基于强化学习的连贯长文本(写作)生成语言模型:LongWriter-Zero-32B
**摘要:**LongWriter-Zero是基于Qwen2.5-32B模型构建的强化学习文本生成系统,专攻超长连贯文本生成(10k+令牌)。通过300亿令牌的持续预训练和复合奖励函数(长度/写作/格式)优化,模型在WritingBench(8.69分)和Arena-Write(1447 Elo)基准测试中表现优异,超越多数开放模型。该研究为长文本生成中的连贯性控制提供了创新解决方案,适用于写作辅
LongWriter-Zero ✍️ — Mastering Ultra - Long Text Generation via Reinforcement Learning
一、研究背景与目标
随着人工智能技术的发展,大型语言模型在文本生成领域取得了显著成果。然而,生成超长连贯文本仍然是一个具有挑战性的任务。论文介绍了 LongWriter-Zero,这是一个完全基于强化学习(RL)的大型语言模型,能够生成超过 10000 令牌的连贯段落。其主要目标是通过强化学习方法,提升模型在超长文本生成任务中的表现,解决传统模型在生成长文本时可能出现的连贯性不足、重复等问题。
二、模型架构与训练方法
-
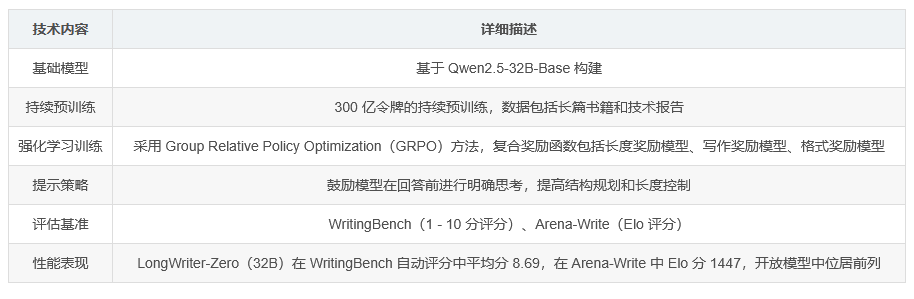
基础模型 :LongWriter-Zero 基于 Qwen2.5-32B-Base 模型构建。
-
持续预训练 :进行了 300 亿令牌的持续预训练,训练数据包括长篇书籍和技术报告,以增强模型的基本写作能力。
-
强化学习训练 :采用 Group Relative Policy Optimization(GRPO)方法,并使用复合奖励函数,包括长度奖励模型(Length Reward Model)确保输出长度符合要求;写作奖励模型(Writing RM)评估文本的流畅性、连贯性和帮助性;格式奖励模型(Format RM)保证严格遵循特定结构并检测重复内容,避免冗余。
-
提示策略 :采用专门的提示策略,鼓励模型在回答前进行明确的思考,从而提高结构规划和精细的长度控制。
三、评估与结果
-
评估基准 :主要在 WritingBench 和 Arena-Write 两个基准测试上展示 LongWriter-Zero 的有效性。WritingBench 采用 1 - 10 分的评分标准,Arena-Write 使用 Elo 评分系统。
-
性能对比 :LongWriter-Zero(32B)在 WritingBench 的自动评分中获得 8.69 的平均分,在 Arena-Write 中获得 1447 的 Elo 分,在开放模型中位居前列。在与 GPT - 4.1 等其他模型的对比评估中,也取得了较高的胜率,表明其在超长文本生成方面具有卓越的性能。
四、应用场景与代码示例
-
应用场景 :LongWriter-Zero 可广泛应用于需要生成长篇连贯文本的领域,如写作辅助、内容创作、文档生成等。
-
代码示例 :提供了使用 Hugging Face 和 SGlang 进行模型调用的代码示例,展示了如何格式化提示并通过模型生成文本。
五、总结
论文提出的 LongWriter-Zero 模型通过强化学习方法,在超长文本生成任务中取得了显著成果,为解决长文本生成中的连贯性和质量控制等问题提供了新的思路和方法,具有重要的研究价值和应用潜力。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)