Pandas数据处理—清理、转换、合并、重塑
Pandas数据处理pandas对象中的数据可以通过一些内置的方式进行合并:pandas.merge可根据一个或多个键将不同DataFrame中的行连接起来。pandas.concat可以沿着一条轴将多个对象堆叠到一起。默认情况下merge做的是’inner’连接,其他方式还有’left’、‘right’、‘outer’df1=pd.DataFrame({'key':['b','b','...
Pandas数据处理
pandas对象中的数据可以通过一些内置的方式进行合并:
pandas.merge可根据一个或多个键将不同DataFrame中的行连接起来。
pandas.concat可以沿着一条轴将多个对象堆叠到一起。
默认情况下merge做的是’inner’连接,其他方式还有’left’、‘right’、‘outer’
df1=pd.DataFrame({'key':['b','b','a','c','a','b'],'data1':range(6)})
df2=pd.DataFrame({'key':['a','b','a','b','d'],'data2':range(5)})
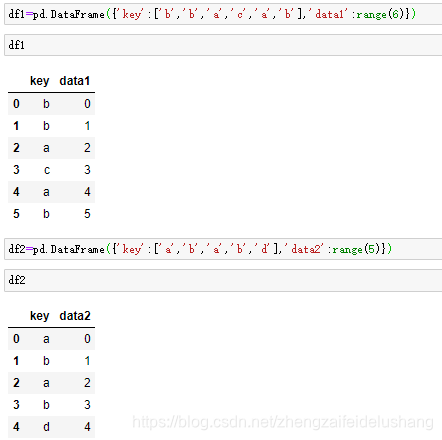
多对多连接产生的是行的笛卡儿积,左边DataFrame有3个’b’行,右边有2个,最终结果中就有6个’b’行
pd.merge(df1,df2,on='key',how='left')
要根据多个键进行合并,传入一个由列名组成的列表即可
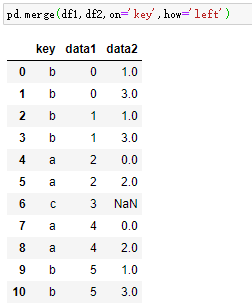
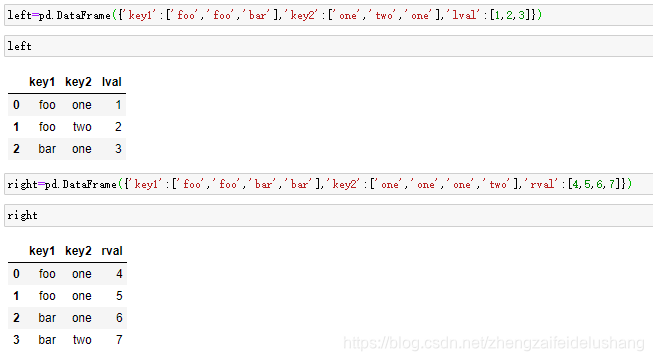
left=pd.DataFrame({'key1':['foo','foo','bar'],'key2':['one','two','one'],'lval':[1,2,3]})
right=pd.DataFrame({'key1':['foo','foo','bar','bar'],'key2':['one','one','one','two'],'rval':[4,5,6,7]})
可以理解为多个键形成一系列元组,并将其当作单个连接键
pd.merge(left,right,on=['key1','key2'],how='outer')

merge的suffixes选项用于指定附加到左右两个DataFrame对象的重叠列名上的字符串
pd.merge(left,right,on='key1',suffixes=('_left','_right'))

merge函数的参数
| 参数 | 说明 |
|---|---|
| how | ‘inner’、’outer’、‘left’、’right‘,默认为’inner’ |
| left_on | 左侧DataFrame中用作连接键的列 |
| right_on | 右侧DataFrame中用作连接键的列 |
| left_index | 将左侧的行索引用作其连接键 |
| right_index | 类似于left_index |
| sort | 根据连接键对合并后的数据进行排序,默认为True |
| suffixes | 字符串值元组,用于追加到重叠列名的末尾,默认为(’_x’,’_y’ |
| copy | 设置为False,可以在某些特殊情况下避免将数据复制到结果数据结构中。默认总是复制 |
索引上的合并
DataFrame中的连接键位于其索引中,可以传入left_index=True或right_index=True以说明索引应该被用作连接键
left1=pd.DataFrame({'key':['a','b','a','a','b','c'],'value':range(6)})
right1=pd.DataFrame({'group_val':[3.5,7]},index=['a','b'])
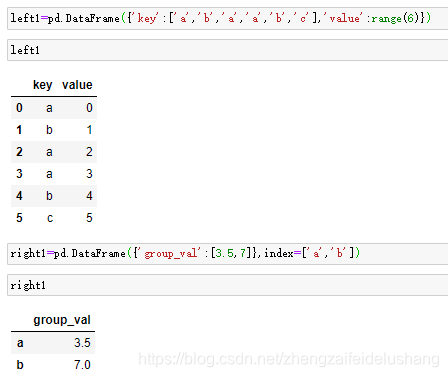
pd.merge(left1,right1,left_on='key',right_index=True,how='inner')

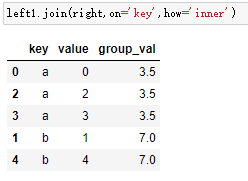
DataFrame还有一个join实例方法,
left1.join(right,on='key',how='inner')
轴向连接
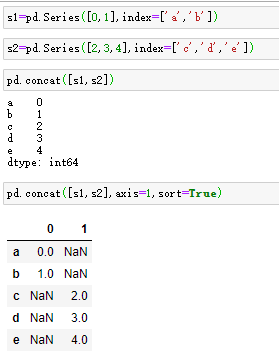
pandas的concat函数可以将值和索引粘合在一起,默认情况下,concat是在axis=0上工作的,最终产生一个新的Series。传入axis=1,则结果就会变成一个DataFrame(axis=1是列)
s1=pd.Series([0,1],index=['a','b'])
s2=pd.Series([2,3,4],index=['c','d','e'])
pd.concat([s1,s2])
pd.concat([s1,s2],axis=1,sort=True)
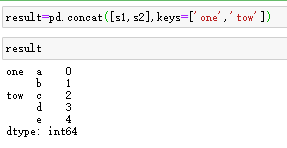
想要在连接轴上创建一个层次化索引,使用keys参数可以达到这个目的
result=pd.concat([s1,s2],keys=['one','tow'])
如果沿着axis=1对Series进行合并,则keys就会成为DataFrame的列头
pd.concat([s1,s2],axis=1,keys=['one','two'],sort=True)

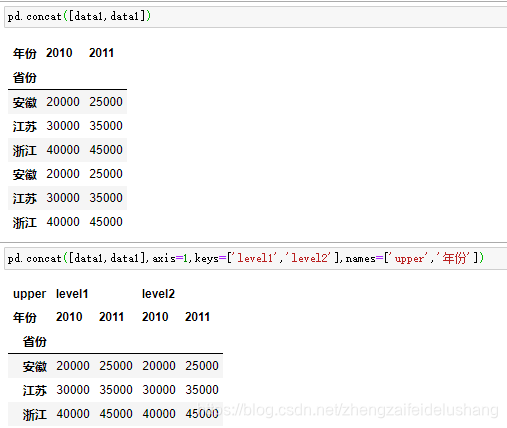
同样的逻辑对DataFrame对象一样
pd.concat([data1,data1])
pd.concat([data1,data1],axis=1,keys=['level1','level2'],names=['upper','年份'])
concat函数的参数
| 参数 | 说明 |
|---|---|
| axis | 指明连接的方向 |
| join | inner、outer,默认outer,指明其他轴向上的索引是按交集还是并集进行合并 |
| keys | 用于形成连接轴上的层次化索引,可以是任意值的列表或数组、元组数组、数组列表 |
| levels | 指定用作层次化索引各级别上的索引,如果设置了keys的话 |
| names | 用于创建分层级别的名称,如果设置了keys和levels的话 |
| verify_integrity | 检查结果对象新轴上的重复情况,如果发现则引发异常,默认False允许重复 |
| ignore_index | 不保留连接轴上的索引,产生一组新索引 |
合并重叠数据
combine_first用参数对象中的数据为调用者对象的缺失数据打补丁
df1 = pd.DataFrame({'a':[1,np.nan,5,np.nan],'b':[np.nan,2,np.nan,6],'c':range(2,18,4)})
df2 = pd.DataFrame({'a':[5,4,np.nan,3,7],'b':[np.nan,3,4,6,8]})
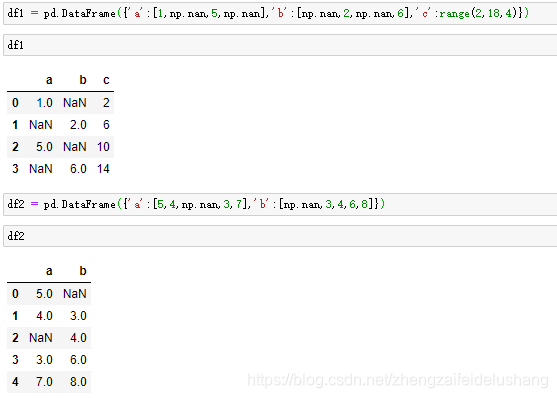
df1.combine_first(df2)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)