Python 数据挖掘(四) pandas模块 简单使用
1.pandas模块pandas是基于numpy模块构建的。pandas的主要功能:具备对其功能的数据结构DataFrame、Series集成时间序列功能提供丰富的数学运算和操作灵活处理缺失数据2.pandas数据结构Series是一种类似于以为NumPy数组的对象,它由一组数据(各种NumPy数据类型)和与之相关的一组数据标签(即索引)组成的。可以用index和values分别规定索引和值。如果
·
1.pandas模块
pandas是基于numpy模块构建的。
pandas的主要功能:
- 具备对其功能的数据结构DataFrame、Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
2.pandas数据结构
Series是一种类似于以为NumPy数组的对象,它由一组数据(各种NumPy数据类型)和与之相关的一组数据标签(即索引)组成的。可以用index和values分别规定索引和值。如果不规定索引,会自动创建 0 到 N-1 索引。
DataFrame是一种表格型结构,含有一组有序的列,每一列可以是不同的数据类型。既有行索引,又有列索引,可以被看做由Series组成的字典(使用共同的索引)。跟其他类似的数据结构(比如R中的data.frame),DataFrame面向行和列的操作基本是平衡的。其实,DataFrame中的数据是以一个或者多个二维块存放的(不是列表、字典或者其他)。
DataFrame是一种表格型结构,含有一组有序的列,每一列可以是不同的数据类型。既有行索引,又有列索引,可以被看做由Series组成的字典(使用共同的索引)。跟其他类似的数据结构(比如R中的data.frame),DataFrame面向行和列的操作基本是平衡的。其实,DataFrame中的数据是以一个或者多个二维块存放的(不是列表、字典或者其他)。
3.pandas简单使用
3.1 Series
import pandas as pda
# Series方法以及index索引
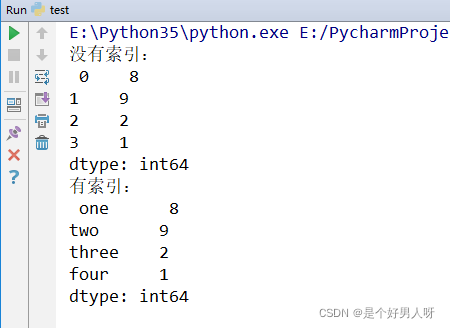
a = pda.Series([8, 9, 2, 1]) # 默认的索引是0 1 2 3
b = pda.Series([8, 9, 2, 1], index=["one", "two", "three", "four"])
print("没有索引:\n", a)
print("有索引:\n", b)输出结果:
3.2 DataFrame
# DataFrame方法 含义是数据框,就是一个表格,拥有行和列,也相当于一个二维数组,通过数组的形式创建
# 0 1 2 3 是默认的列名
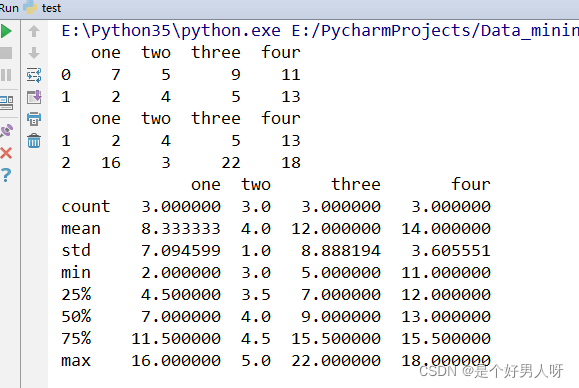
c = pda.DataFrame([[7,5,9,11],[2,4,5,13],[16,3,22,18]])
# columns是列名
d = pda.DataFrame([[7,5,9,11],[2,4,5,13],[16,3,22,18]],columns=["one","two","three","four"])
print(c)
print(d)输出结果:

3.3 head 和 tail
# 2代表取前2行,如果不填数字,默认是取前5行
print(d.head(2))
# 2代表取后2行,如果不填数字,默认是取后5行
print(d.tail(2))
# describe方法,展示表的列个数、平均数、标准差、最小值、每一列的四分位数(25%)、每一列的四分位数(50%)、每一列的四分位数(75%)和最大数
print(d.describe())输出结果:
3.4 转置
print(d.T)
3.5 通过字典创建
# 通过字典的形式创建,字典{}key:value的形式,数据会自动填充,是数据本身
# one,two这些代表的是列名
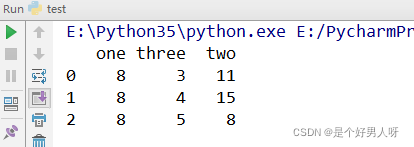
e = pda.DataFrame({
"one": 8,
"two": [11, 15, 8],
"three": list(str(345))
})
print(e)输出结果:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)