yolov8训练自己的数据集
YOLOv8作为最新的目标检测模型,以其高效和准确而受到广泛关注。在本文中,我们将详细介绍如何使用YOLOv8来训练自己的数据集,包括数据准备、数据集格式转换、配置文件编写以及训练过程。
·
yolov8训练直接的数据集
YOLOv8作为最新的目标检测模型,以其高效和准确而受到广泛关注。在本文中,我们将详细介绍如何使用YOLOv8来训练自己的数据集,包括数据准备、数据集格式转换、配置文件编写以及训练过程。
一 环境准备
-
安装Python环境,建议使用3.10以上版本。
-
安装Ultralytics YOLOv8库以及wandb进行监控训练过程。可以通过以下命令安装:
pip install ultralytics wandb -
如果需要使用GPU加速,确保安装了NVIDIA驱动和CUDA Toolkit。
二 准备数据集
-
收集并准备你的数据集,包括图像和对应的标注文件。
-
这里我使用X-AnyLabeling标注工具进行打yolov8标签。
-
将数据集分为训练集、验证集,其目录格式如下。

train训练集格式如下,其中images存放训练集图片,labels目录存放打好的yolov8标签。

验证集相同
三 配置数据集
-
创建一个YAML配置文件,指定数据集的路径、类别数量和类别名称,我里设置为data.yaml。例如:
# 根路径 path: ../datasets/MaskDataSet # 根路径下的训练集路径 train: ./train # 根路径下的验证集路径 val: ./val # 标签的列表数量 nc: 2 # 标签的类别 names: ['mask', 'no-mask']
四 训练模型
- 模型训练,在模型训练的开始会登有wandb的网址,进行登录认证以后,进行开发模型的训练。
from ultralytics import YOLO
# 加载预训练模型
# 你可以选择不同的预训练权重,如 'yolov8n.pt', 'yolov8s.pt', 'yolov8m.pt', 'yolov8l.pt', 'yolov8x.pt'
model = YOLO('yolov8n.pt') # 使用YOLOv8 Nano版本作为基础
# 定义数据集配置文件路径
data_config = 'path/to/your/data.yaml' # 替换为你的data.yaml文件的实际路径
# 设置训练参数
epochs = 100 # 训练轮数
imgsz = 640 # 输入图像大小
batch_size = 16 # 批处理大小
workers = 8 # 数据加载器的工作线程数量
device = 0 # 使用GPU编号,如果使用CPU则设为None或'cpu'
# 开始训练
results = model.train(
data=data_config,
epochs=epochs,
imgsz=imgsz,
batch=batch_size,
workers=workers,
device=device,
name='yolov8_custom_train', # 模型保存名称
save=True, # 是否保存模型
exist_ok=True, # 如果存在相同命名的训练结果是否覆盖
cache=False, # 是否缓存数据以加速训练
)
print("训练完成:", results.save_dir)
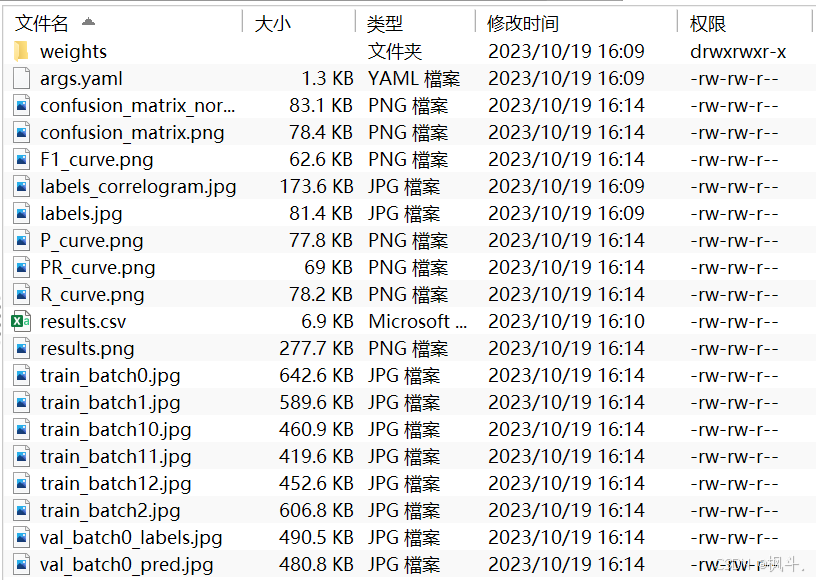
六 训练完成
在模型进行训练完成以后,模型会保存在runs目录的weights中,其中,best保存的训练的验证效果最好的模型。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)