- 算错多少:用 “交叉熵损失” 衡量预测错误(比如实际下一个字符是 “了”,但模型预测 “去” 的概率高,损失就大)。
- 调参数:通过反向传播(类似 “错题订正”)调整模型的参数,让损失变小(下次预测更准)。
- 看效果:用 “困惑度” 衡量模型好坏(值越小越好),困惑度低说明模型对下一个字符的预测更确定。
五、 step4:生成文本 —— 让模型 “续写故事”
训练好的模型可以根据输入前缀 “续写”,比如输入 “从前有座山,”,生成过程:
- 输入转数字:把 “从前有座山,” 转换成数字序列。
- 第一步预测:模型根据输入,算出下一个字符的概率(比如 “山” 后接 “里” 的概率最高),选一个字符(比如 “里”)。
- 循环续写:把新字符加入输入(变成 “从前有座山,里”),再预测下一个字符,直到达到指定长度(代码里默认 50 个字符)。
- 控制随机性:用
temperature(温度)和top_k调整生成结果:
- 温度低(如 0.5):优先选概率高的字符,生成更稳定(但可能重复)。
- top_k=50:只从概率前 50 的字符中选,避免生成奇怪的字符。
总结:整个逻辑就像 “学写字”
- 看例子(数据处理):把文本拆成字符,建立字符和数字的对应。
- 练基础(模型搭建):用 Transformer 和 LLaMA 的核心技术,让模型能理解字符的关系和位置。
- 反复练(训练):通过预测下一个字符,不断调整模型,让它越来越准。
- 自己写(生成):根据输入前缀,用学过的规律续写文本。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 35
35 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)