一步一步构建基于知识图谱的RAG应用指南
知识图谱已成为管理与分析复杂数据关系的强大工具。与传统的关系型数据库通过行和列在表格中存储数据不同,图数据库使用节点、边和属性来表示和存储数据,提供了一种更直观和高效的方式来构建、查看和查询复杂系统。本文将指导你了解、实现和利用知识图谱数据库。理解知识图谱(关键概念)节点:这些代表单个数据实体,如人、地点或物体。每个节点具有标识符、标签和若干属性。边:这些代表节点之间的连接,显示它们之间的关系。每
知识图谱已成为管理与分析复杂数据关系的强大工具。与传统的关系型数据库通过行和列在表格中存储数据不同,图数据库使用节点、边和属性来表示和存储数据,提供了一种更直观和高效的方式来构建、查看和查询复杂系统。本文将指导你了解、实现和利用知识图谱数据库。
理解知识图谱(关键概念)
节点:这些代表单个数据实体,如人、地点或物体。每个节点具有标识符、标签和若干属性。
边:这些代表节点之间的连接,显示它们之间的关系。每条边有一个起始节点、一个结束节点、一个类型和一些属性。
属性:与节点和边关联的属性或数据值。
为什么选择知识图谱数据库?
解决朴素RAG的问题 -> RAG(检索增强生成)是一种技术,它为大语言模型提供了外部知识或数据,这些数据是语言模型未曾训练过的。依赖于基于向量的检索的朴素RAG方法面临诸如缺乏深层次上下文理解和复杂推理能力等若干限制。为了解决这些问题,将知识图谱集成到RAG系统中。
传统的数据库,如关系数据库,将数据存储在结构化的表格中。尽管这种方法适用于许多应用程序,但在处理复杂关系时却显得不足。关系数据库需要复杂的连接和查询来导航关系,这使得它们效率较低且难以管理。
相比之下,知识图谱设计用于轻松处理复杂关系。它们能够实现:
简化数据建模:实体及其关系的自然表示。
高效的查询性能:更快地检索关联数据。
灵活性:轻松适应不断变化的数据结构。
使用知识图谱的场景
图数据库在数据点之间关系至关重要的场景中表现卓越。以下是一些常见的应用场景:
客户分析:通过映射交互和关系来理解客户行为。
推荐系统:通过分析用户和产品之间的连接提供个性化推荐。
分析复杂关系:探索数据中的复杂连接,如社交网络或组织结构。
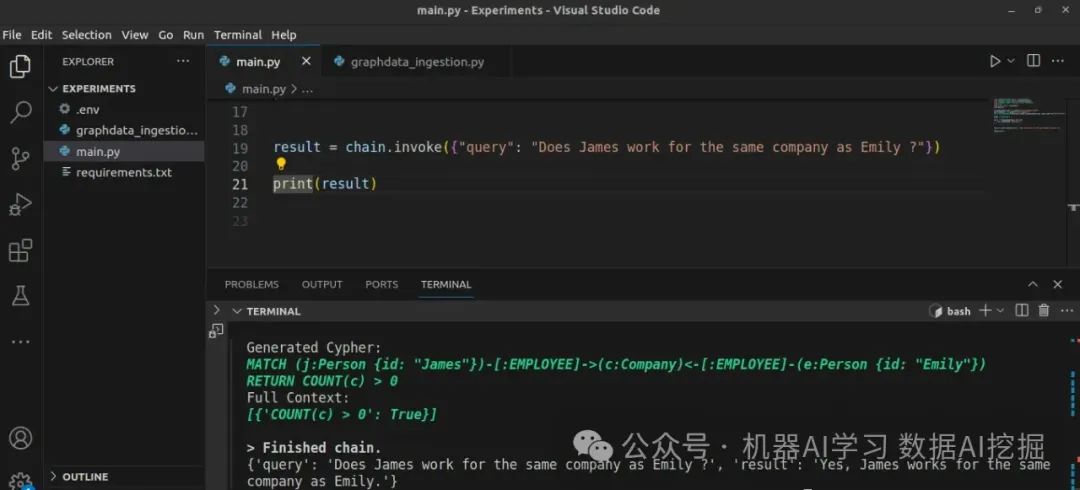
构建知识图谱:逐步指南
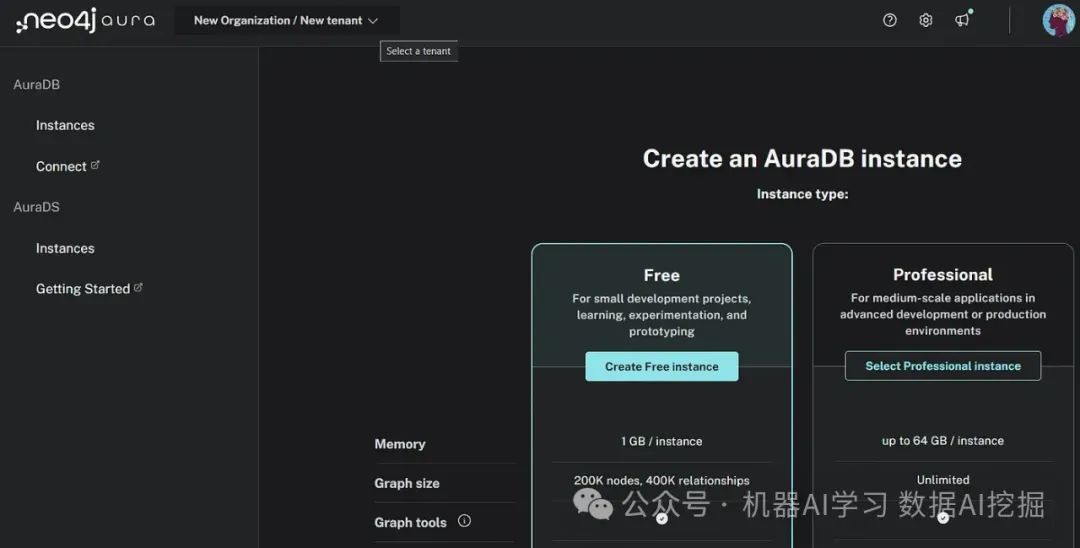
在这个项目中,我使用了Neo4j图数据库、Langchain框架和AzureChat OpenAI模型(GPT 3.5 turbo)。在跳转到代码之前,我们首先在Neo4j上创建图数据库实例。
点击此链接并使用Google账户登录。登录后,点击创建免费实例,如下面的图片所示。然后,您将获得下载和继续按钮以获取Instance01的凭据。您可以将该凭据复制并粘贴到.env文件中。
步骤1:导入必要的包和凭证。
我将详细介绍每个包。
from langchain_openai` `import AzureChatOpenAI``from langchain_experimental.graph_transformers` `import LLMGraphTransformer``from langchain_core.documents` `import Documentfrom langchain.text_splitter` `import CharacterTextSplitter``from langchain_community.graphs` `import Neo4jGraphimport osfrom dotenv` `import load_dotenvllm_deployement_name = os.getenv("llm_deployement_name")``azure_endpoint = os.getenv("azure_endpoint")
第2步:初始化AzureChatOpenAI及Neo4jGraph
来自LangChain的AzureChatOpenAI类允许我们与部署在Azure上的OpenAI GPT模型进行交互。接下来,我们使用LangChain社区图模块中的Neo4jGraph类设置Neo4j图数据库,以存储和检索数据。Neo4j提供了Cypher查询语言,使得与图数据的交互和查询变得简单易行。
Cypher查询语言(Cypher)是一种专门用于查询和操作如Neo4j这样的图数据库的强大而表达力的语言。它允许用户以直观且高效的方式描述图中的模式。例如,一个简单的Cypher查询,用于查找名为Alice的所有朋友:
MATCH (alice:Person {name: ‘Alice’})-[:FRIEND]->(friend)
RETURN friend
此查询匹配名为“Alice”的人员节点,并查找与Alice通过“FRIEND”关系连接的所有节点,将这些节点作为朋友返回。
llm = AzureChatOpenAI(deployment_name=llm_deployement_name, model_name="gpt-35-turbo-16k", azure_endpoint=azure_endpoint)``graph = Neo4jGraph()
步骤3:数据摄取与预处理
我们从包含某科技公司员工信息的样本文本开始。将使用CharacterTextSplitter将该文本分割成可管理的块。
text = """Emily is an employee at TechNova, a leading technology company based in Silicon Heights.` `She has been working there for the past four years as a software developer. James is also an employee` `at TechNova, where he works as a data analyst. He joined the company three years ago after completing his` `undergraduate studies. TechNova is a renowned technology company that specializes in developing innovative` `software solutions and advanced artificial intelligence systems. The company boasts a diverse team of talented` `professionals from various fields. Both Emily and James are highly skilled experts who contribute significantly to``TechNova's achievements. They collaborate closely with their respective teams to create cutting-edge products and services``that cater to the dynamic needs of the company's clients."""`` ``documents = [Document(page_content=text)]``text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20)``texts = text_splitter.split_documents(documents)
步骤4:将文本转换为图
LLMGraphTransformer类利用语言模型将文本转换为图文档,在语言模型的帮助下识别节点和关系。一旦我们有了图文档,就可以将其添加到Neo4j数据库中。
llm_transformer = LLMGraphTransformer(llm=llm)``graph_documents = llm_transformer.convert_to_graph_documents(texts)`` ``print(f"Nodes:{graph_documents[0].nodes}") # this is to see Nodes of generate graph``print("-----------------------------------------------------------------")``print(f"Relationships:{graph_documents[0].relationships}")` ` ``graph.add_graph_documents(graph_documents)``print("Documents successfully added to Graph DataBase")
请注意,由于构建图时使用了大型语言模型(LLM),因此每次构建的结果可能不同。您也可以根据需要指定要提取的节点和关系的类型。这里是如何设置仅允许特定的节点和关系:
llm_transformer_filtered = LLMGraphTransformer(` `llm=llm,` `allowed_nodes=["Author", "Book", "Publisher"],` `allowed_relationships=["WRITTEN_BY", "PUBLISHED_BY"],``)``graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents(` `documents``)
步骤5:查询图数据库
要查询图数据库,我们使用来自LangChain的GraphCypherQAChain。这条链允许我们使用自然语言查询从图中提取信息。GraphCypherQAChain是一个工具,它可以根据用户的问题生成针对Neo4j图数据库的Cypher查询,从而轻松获取所需的信息。
chain = GraphCypherQAChain.from_llm(` `llm, graph=graph, verbose=True``)``result = chain.invoke({"query": "Where does James work?"})`` ``print(result)
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)