sakila数据集中最受欢迎的电影题材和明星
在构建DVD数据仓库的基础上,再分析sakila数据集,找出最受欢迎的电影题材、销售数据,最受欢迎的电影明星
一、实验要求
(1)根据数据集(sakila),建立星型数据挖掘模型,并建立数据仓库(sakila_dwh);
(2)根据数据仓库(sakila_dwh),设计一种数据分析,抽取近5年的数据,根据电影题材进行统计,找出最受欢迎的3个电影题材;
(3)导出(2)中找到的3个电影题材的销售数据,存成CSV文件;
(4)根据数据仓库(sakila_dwh),设计一种数据分析,抽取5年的数据,发现最受欢迎的电影明星,并给他们发送邮件。
(5)程序执行过程:尽可能详细描述ETL项目的导入、转换、导出的完整过程,附相应的截图及程序执行结果。
二、实验过程
2.1构建DVD数据仓库
2.2 找最受欢迎的3个电影题材
根据前面建立的sakila_dwh数据仓库,“fact_rental”表中包含了所有的销售数据,需要结合sakila数据库中的表“dim_film”“film_category”找到每条销售记录对应的category_id,排序后,再按照category_id进行分组聚合,得到各个电影题材的销售量,从而找到最受欢迎的3个电影题材。具体实现步骤如下:
(1)建立一个新转换【favorite_film_category】
(2)创建【表输出】组件,并配置
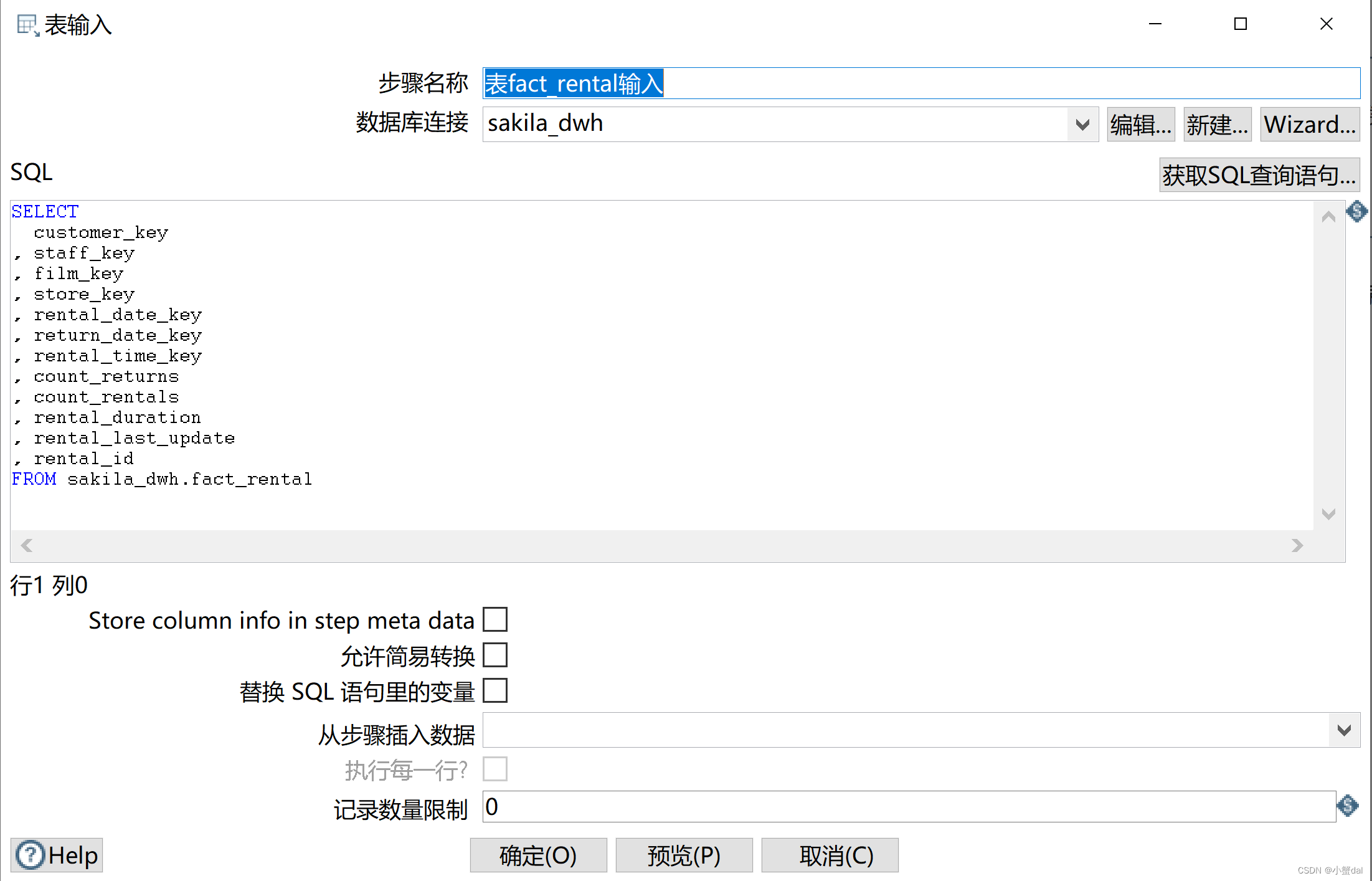
代码:
SELECT
customer_key
, staff_key
, film_key
, store_key
, rental_date_key
, return_date_key
, rental_time_key
, count_returns
, count_rentals
, rental_duration
, rental_last_update
, rental_id
FROM sakila_dwh.fact_rental
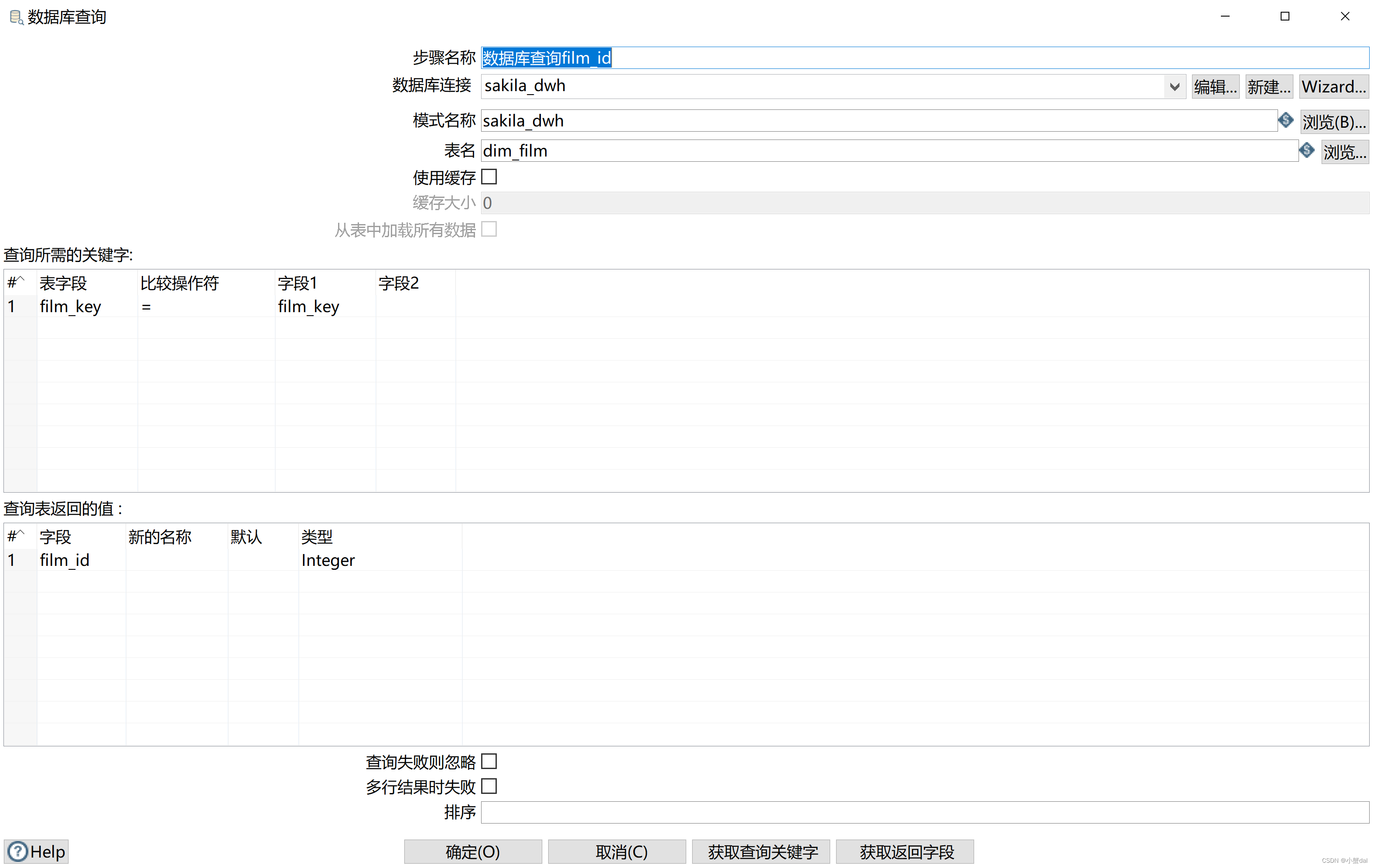
(3)创建【数据库查询film_id】组件并配置
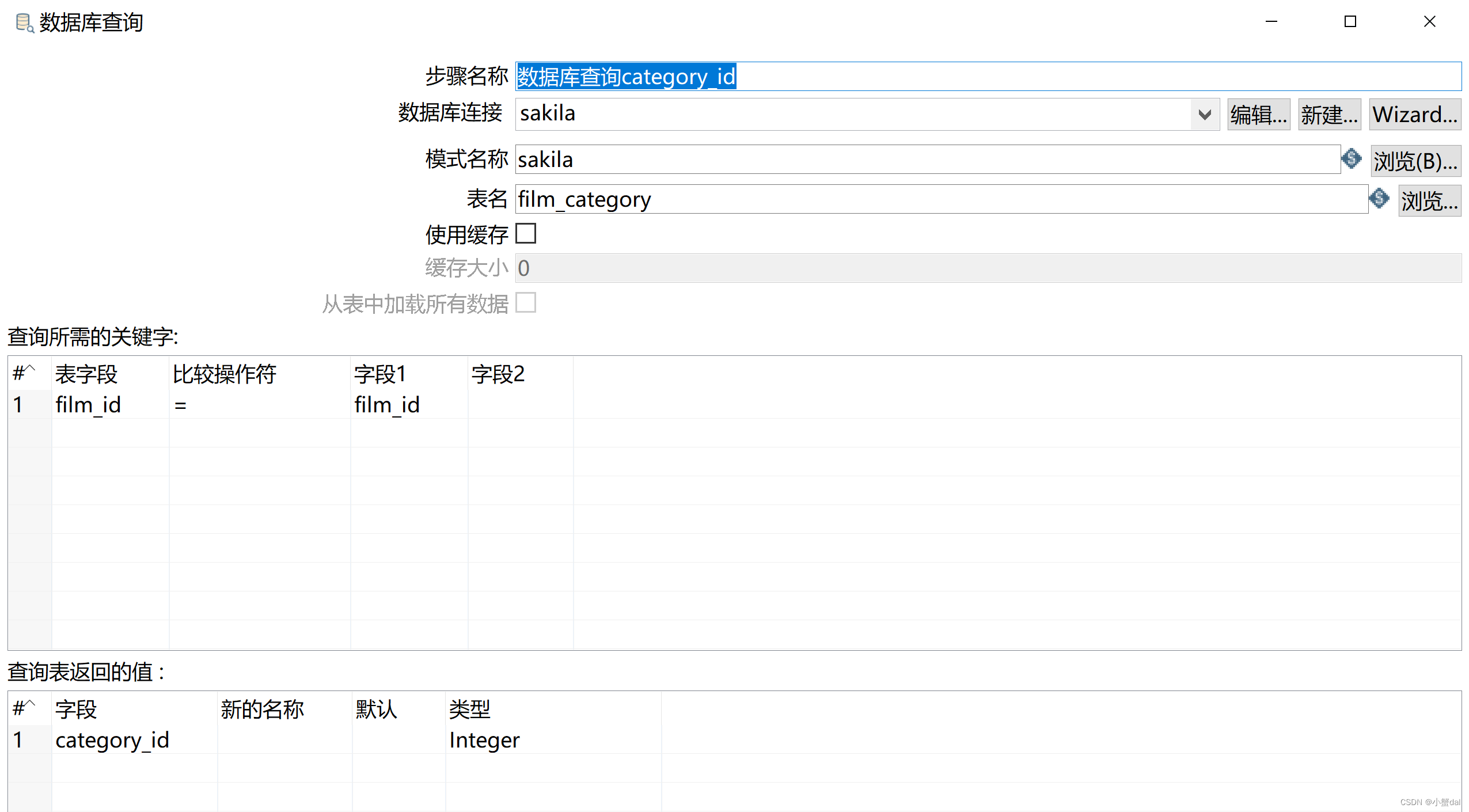
(4)创建【数据库查询category_id】组件,并配置
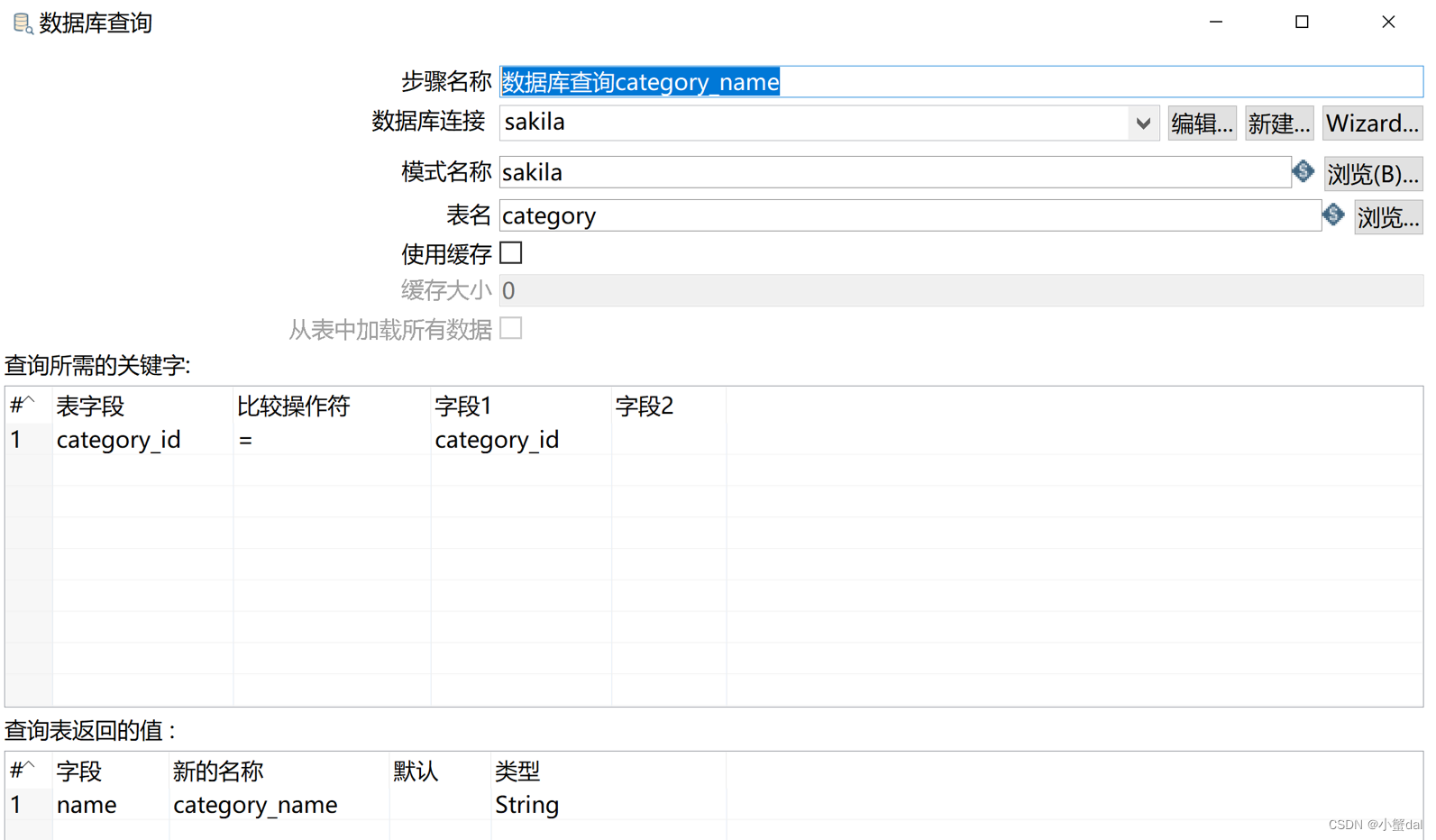
(5)创建【数据库查询category_name】组件,并配置
(6)创建【排序记录】组件
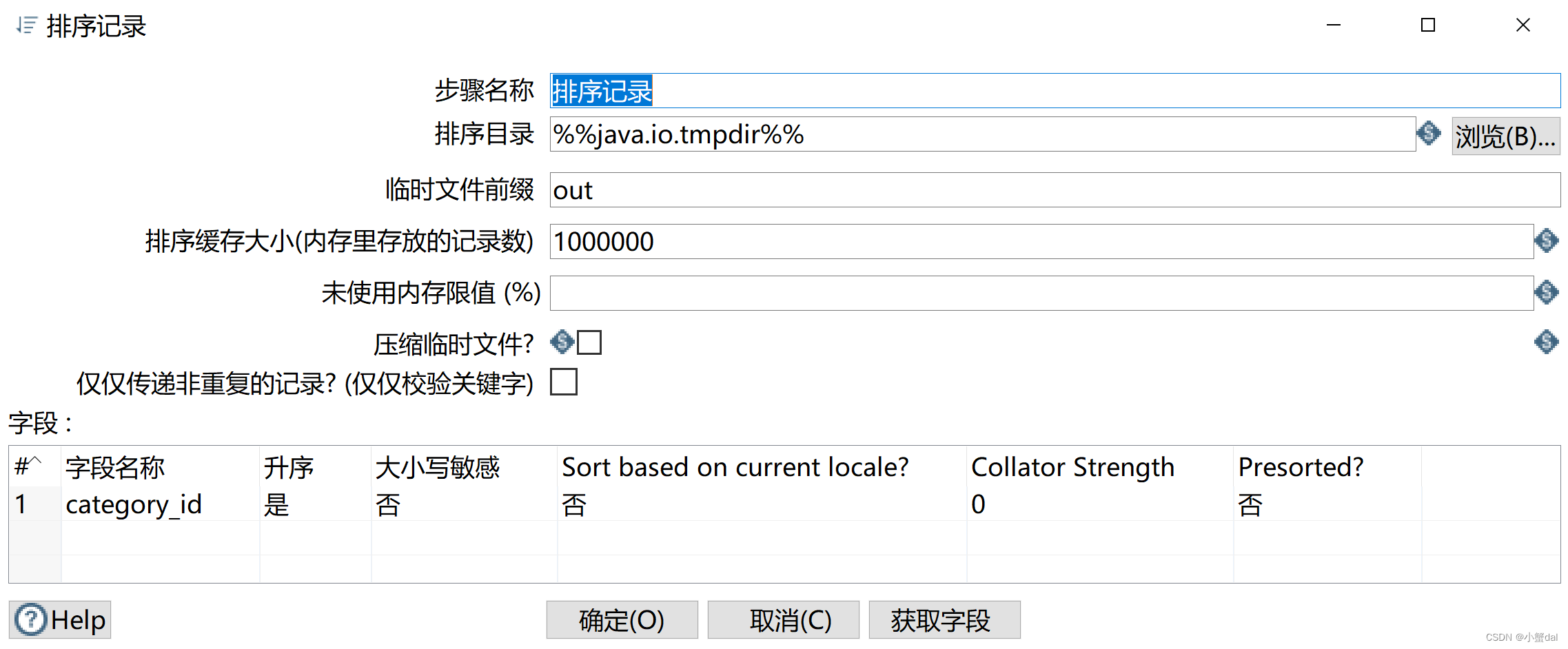
(7)创建【分组】组件
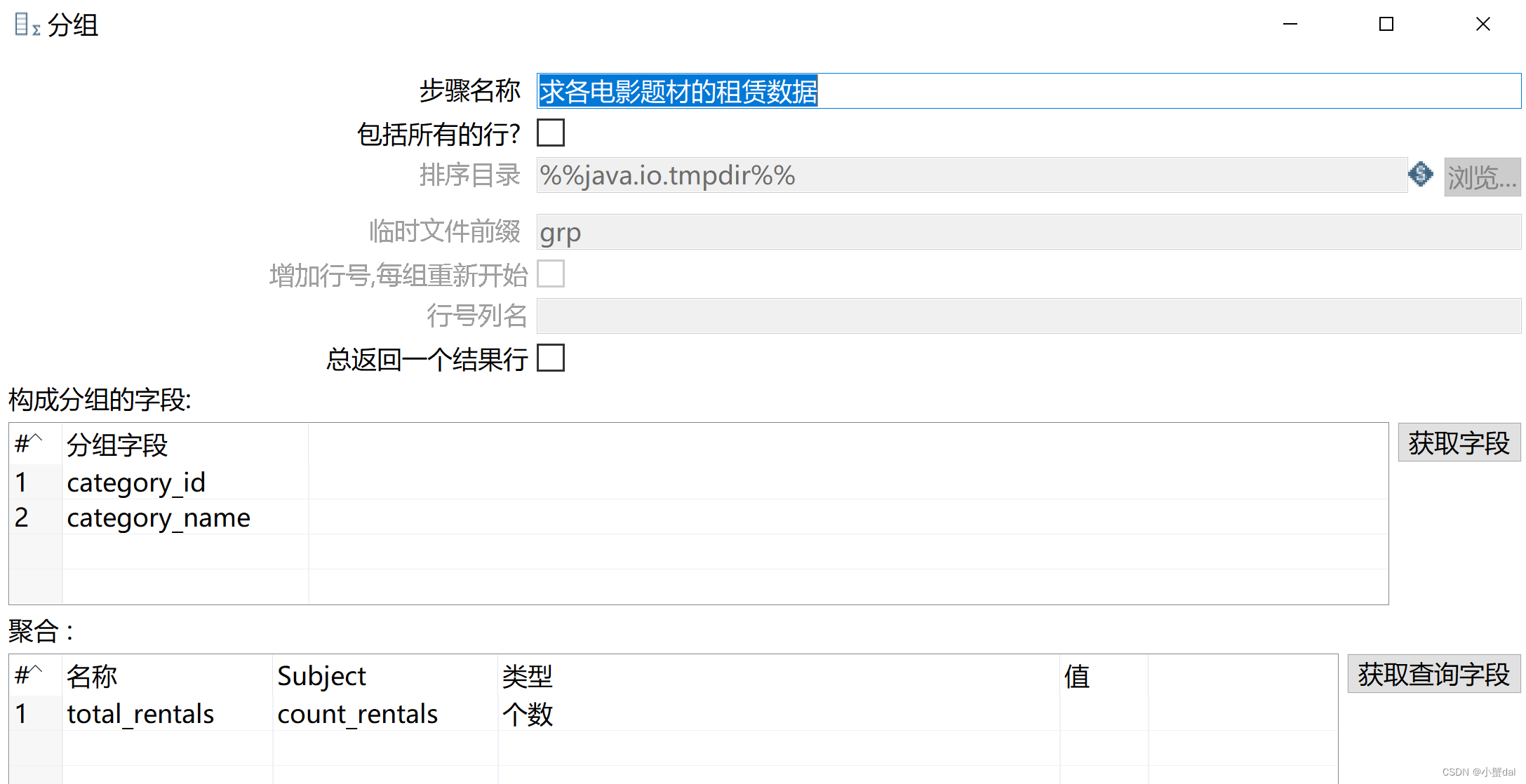
(8)创建【排序记录】组件
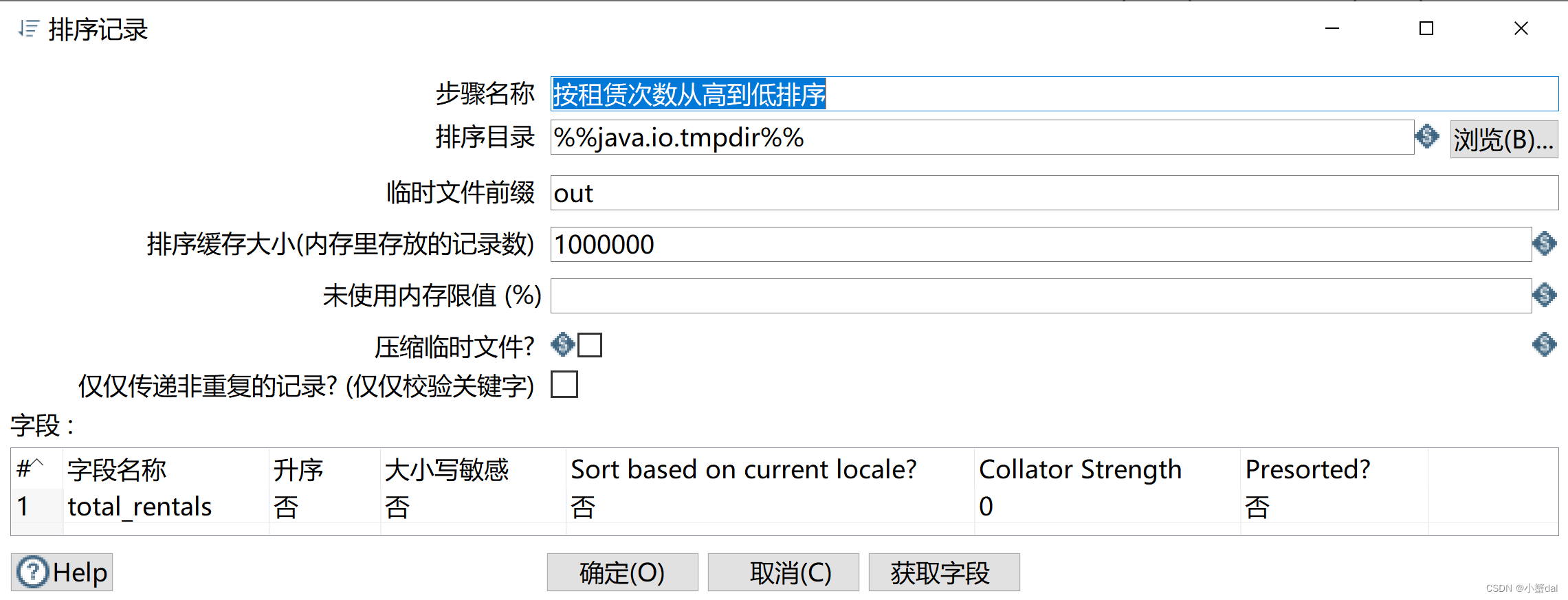
(9)创建【增加序列】组件
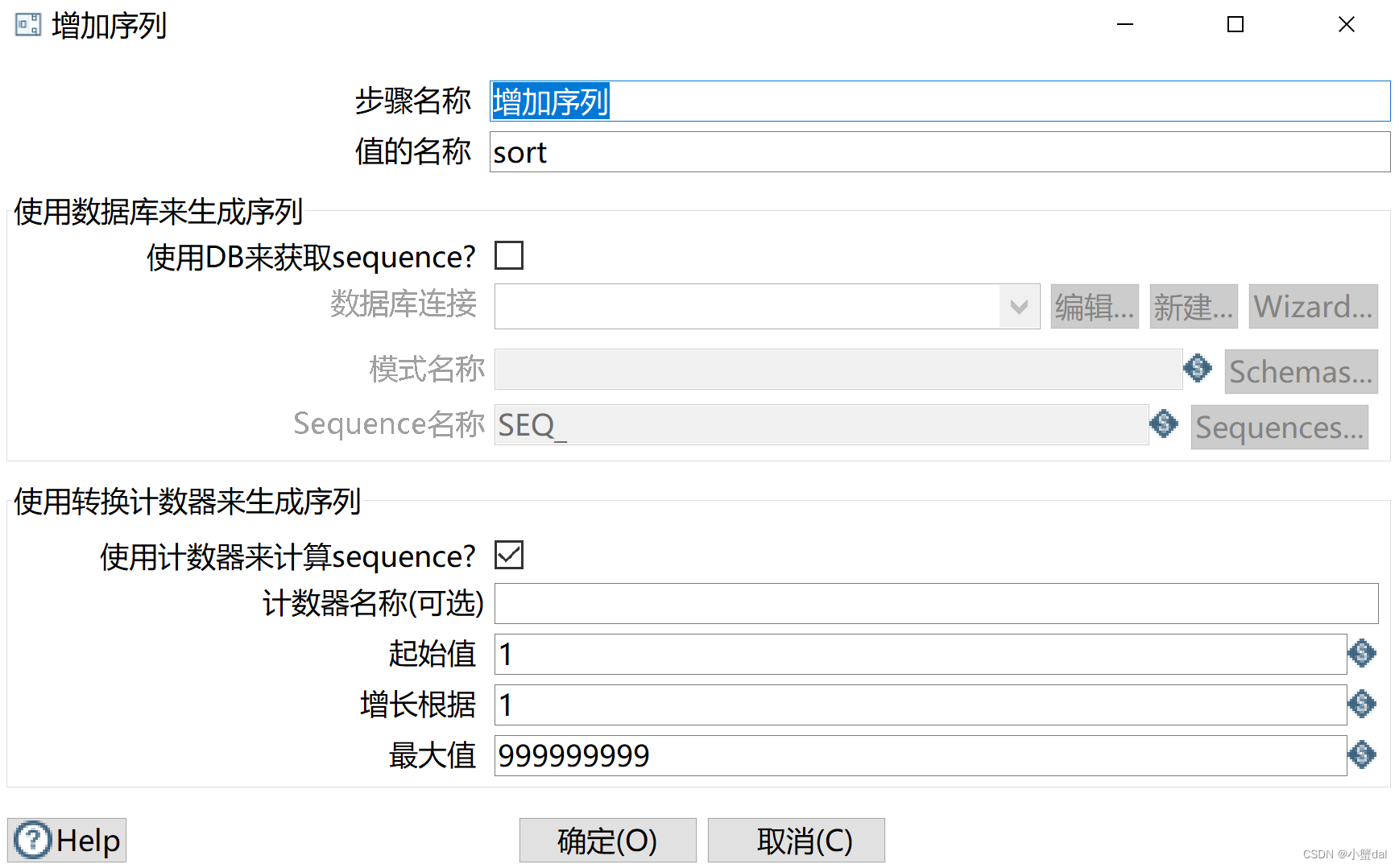
(10)创建【过滤记录】组件
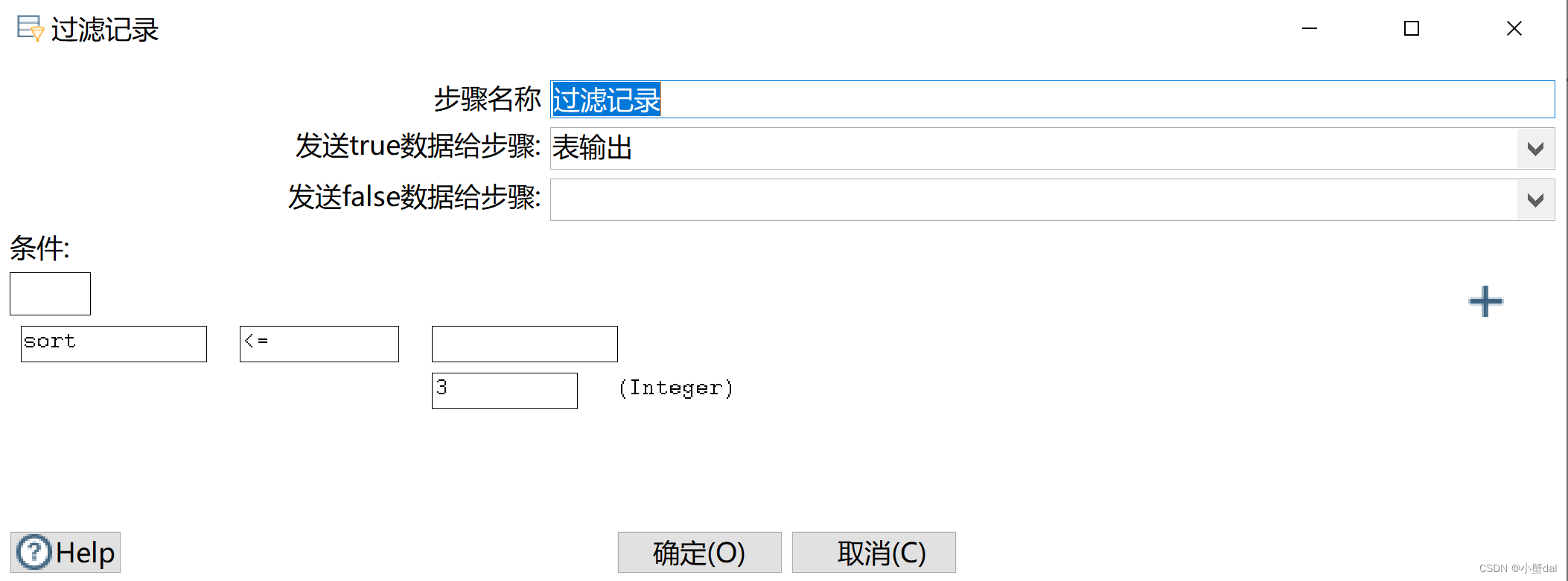
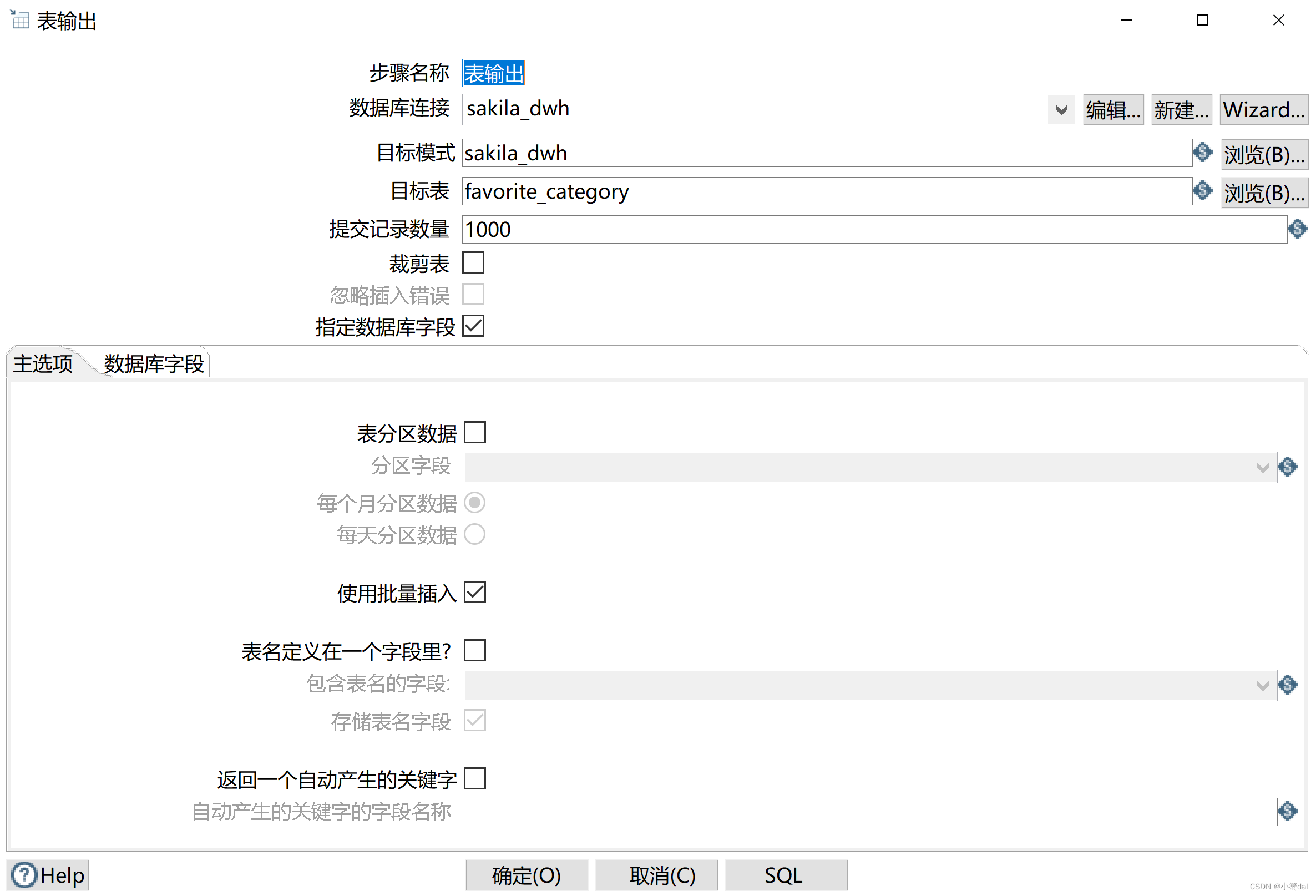
(11)创建【表输出组件】
(12)运行转换并预览结果数据
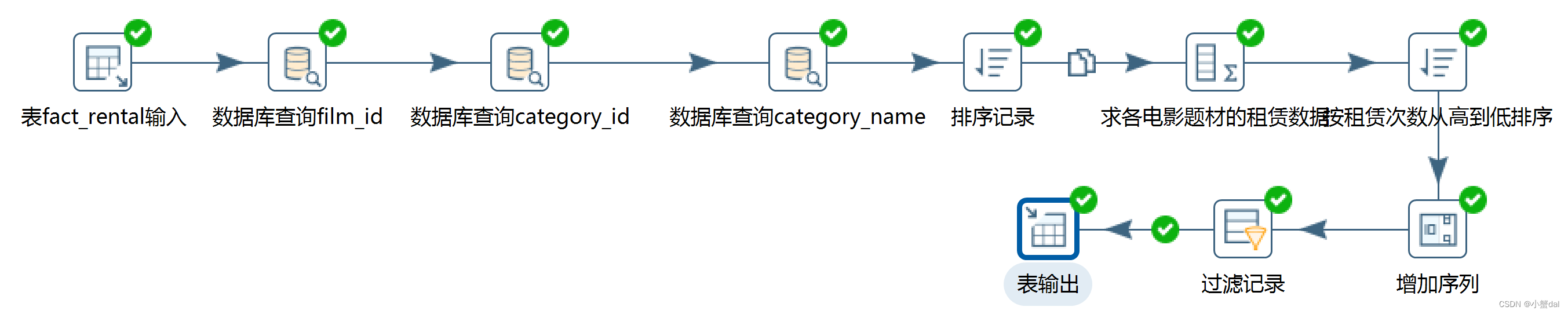
结果:
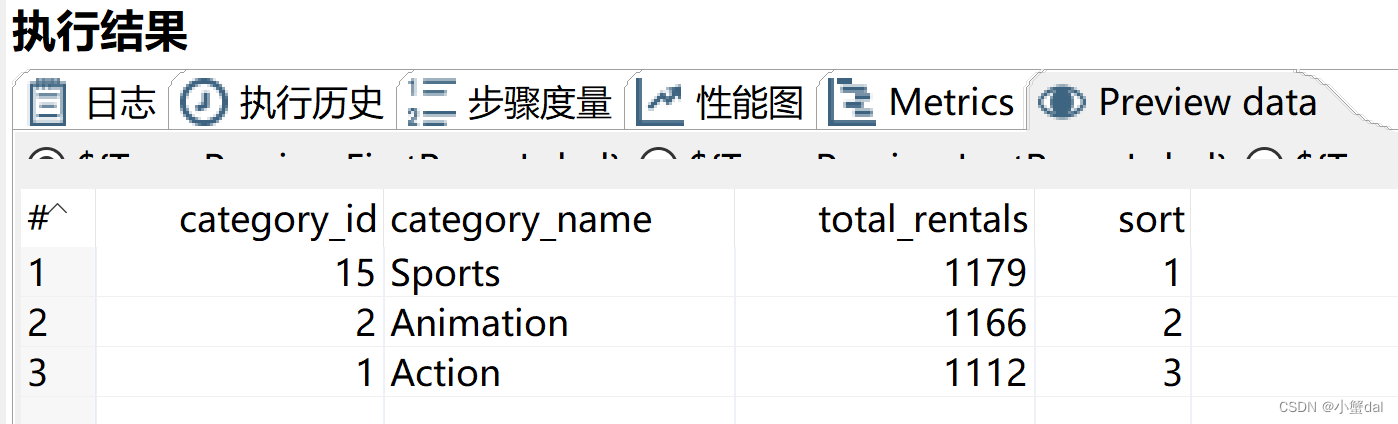
由运行结果可知,最受欢迎的3个电影题材分别为Sports、Animation、Action。
2.3 找到3个最受欢迎电影题材的销售数据
由于只需要最受欢迎的3个电影题材的销售数据,因此先将“fact_rental”表中的非最受欢迎的电影题材的销售数据过滤掉。再按照先“category_id”后“film_id”进行排序,其次按照“film_id”进行分组,然后结合“film_id”进行数据库查询需要输出的数据,最后输出销售数据文件。具体实现步骤如下:
(1)建立新转换【favorite_category_rental】
(2)建立【表输出】组件,导入“fact_rental”表
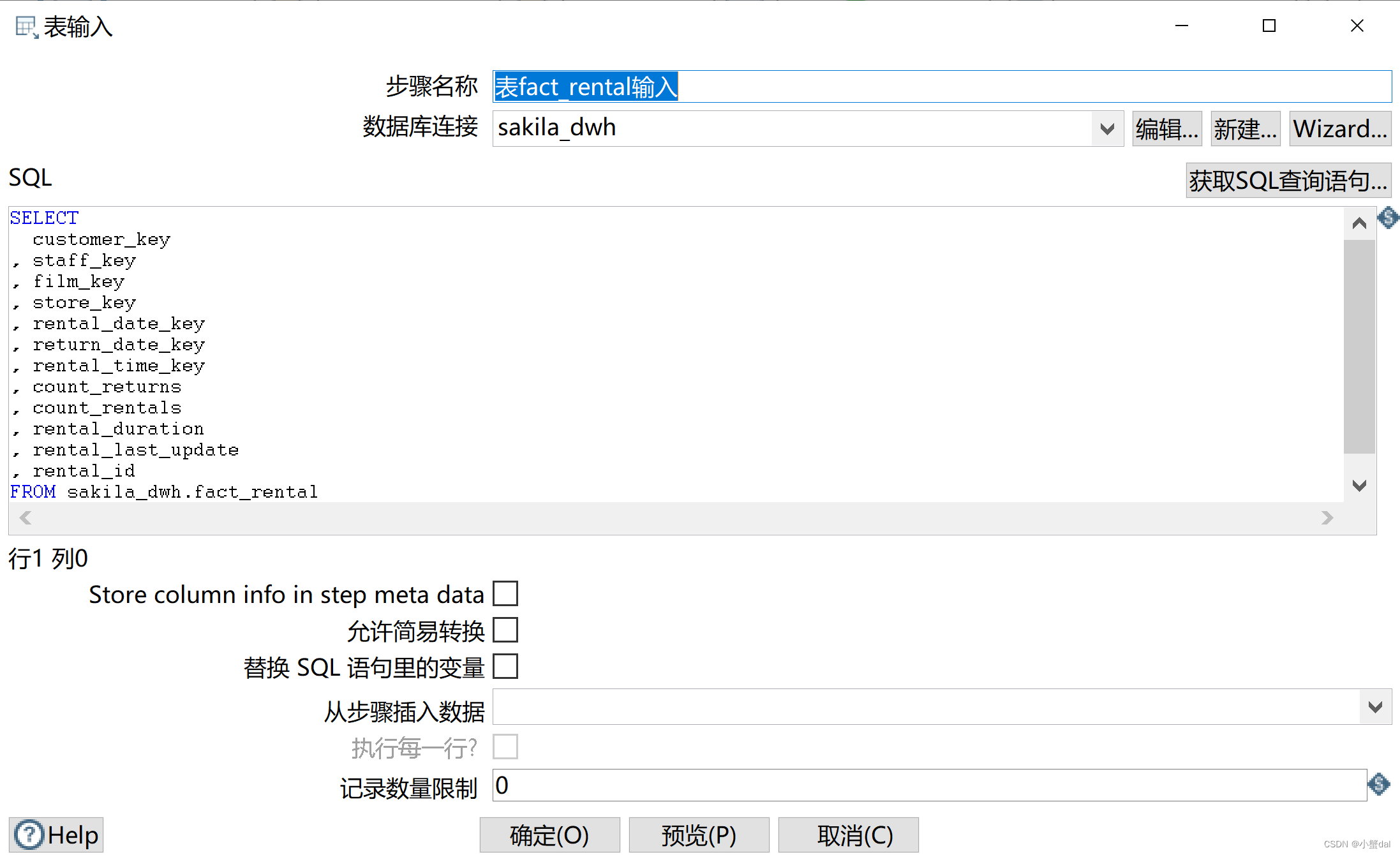
代码:
SELECT
customer_key
, staff_key
, film_key
, store_key
, rental_date_key
, return_date_key
, rental_time_key
, count_returns
, count_rentals
, rental_duration
, rental_last_update
, rental_id
FROM sakila_dwh.fact_rental
(3)建立【数据库查询film_id】组件
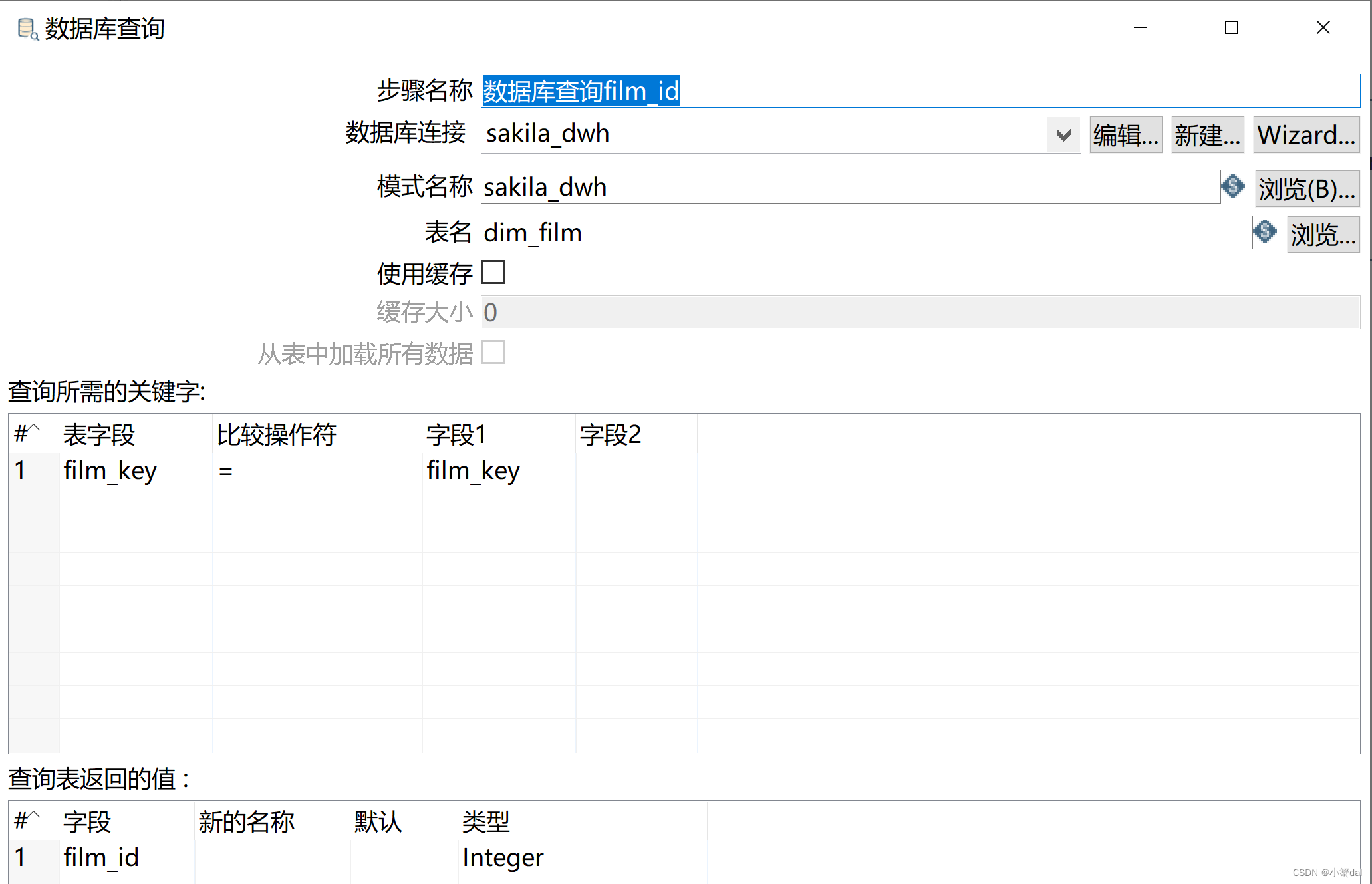
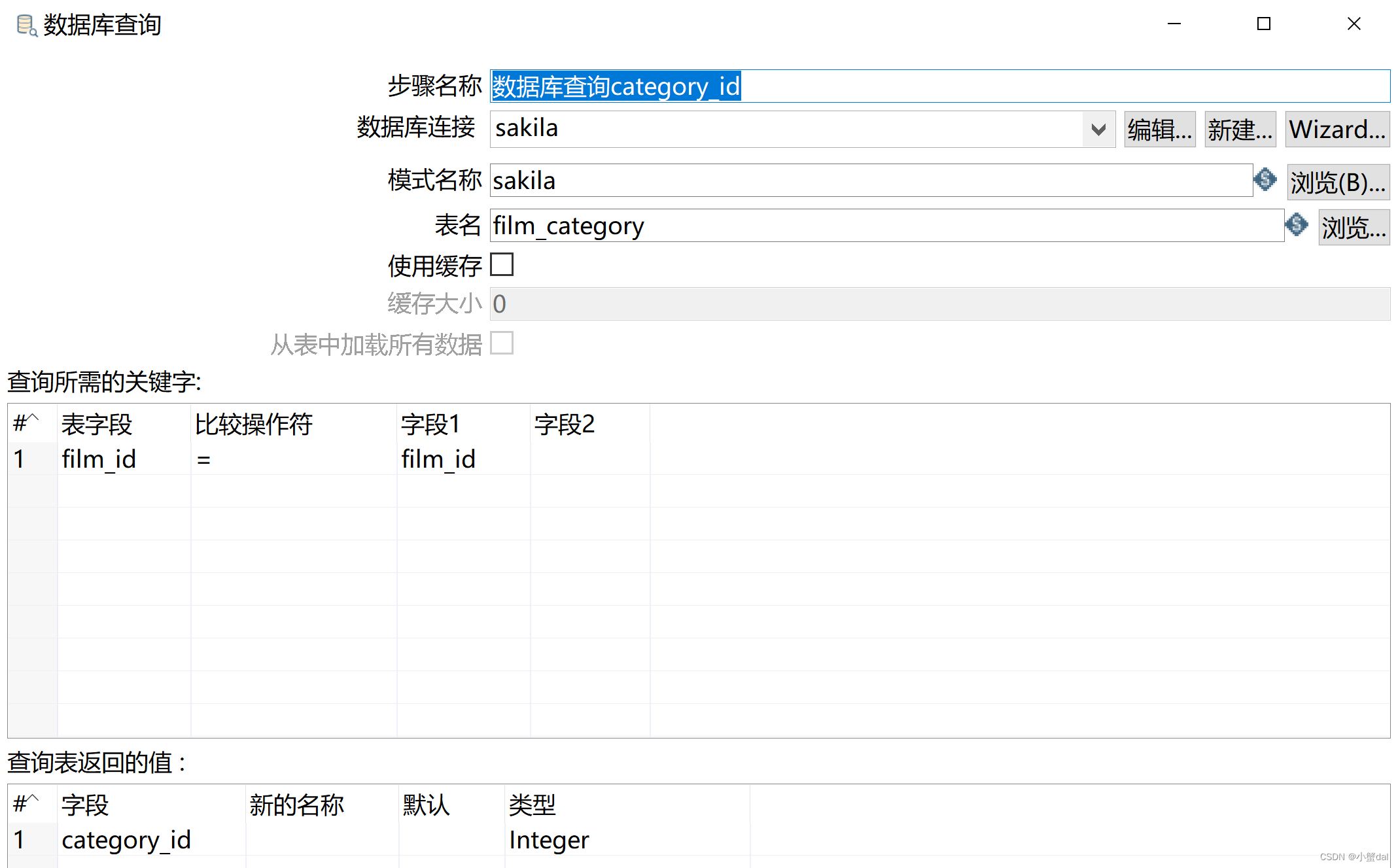
(4)建立【数据库查询category_id】
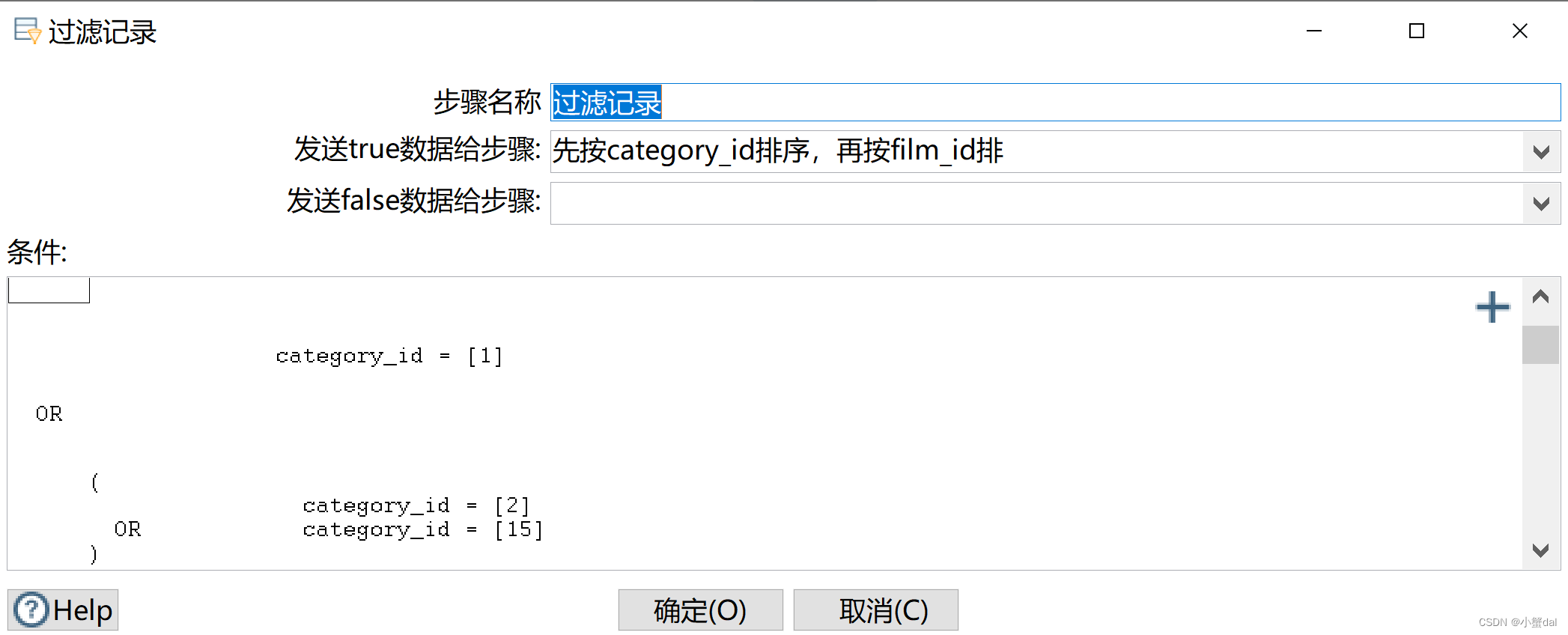
(5)建立【过滤记录】组件,过滤掉非最受欢迎的3个电影题材的销售记录
(6)建立【排序记录】组件
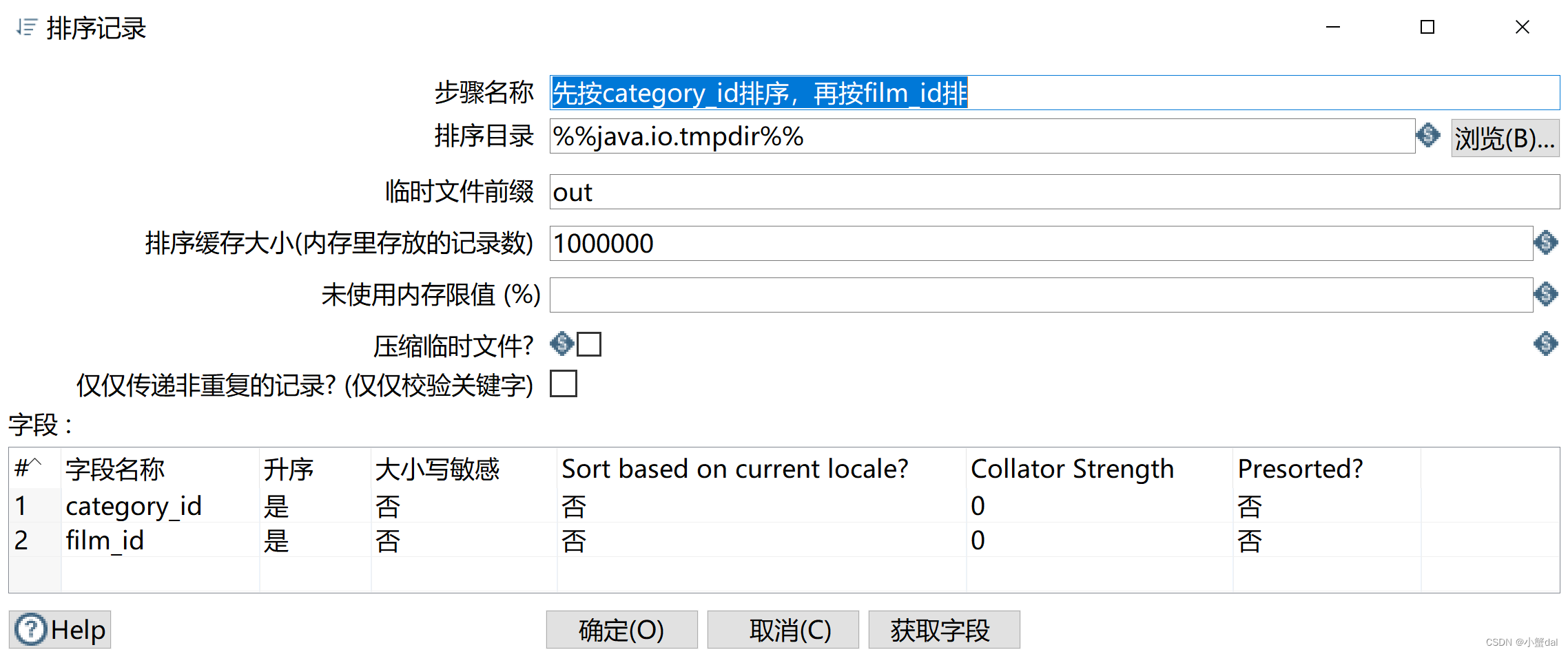
(7)建立【分组】组件
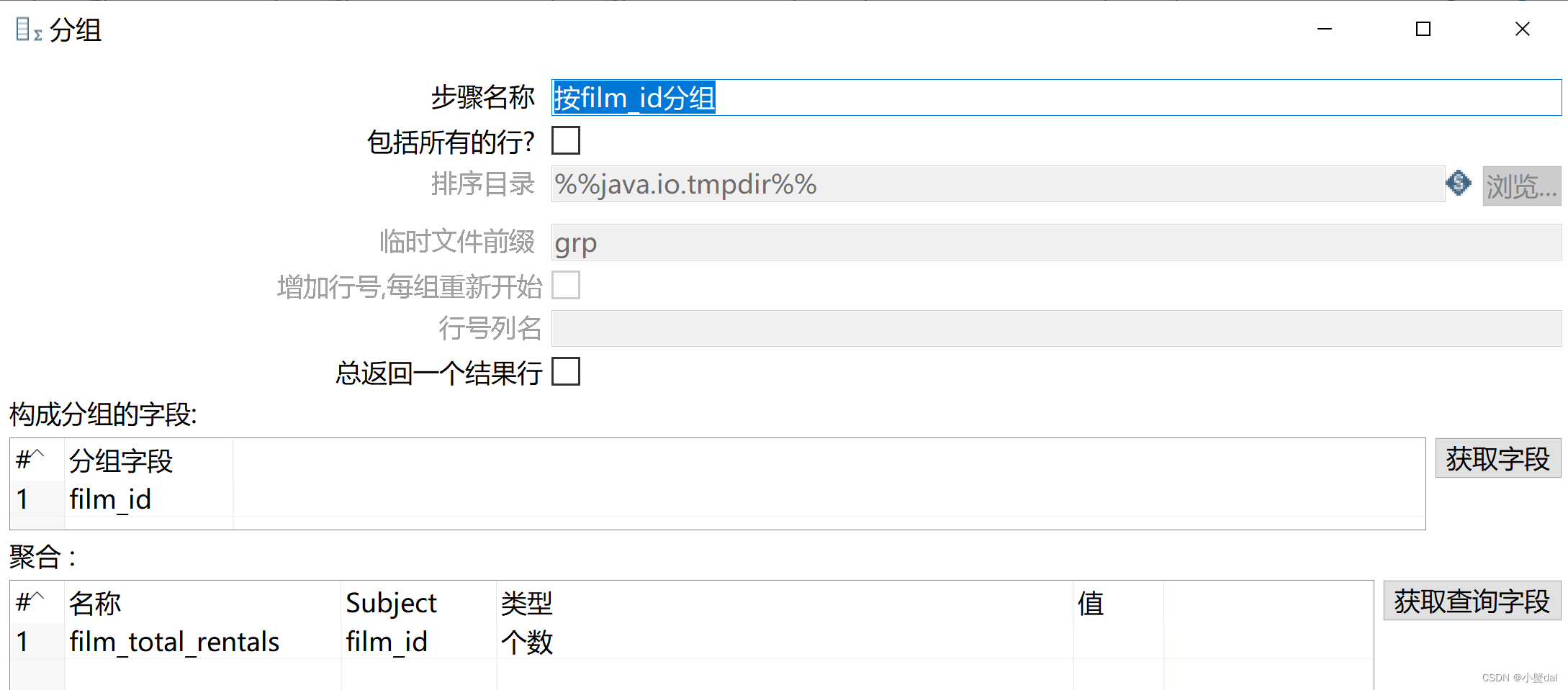
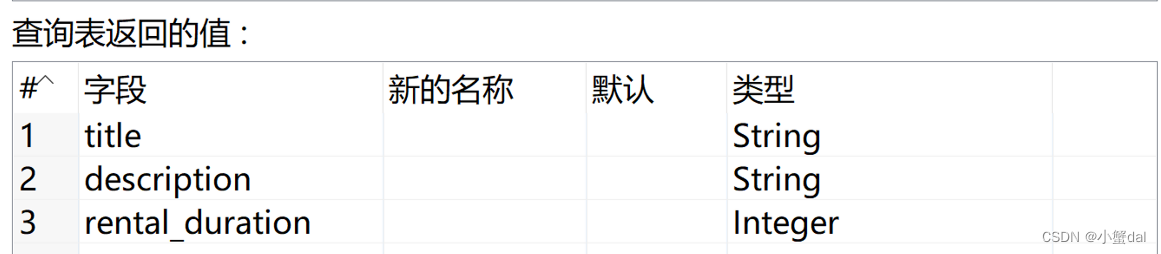
(8)建立【数据库查询】组件
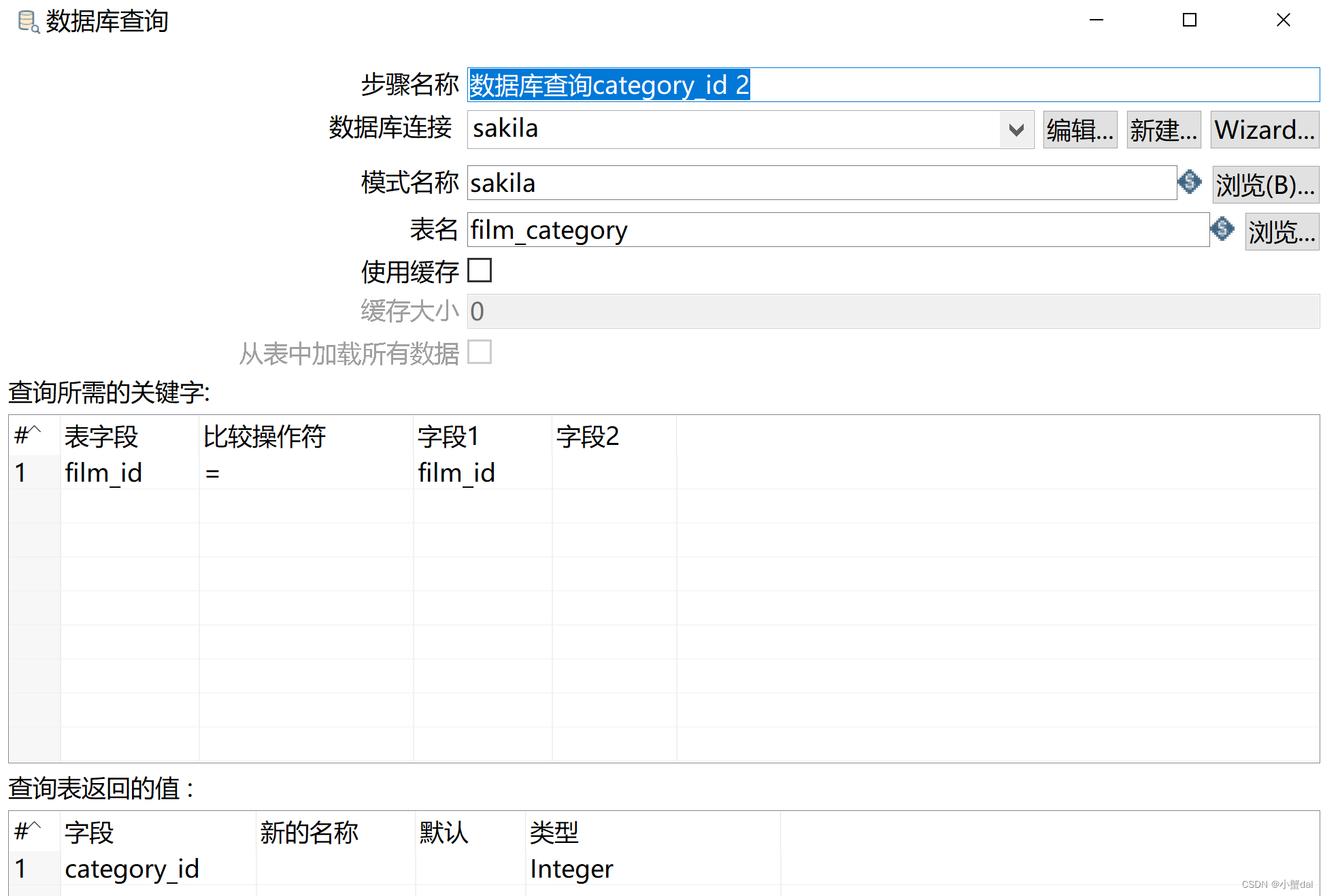
(9)建立【数据库查询】组件
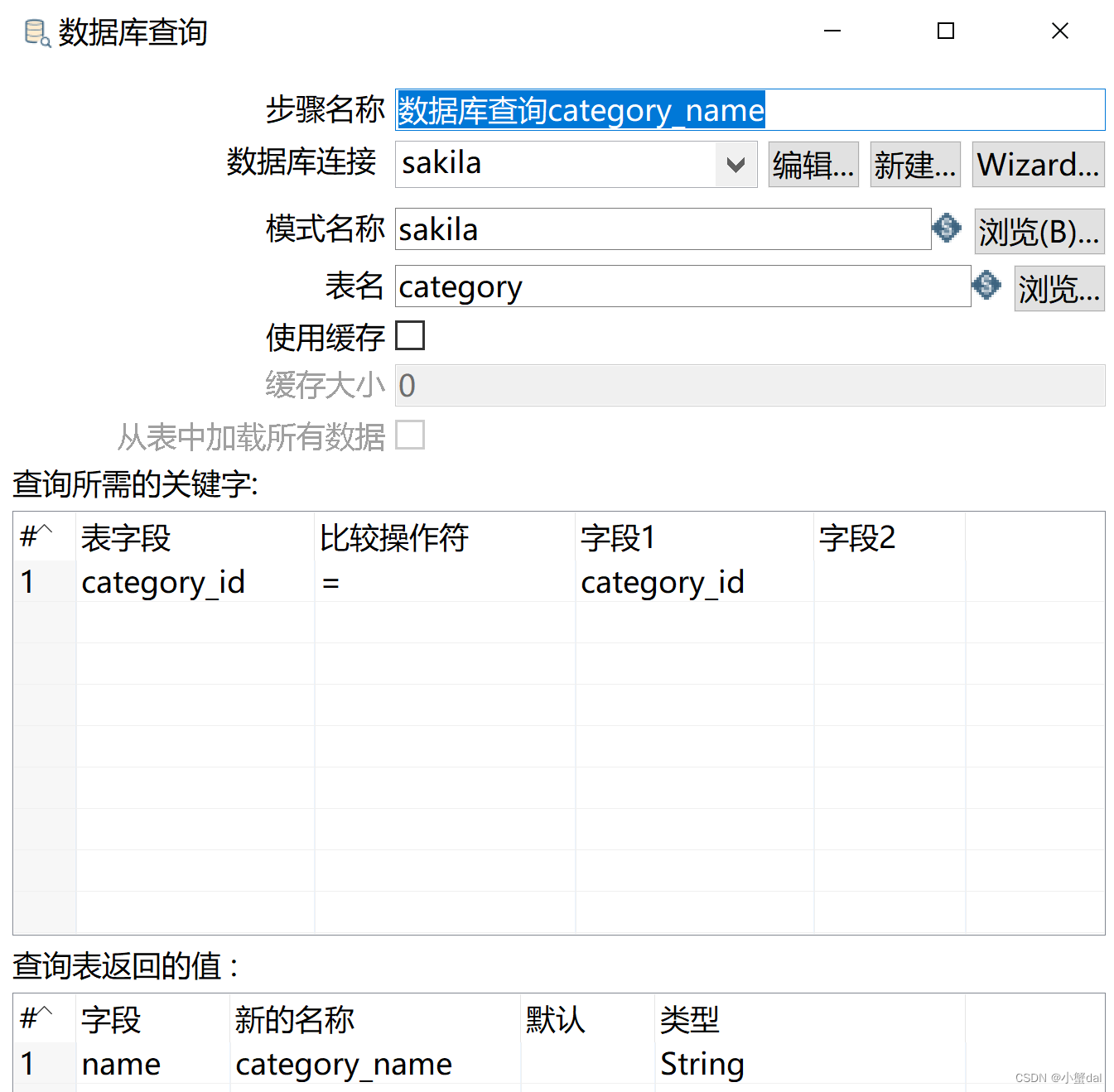
(10)建立【数据库查询】
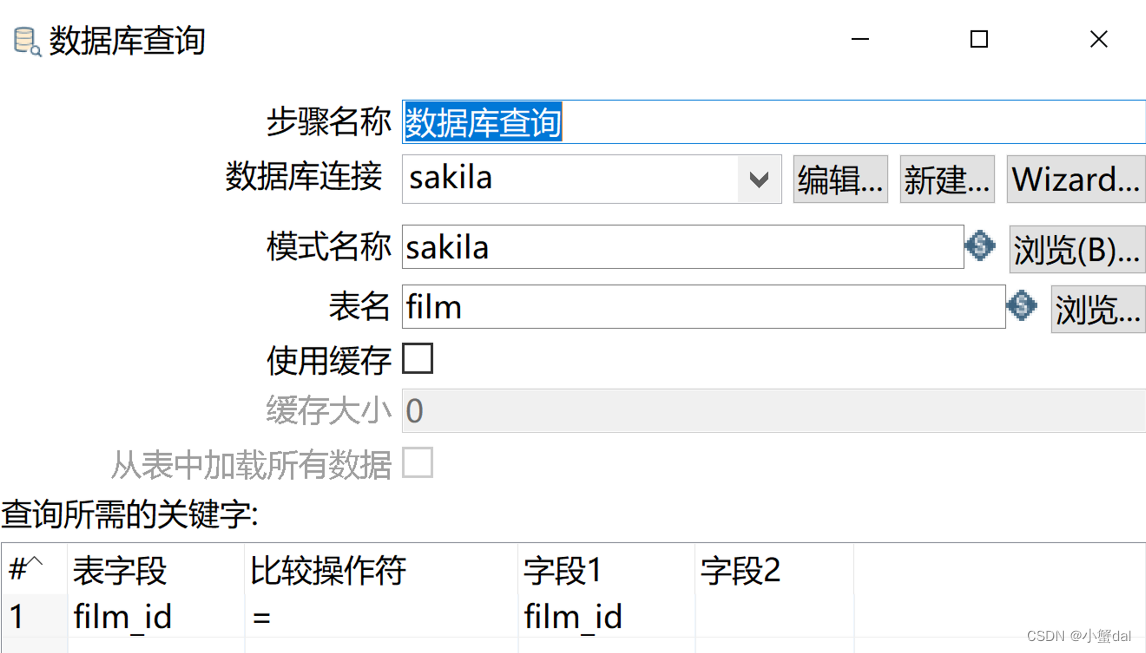
(11)建立【Excel输出】组件
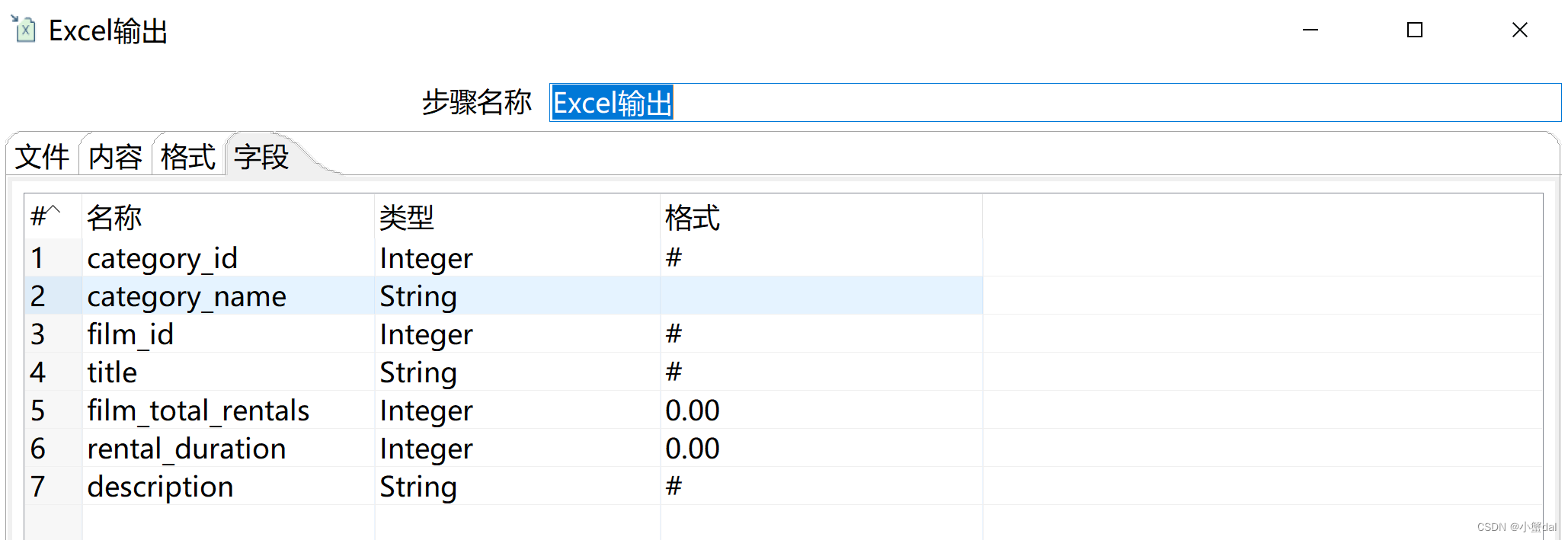
然后打开Excel文件,另存为CSV文件
(12)运行转换,预览结果数据

结果数据:
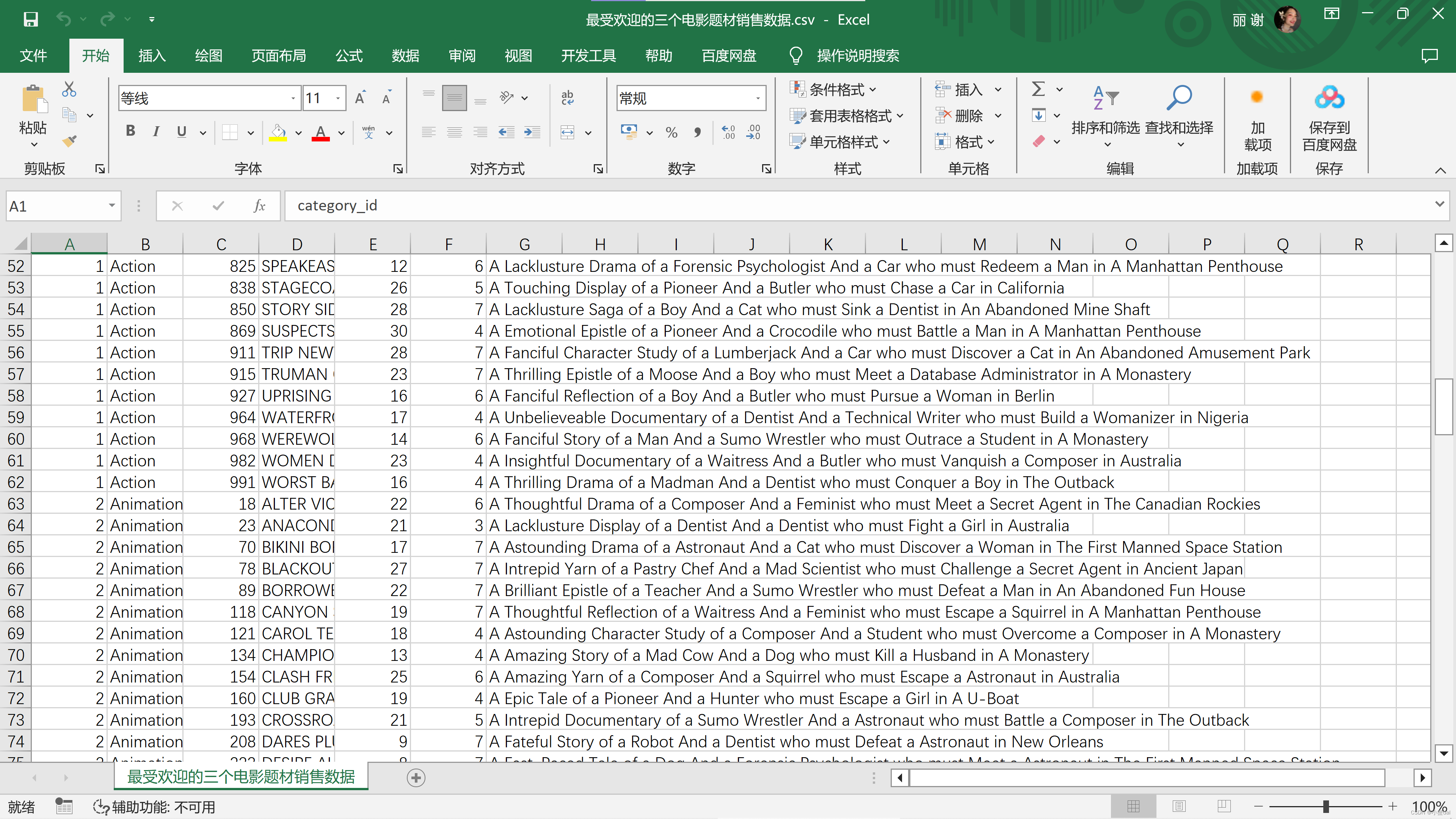
2.4 找最受欢迎的电影明星
根据sakila_dwh数据仓库中“fact_rental”表中包含的销售数据,结合sakila数据库中表“dim_film”“actor”找到每条销售记录对应的film_id、actor_id,再按照actor_id进行排序、分组聚合,得到各个明星的销售数据,然后排序,从而找到最受欢迎的电影明星。具体实现步骤如下:
(1)建立新转换【favorite_actor】
(2)建立【表输入】组件
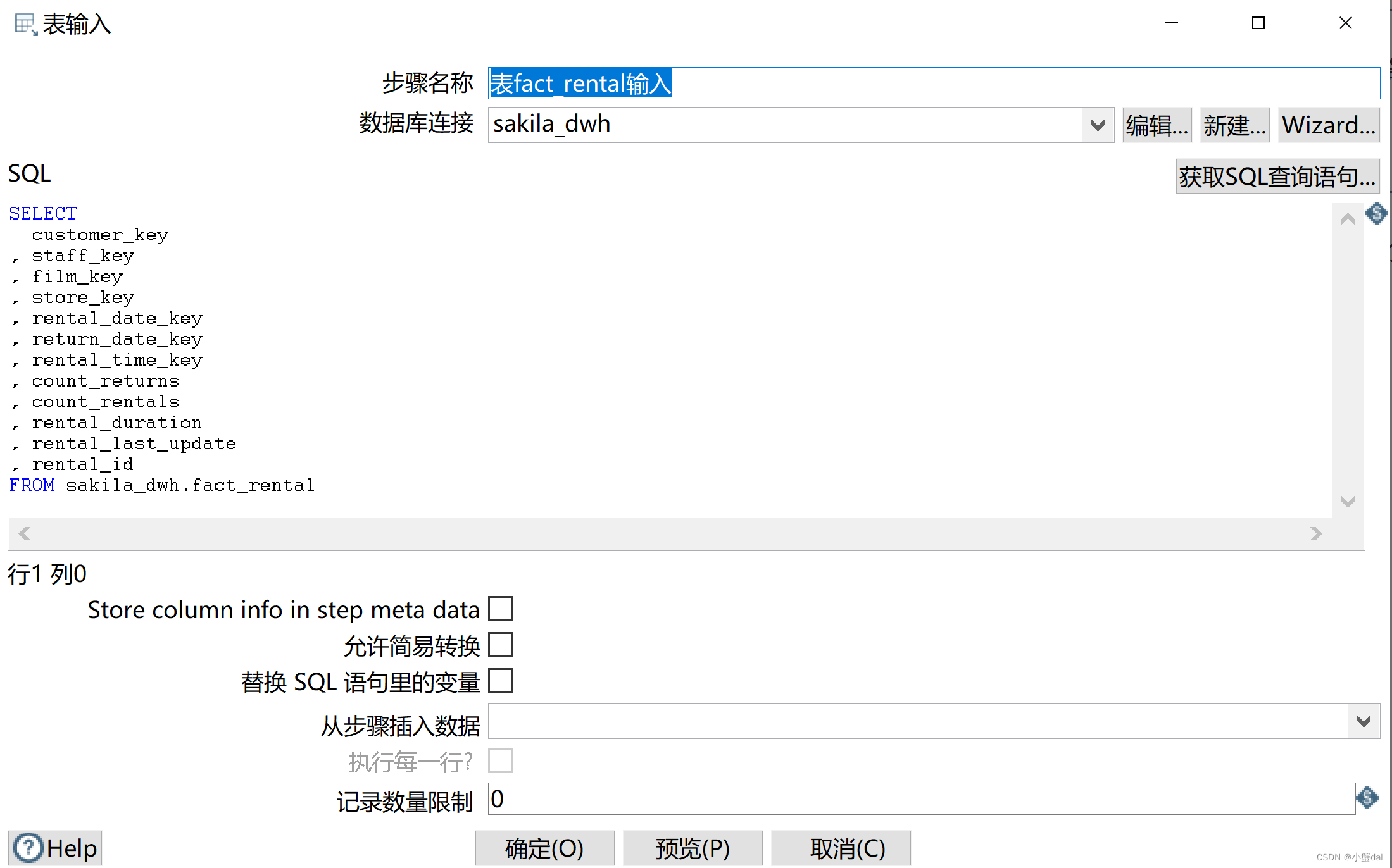
代码:
SELECT
customer_key
, staff_key
, film_key
, store_key
, rental_date_key
, return_date_key
, rental_time_key
, count_returns
, count_rentals
, rental_duration
, rental_last_update
, rental_id
FROM sakila_dwh.fact_rental(3)建立【数据库查询】组件
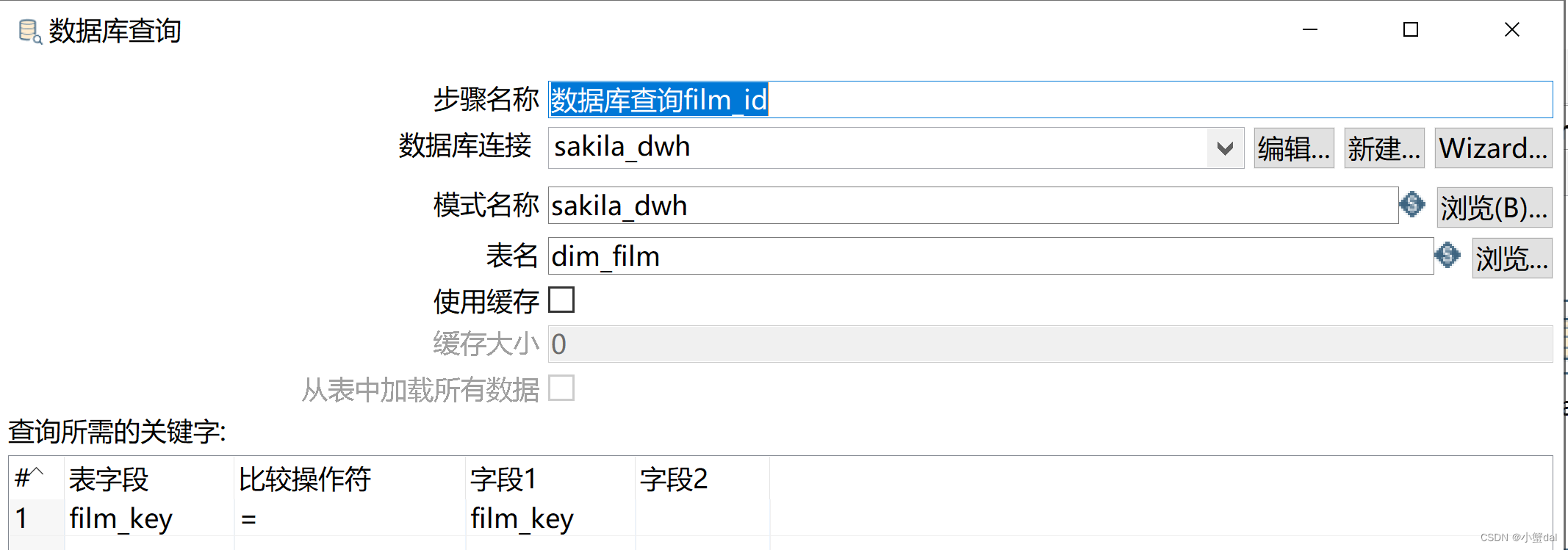

(4)建立【数据库查询】组件
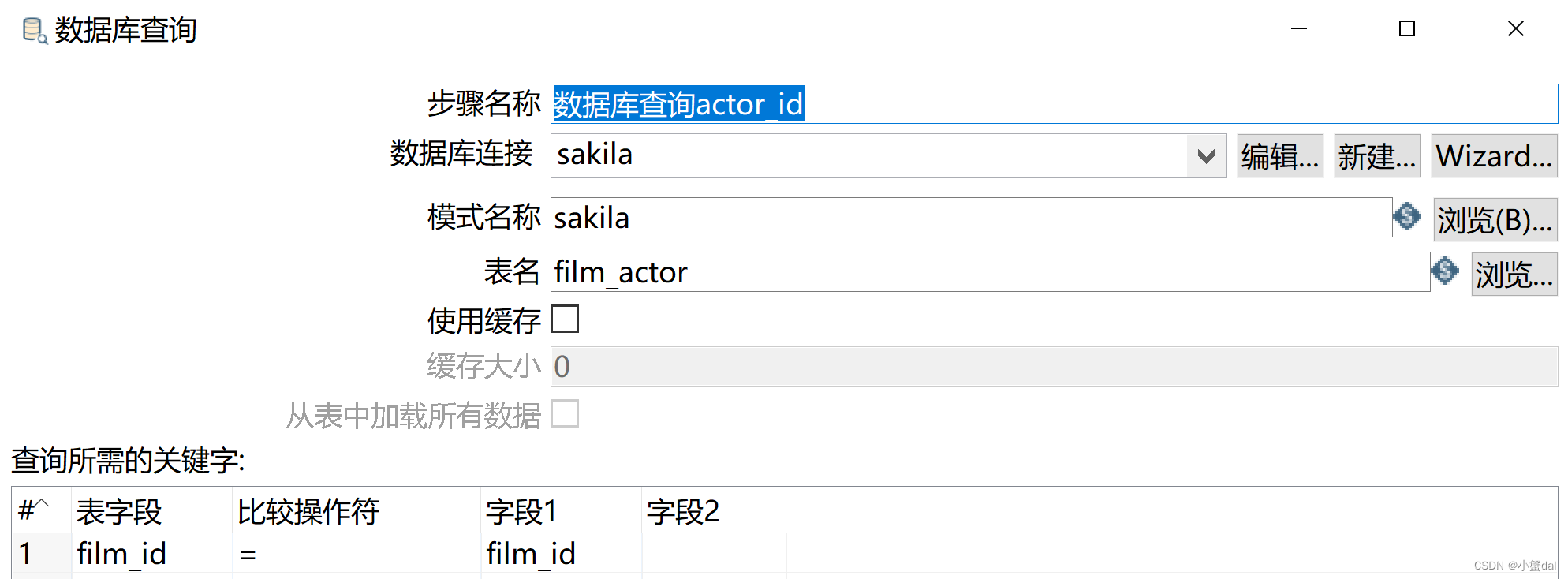

(5)建立【数据库查询】组件
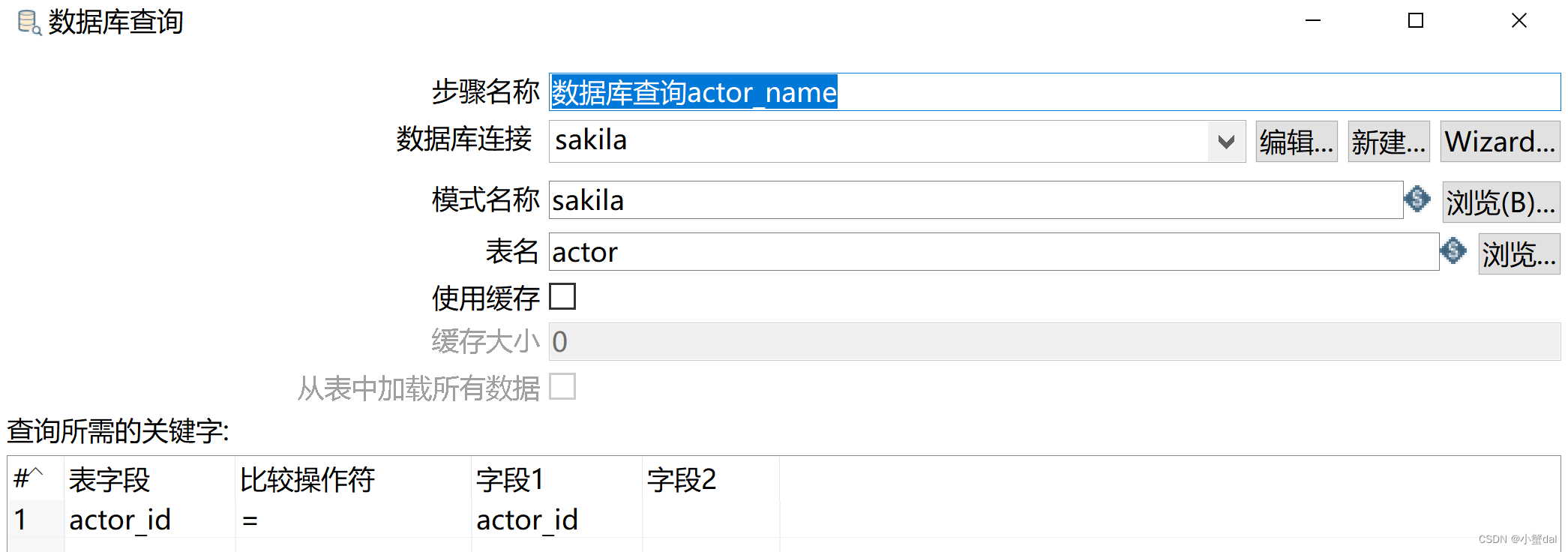

(6)建立【排序记录】
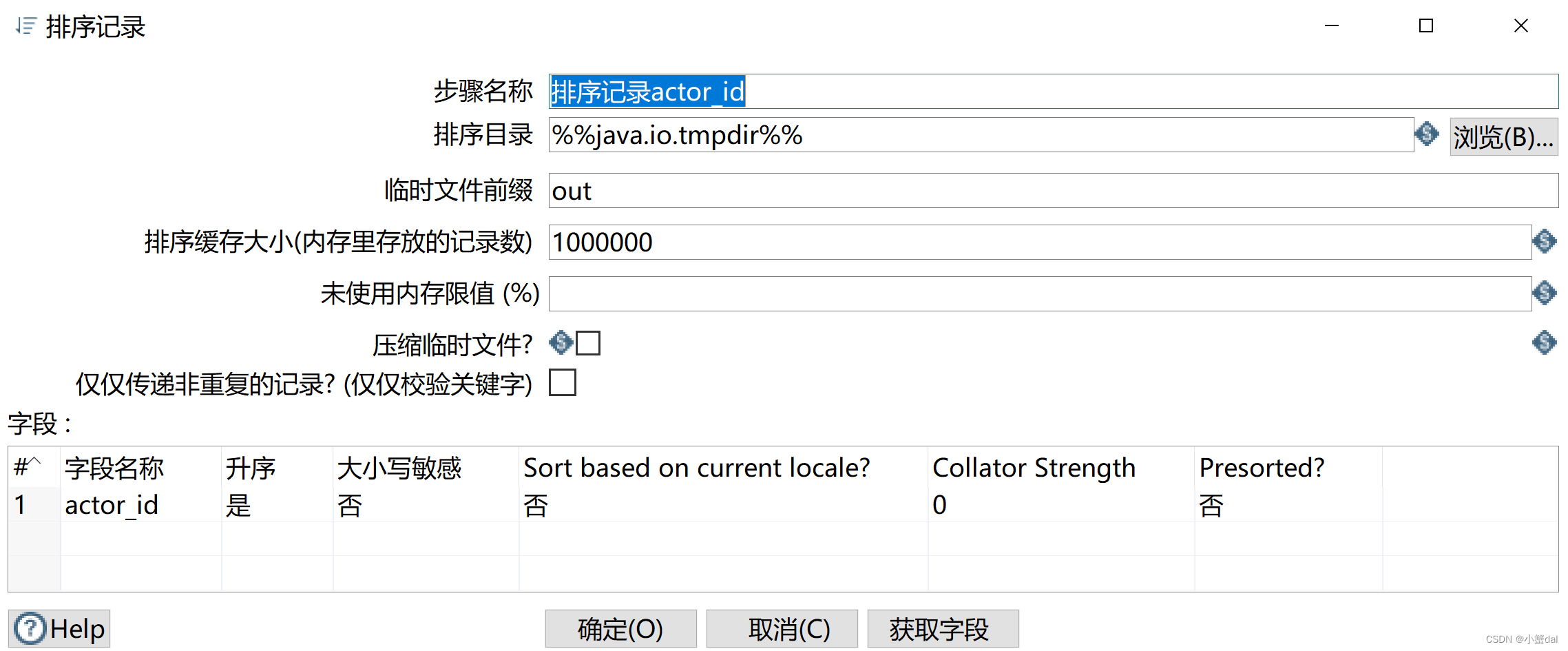
(7)建立【分组】组件
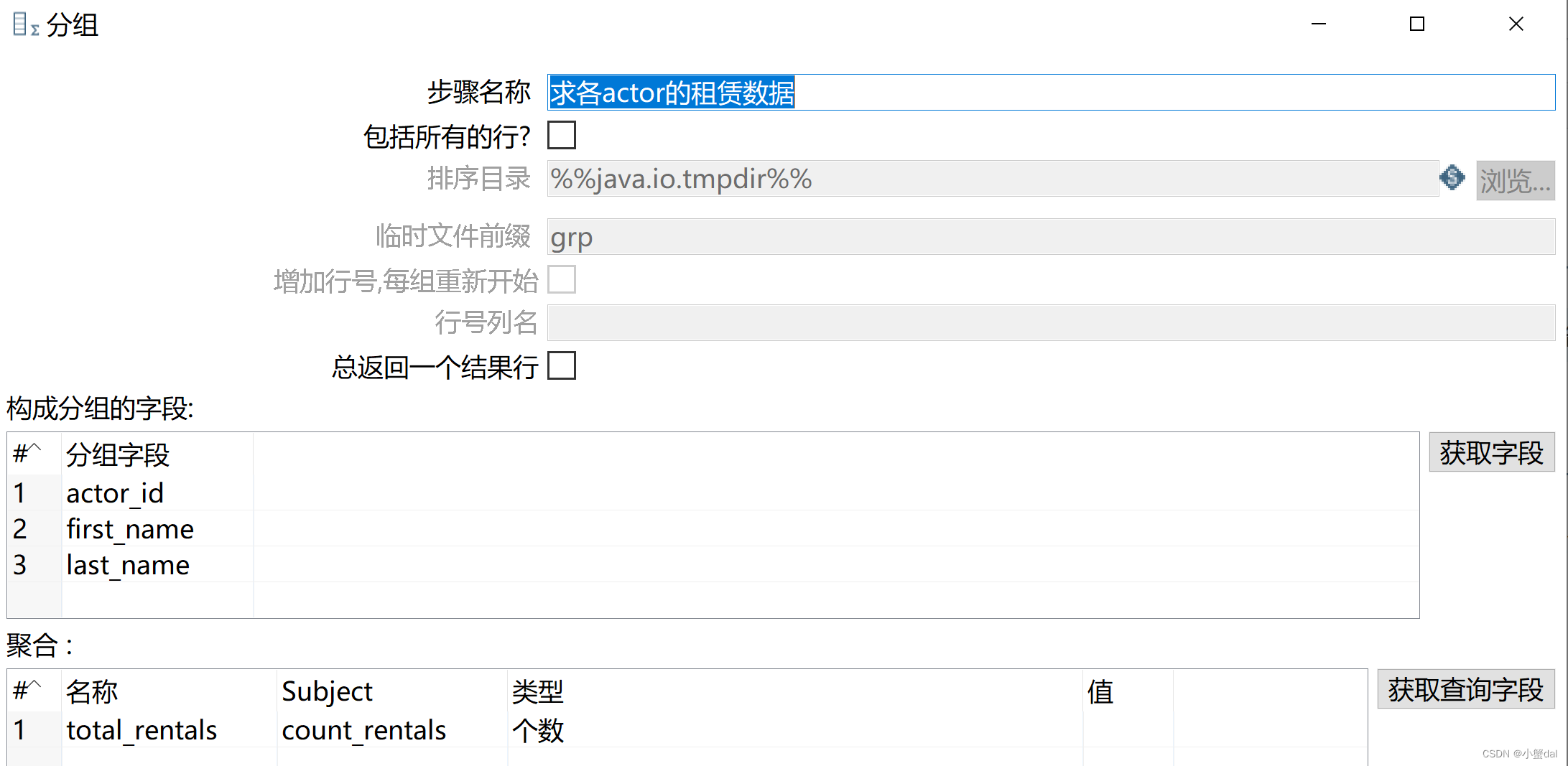
(8)建立【排序记录】组件
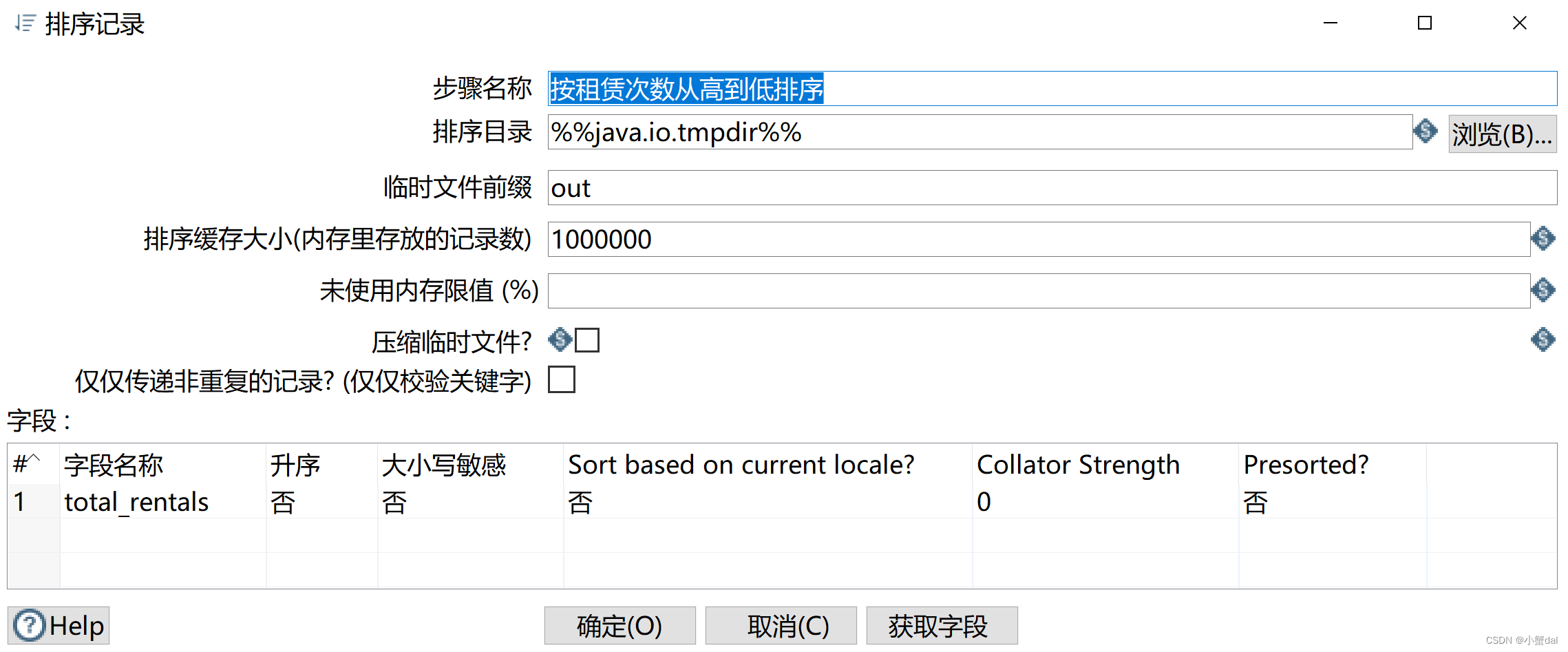
(9)建立【过滤】组件
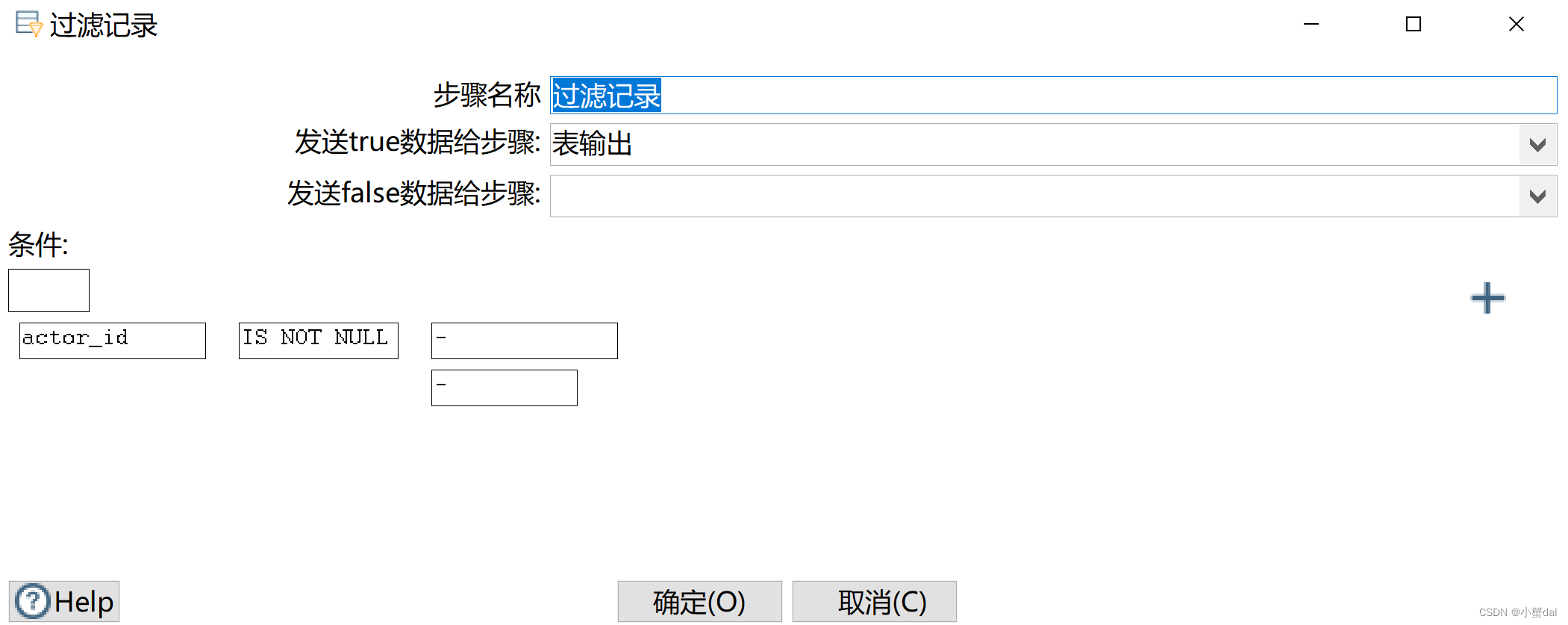
(10)建立【表输出】组件
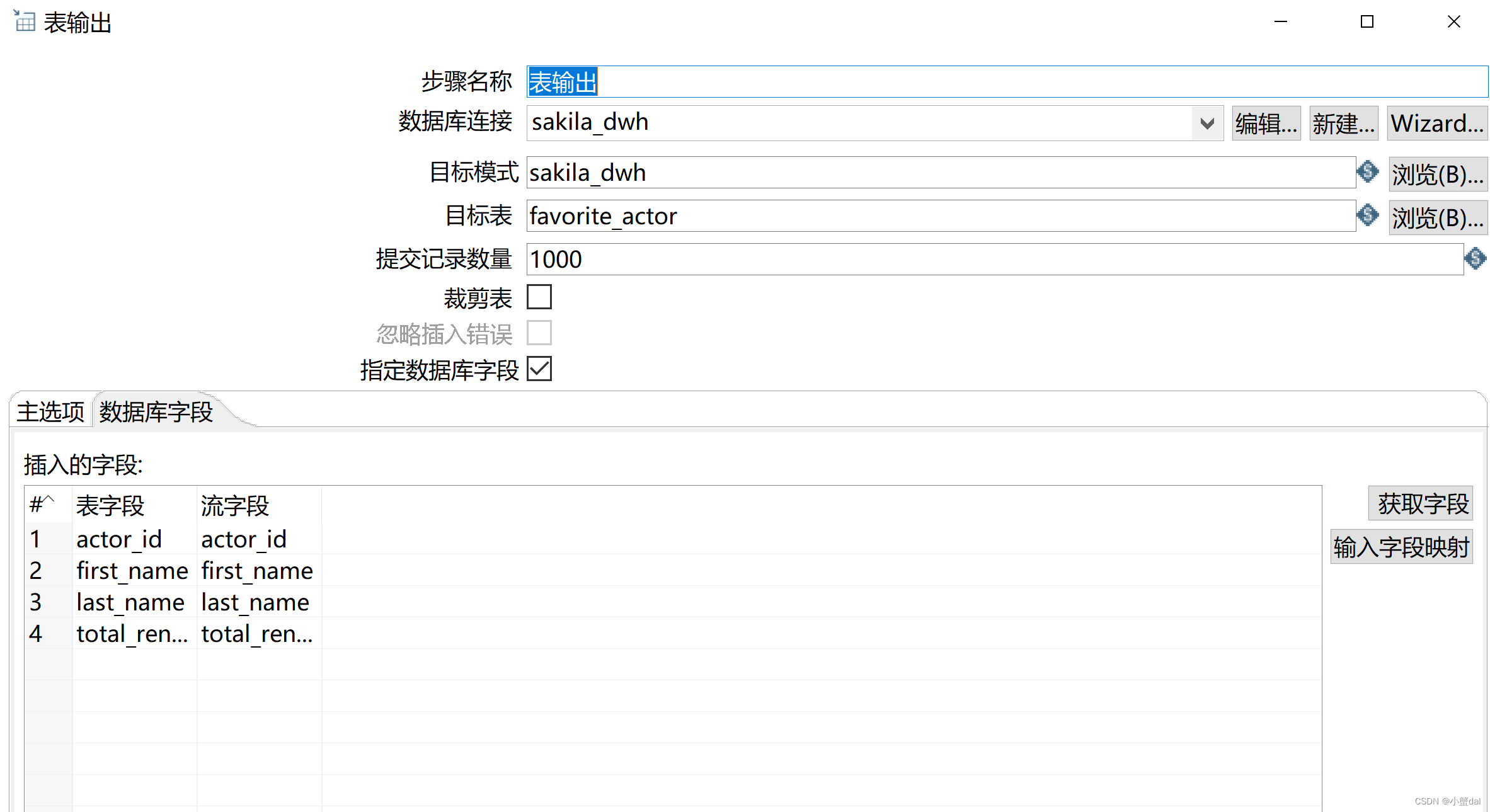
(11)运行转换,并预览结果数据

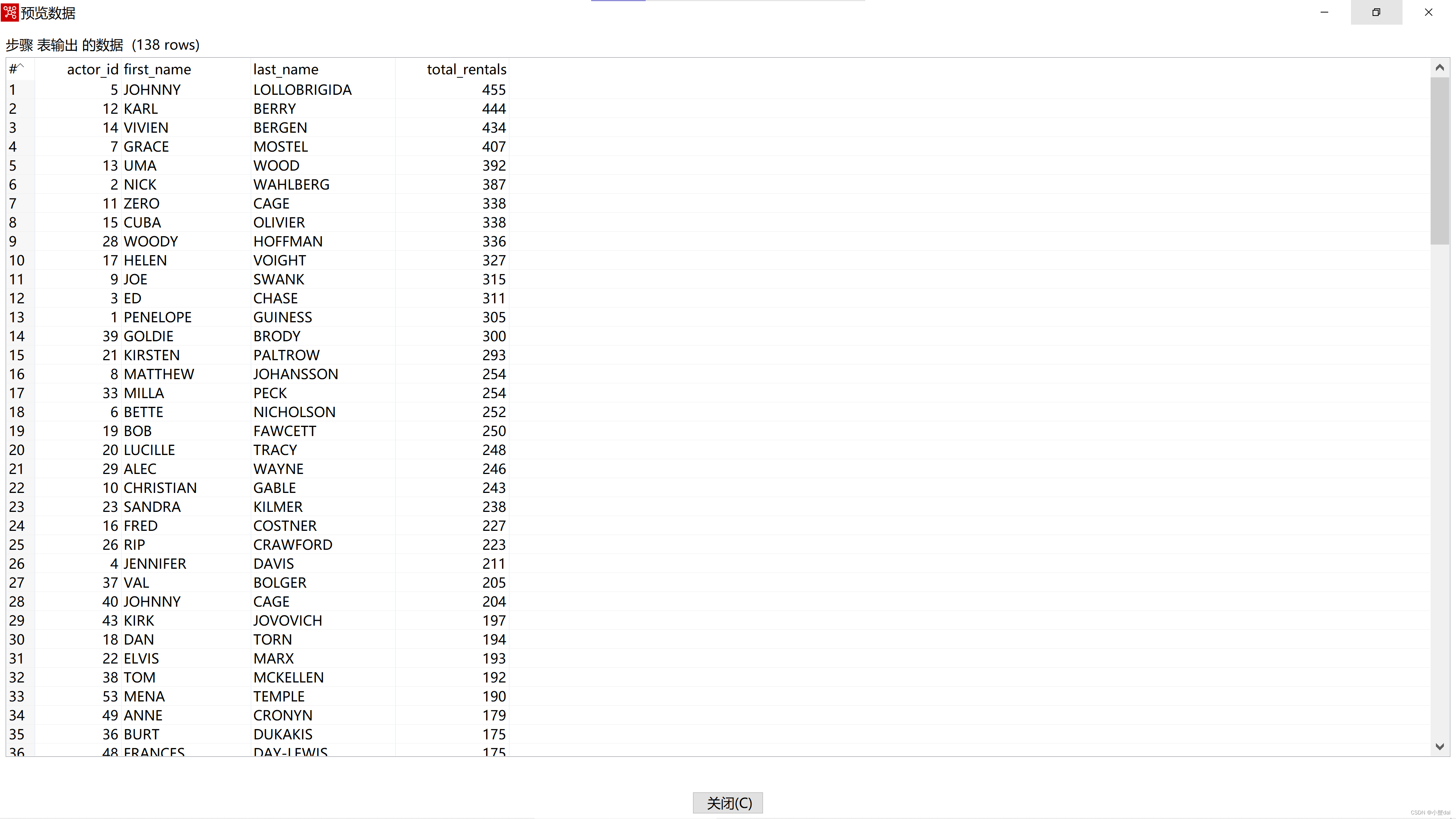
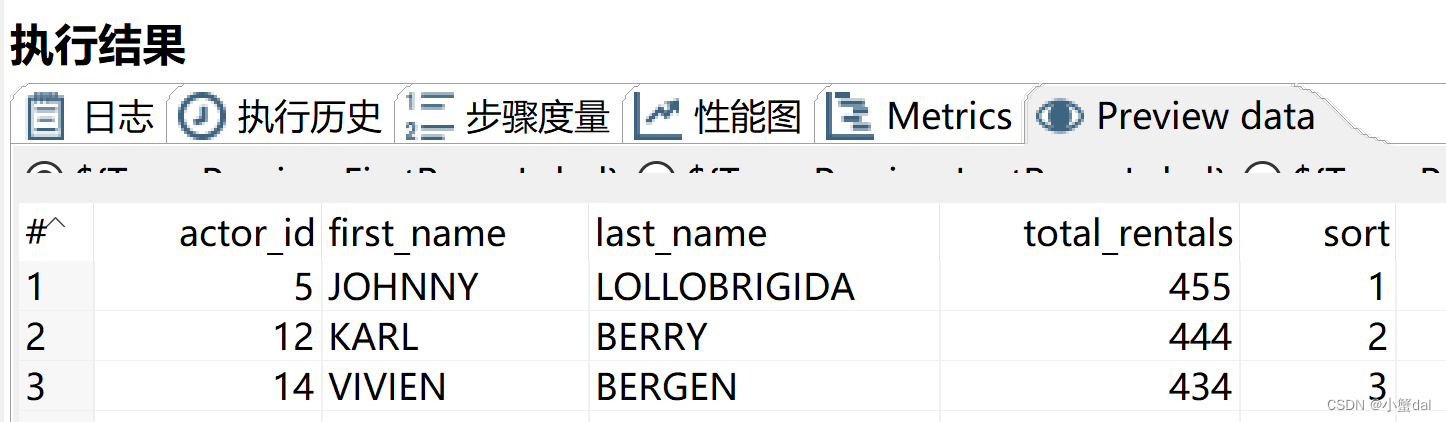
从结果看,actor_id为5,姓为JOHNNY,名为LOLLOBRIGIDA的演员的销售量最高,由此可见他是最受欢迎的电影明星。
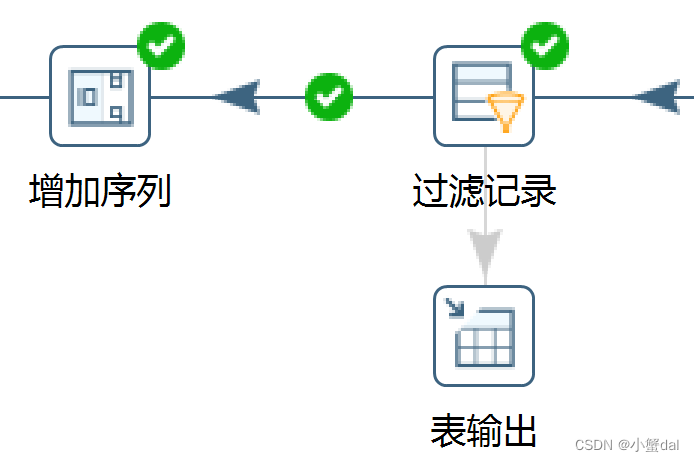
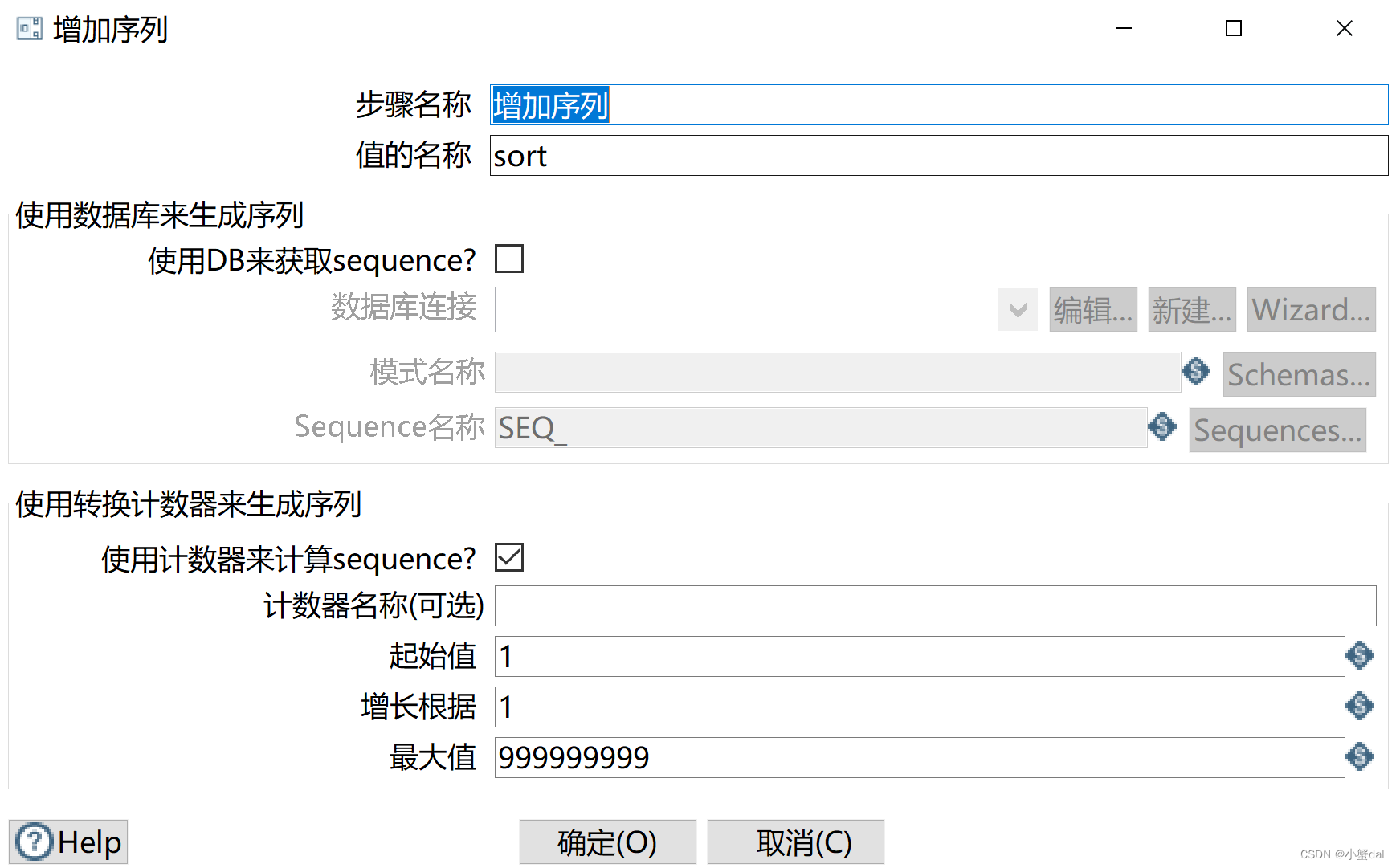
(12)建立【增加序列】组件
先点击过滤记录到表输出之间的跳,即连线,让其输出流不再输出到数据库中,再建立【增加序列】组件,为了方便后续过滤出最受欢迎的几位明星。
配置:
(13)建立【过滤记录】组件,把最受欢迎的前三名电影明星过滤出来
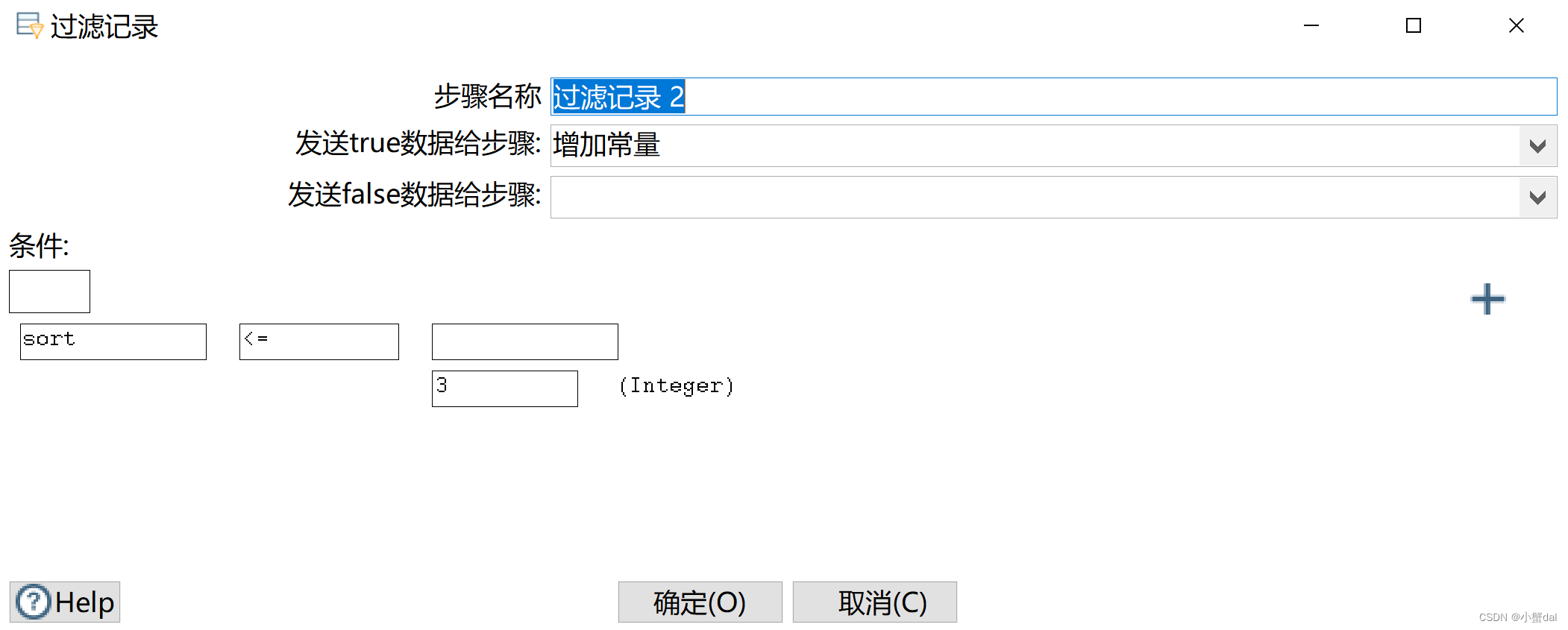
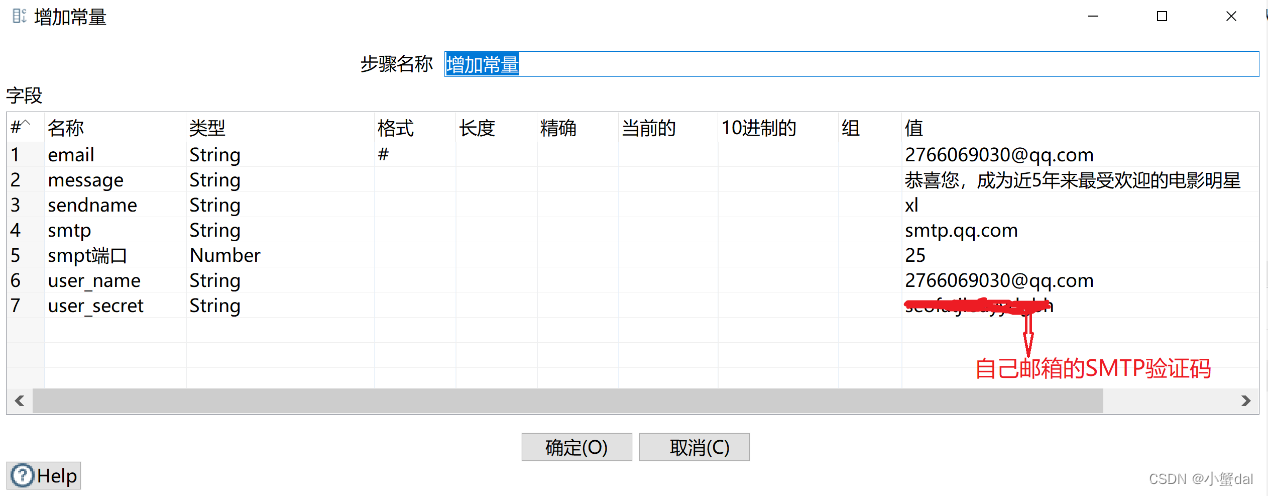
(14)建立【增加常量】组件
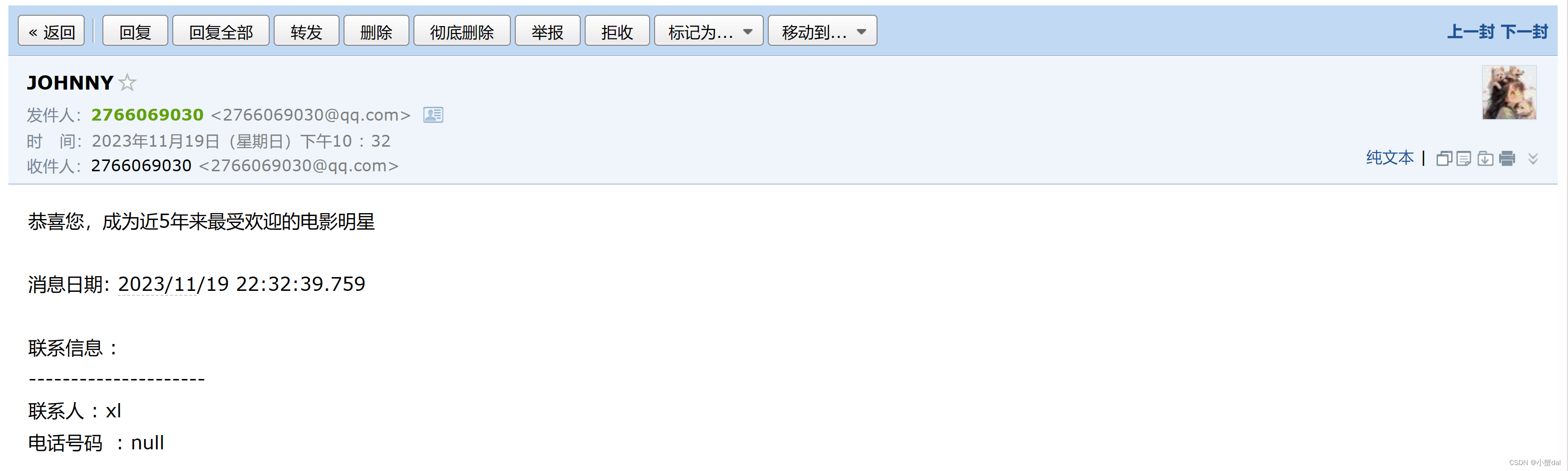
由于整个数据库中是没有明星的邮箱地址,所以这里我统一设置为我自己的邮箱地址
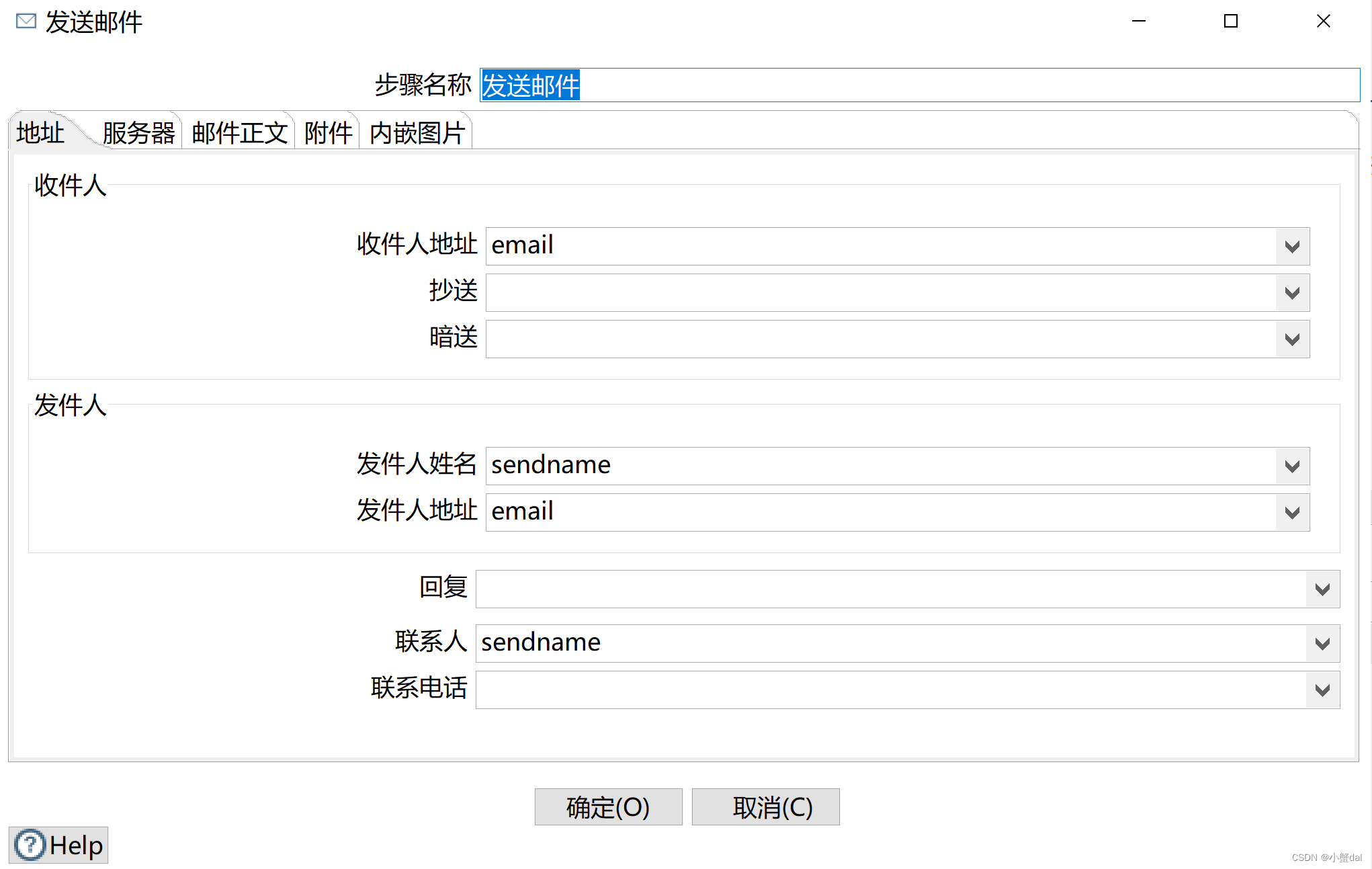
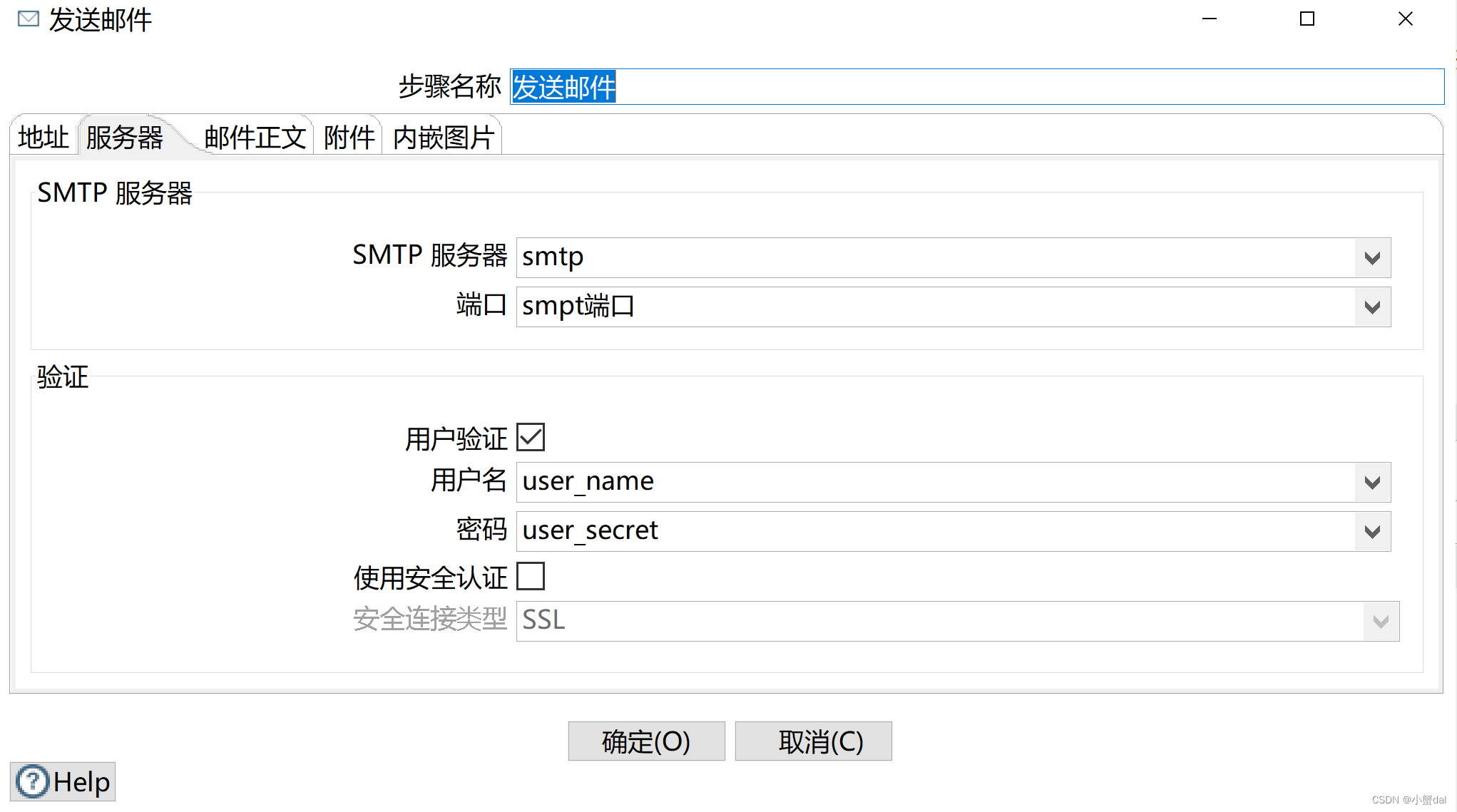
(15)建立【发送邮件】组件
从输入流中得到数据,逐条发送邮件
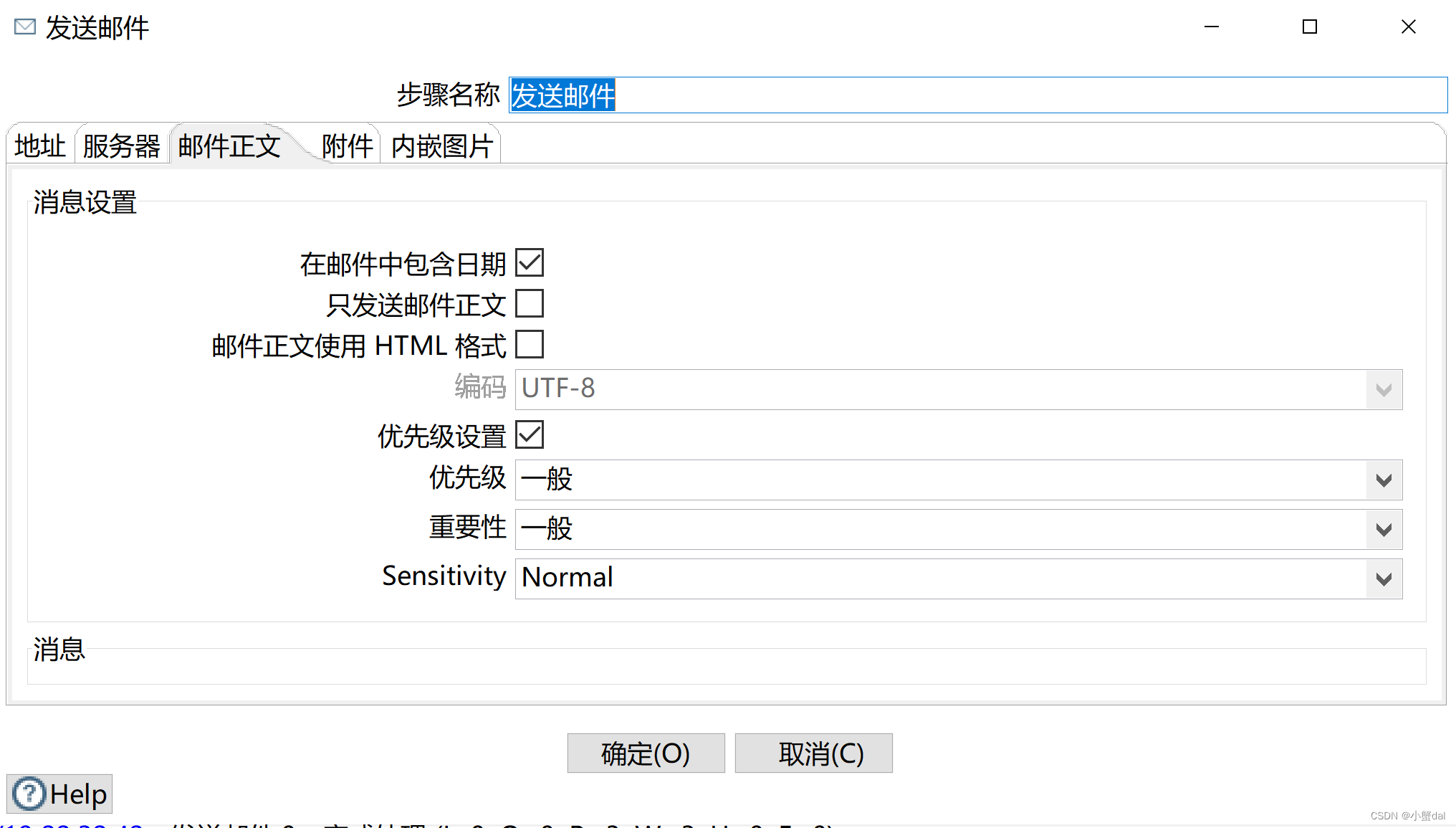
(16)运行转换,并查看邮箱
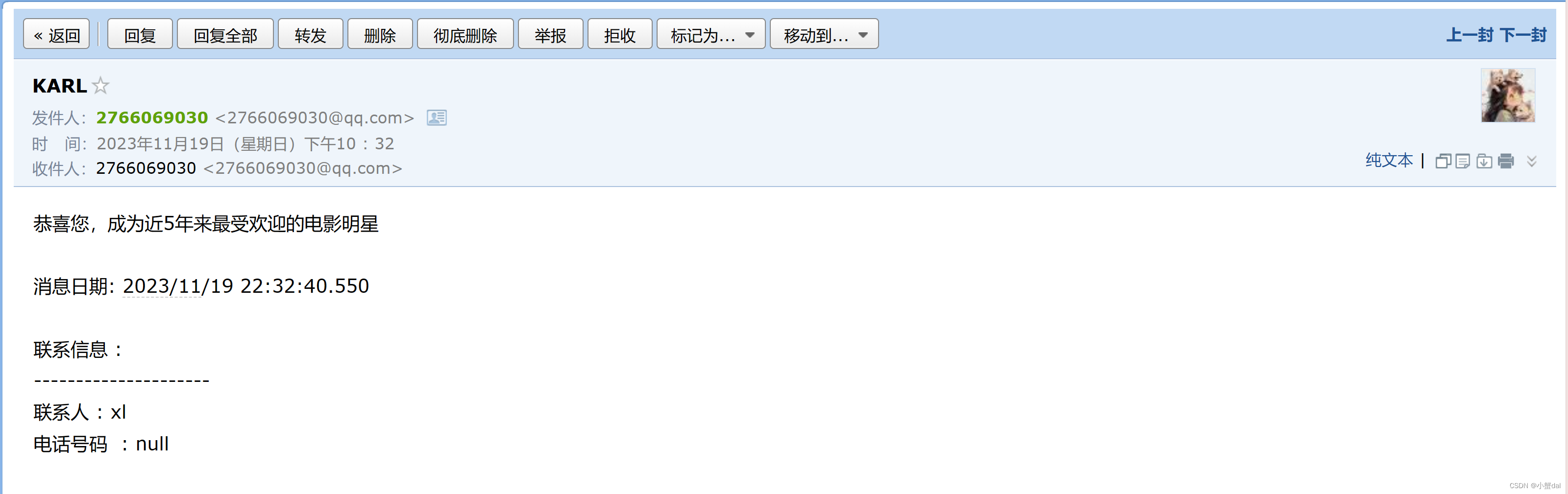
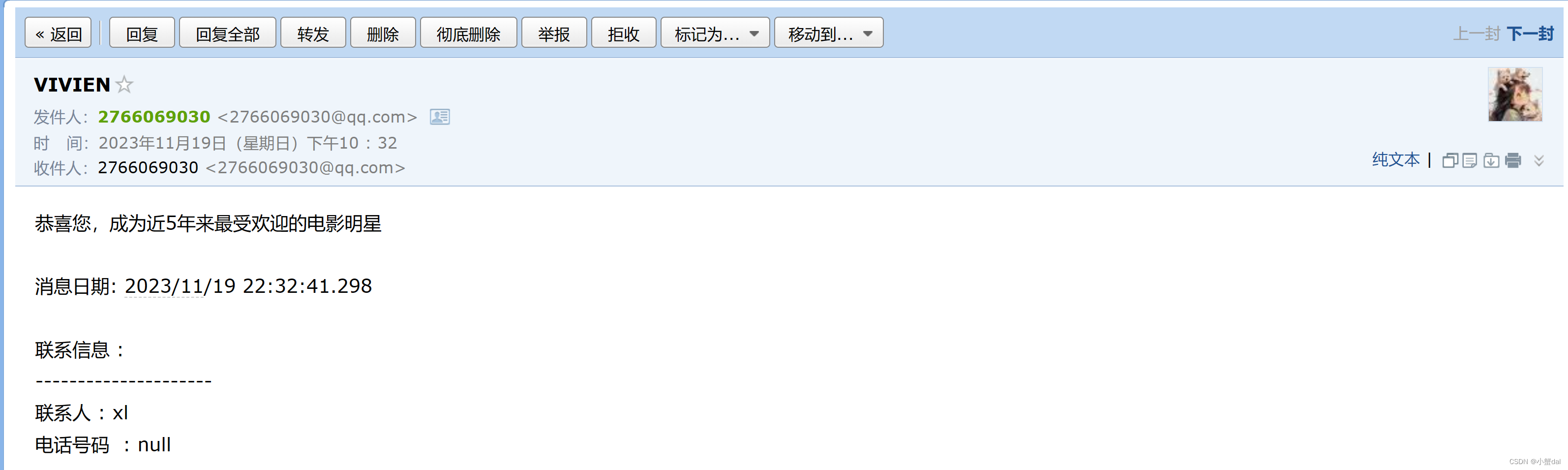
可以得到近5年,最受欢迎的前三名电影明星如下:
并给他们依次发送邮件如下

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)