NVIDIA Research新研究成果VILA2:视觉语言模型能力的自我提升
关注公众号:青稞AI,学习最新AI技术
关注公众号:青稞AI,学习最新AI技术
🔥青稞Talk主页:qingkelab.github.io/talks
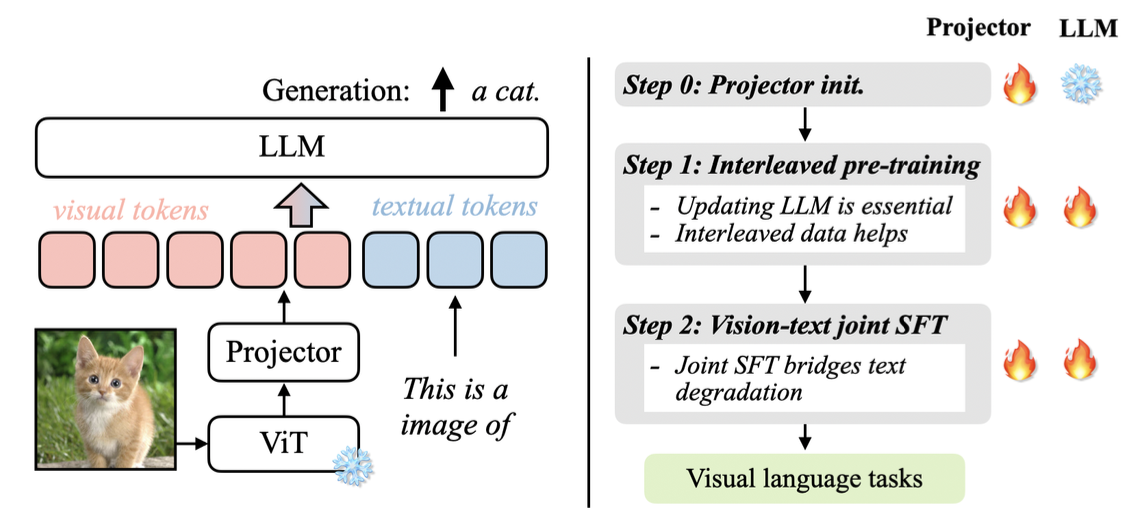
VILA 是一种视觉语言基础模型,它通过在预训练阶段对大型语言模型(LLM)进行增强,使其能够处理和理解视觉信息。其核心思路是将图像和文本数据进行联合建模,通过控制比较和数据增强,提升模型在视觉语言任务上的性能。
在 VILA 的基础上,还延伸出了集成视频、图像、语言理解和生成的基础模型VILA-U、支持 1024 帧长视频训练和推理的 LongVILA,以及 World Model Benchmark 等工作。
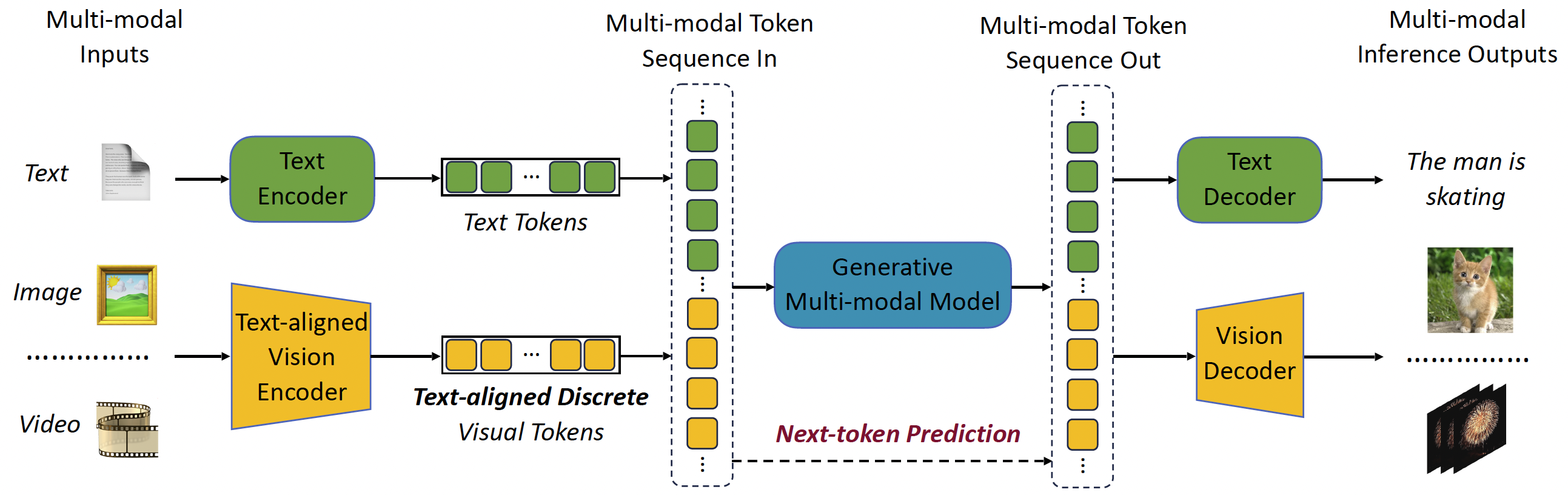
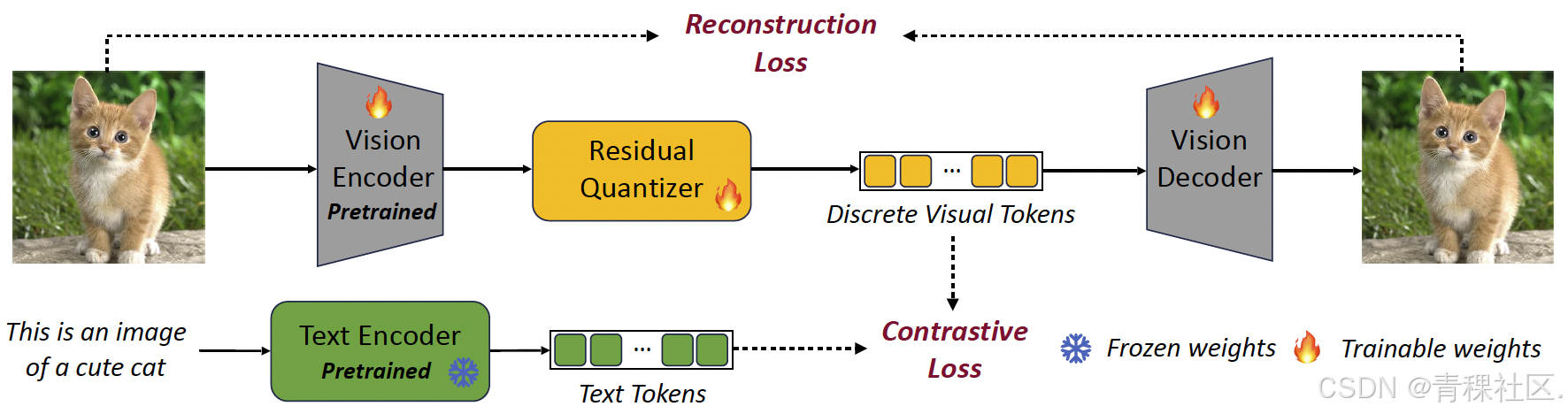

同时,在最新推出的 VILA2VILA^2VILA2 中,采用三阶段训练范式:align-pretrain-SFT。该方法引入了一种新颖的增强训练方案,首先在自举循环中进行自我增强 VLM 训练,然后进行专家增强,以利用 SFT 期间获得的技能。这种方法通过改进视觉语义和减少幻觉,直接提高了 VLM 性能,从而提高数据质量,并在 MMMU 排行榜上取得了开源模型中的最佳成绩。
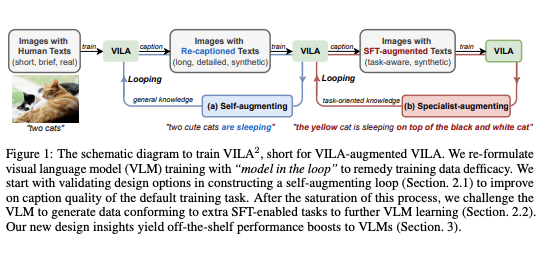
11月23日(本周六)上午11点,青稞Talk 第29期,VILA2VILA^2VILA2 第一作者方云浩,将直播分享《VILA 2: 视觉语言模型能力的自我提升》。
本次 Talk 将会以 VILA (Nvidia’s fully open-sourced visual language model)为基础模型,首先向大家简单介绍视觉语言模型的背景,和 VILA 团队做 VILA 的初衷。然后会以如何提升一个视觉语言模型为引,展开分享“视觉语言模型的自我提升”。最后,也会探讨 VILA-verse 的一系列工作,比如VILA-U(理解生成统一)、LongVILA(支持视觉长序列训练和推理)、World Model Benchmark 等。
主题提纲
VILA2VILA^2VILA2: 视觉语言模型能力的自我提升
1、视觉语言模型研究概述
2、基础模型 VILA 的初衷及架构解析
3、基于自增强与专家增强的 VILA2VILA^2VILA2
4、探讨VILA-U、LongVILA 以及 World Model Benchmark

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)