Python实现SSA智能麻雀搜索算法优化XGBoost-MLP分类模型项目实战
Python实现SSA智能麻雀搜索算法优化XGBoost-MLP分类模型项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后关注获取。
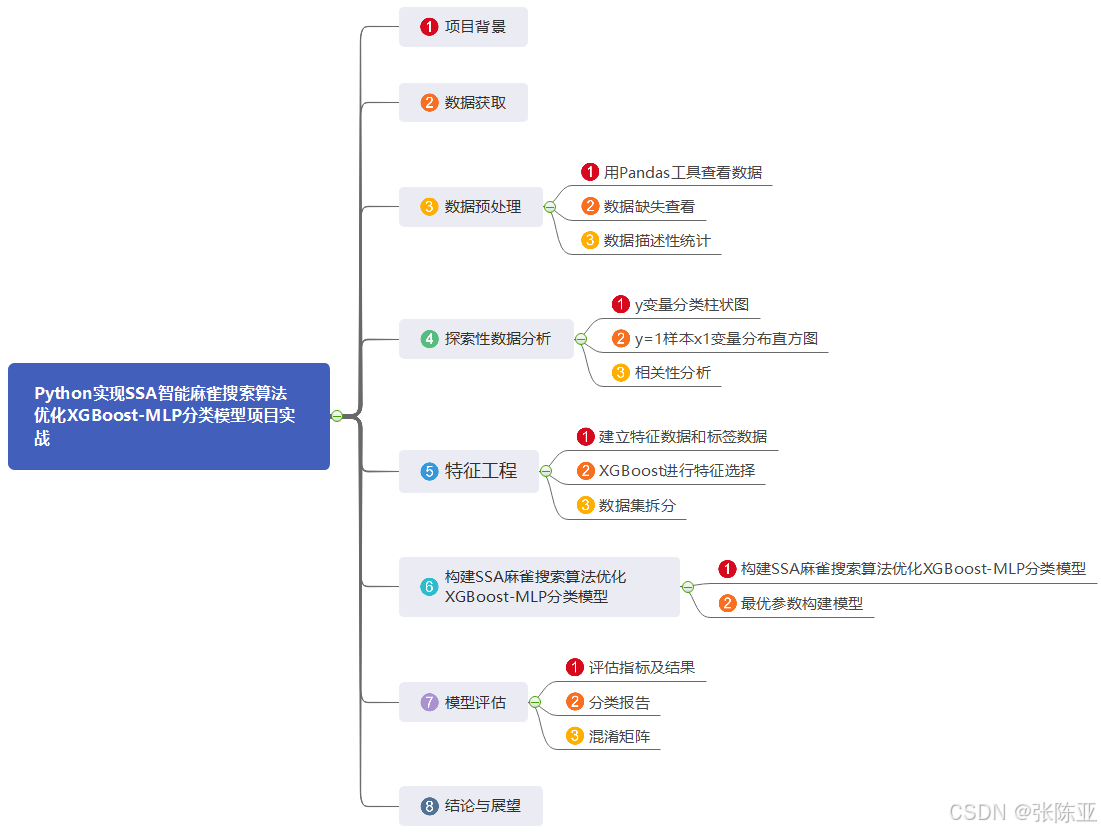
1.项目背景
随着人工智能技术的发展,特别是在大数据处理领域,机器学习模型已经成为了从复杂数据集中提取有价值信息的关键工具。其中,多层感知器(MLP)作为一类典型的深度学习模型,因其强大的非线性映射能力和适应性,在图像识别、语音处理、自然语言处理等领域展现出了卓越的表现。然而,MLP模型的训练过程涉及到大量的超参数选择,包括但不限于隐藏层数目、每层的神经元数量、激活函数类型等,这些选择直接决定了模型的性能和泛化能力。
另一方面,尽管XGBoost(eXtreme Gradient Boosting)作为集成学习中的佼佼者,以其高效的计算能力和出色的预测性能在多个领域获得了广泛的应用,但在实际应用中,面对高维数据集时,如何有效地进行特征选择以提高模型的稳定性和解释性,仍然是一个挑战。特征选择不仅能减少模型训练的时间成本,还能避免因冗余特征导致的过拟合问题。
为了解决上述问题,本项目引入了麻雀搜索算法(SSA, Sparrow Search Algorithm)这一先进的优化技术。SSA是一种模拟自然界中麻雀觅食行为的群智能算法,具有良好的全局搜索能力和快速收敛的特点。通过SSA对MLP的超参数进行优化,可以显著提升模型的学习效率和预测精度。
本项目的创新点在于将SSA算法应用于MLP模型的超参数优化过程中,通过智能搜索算法自动寻找到最优或近似最优的超参数配置。此外,考虑到特征选择的重要性,本项目还将探讨如何使用XGBoost进行特征重要性排序,并将这些信息整合进SSA优化过程中,以指导MLP模型的训练,从而进一步提高分类模型的整体性能。
本项目的目标是开发一套基于SSA优化的MLP模型训练框架,该框架能够自动完成特征选择和超参数优化,并通过实证研究验证其在不同类型数据集上的有效性。通过本项目的实施,期望能够为机器学习模型的自动化设计提供新的解决方案,并推动其在实际业务场景中的应用和发展。
本项目通过Python实现SSA智能麻雀搜索算法优化XGBoost-MLP分类模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|
编号 |
变量名称 |
描述 |
|
1 |
x1 |
|
|
2 |
x2 |
|
|
3 |
x3 |
|
|
4 |
x4 |
|
|
5 |
x5 |
|
|
6 |
x6 |
|
|
7 |
x7 |
|
|
8 |
x8 |
|
|
9 |
x9 |
|
|
10 |
x10 |
|
|
11 |
y |
因变量 |
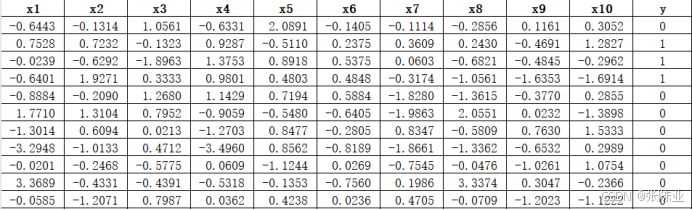
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
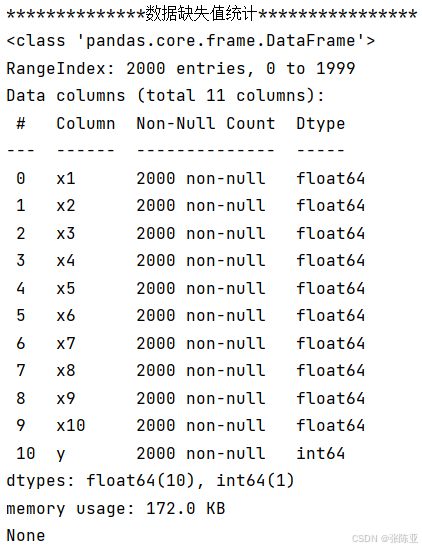
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
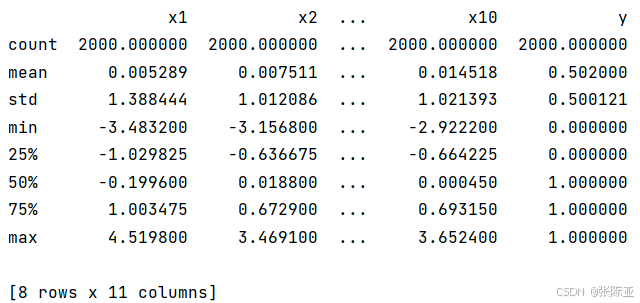
关键代码如下:

4.探索性数据分析
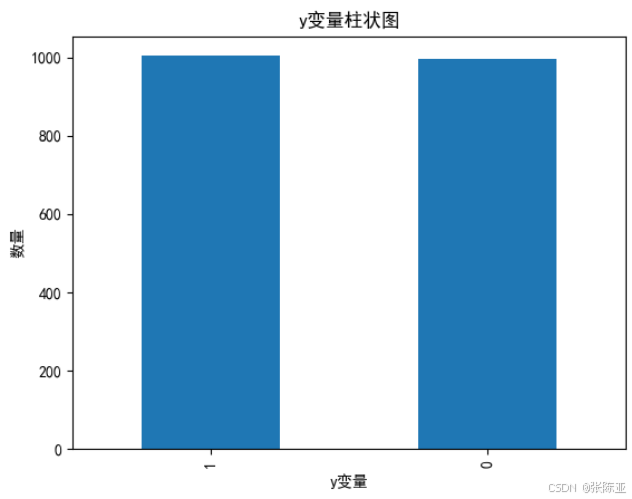
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
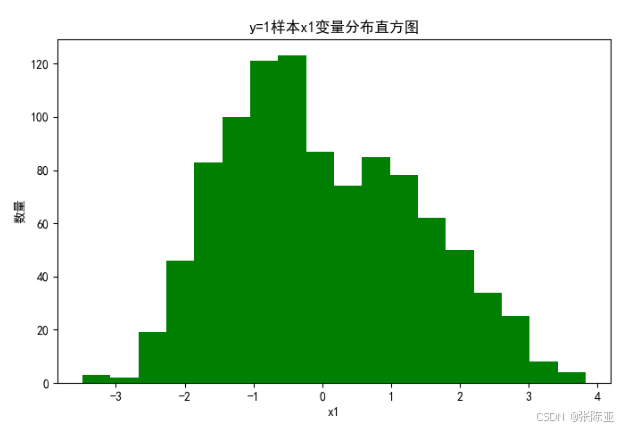
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
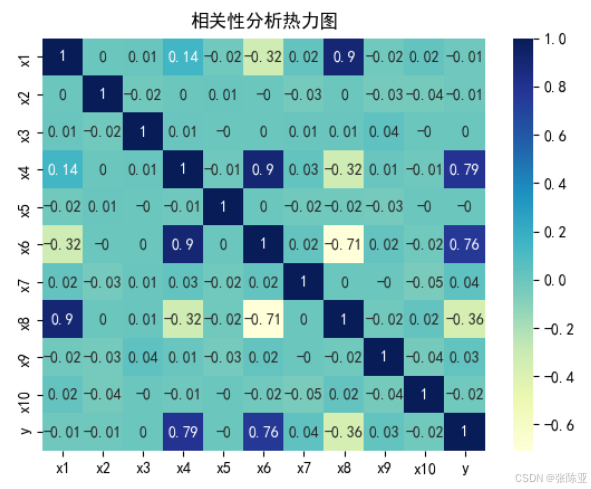
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 XGBoost进行特征选择

通过上图可以看到,x5、x9特征重要性几乎为0,所以可以考虑后续的建模中去掉这2个特征。如果换数据之后,需要根据具体的情况进行调整,可以去掉一些不重要的特征。
5.3 数据集拆分
通过train_test_split()方法按照80%训练集、20%验证集进行划分,关键代码如下:

6.构建SSA麻雀搜索算法优化XGBoost-MLP分类模型
主要通过XGBoost进行特征的选择,然后使用SSA麻雀搜索算法优化MLP算法,用于目标分类。
6.1 SSA麻雀搜索算法寻找最优参数值
最优参数值:

6.2 最优参数构建模型
这里通过最优参数构建分类模型。
|
模型名称 |
模型参数 |
|
XGBoost-MLP分类模型 |
max_iter=best_max_iter |
|
learning_rate_init=best_learning_rate_init |
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
|
模型名称 |
指标名称 |
指标值 |
|
测试集 |
||
|
XGBoost-MLP分类模型 |
准确率 |
0.9175 |
|
查准率 |
0.9005 |
|
|
查全率 |
0.933 |
|
|
F1分值 |
0.9165 |
|
从上表可以看出,F1分值为0.9165,说明麻雀搜索算法优化的的XGBoost-MLP模型效果较好。
关键代码如下:

7.2 分类报告
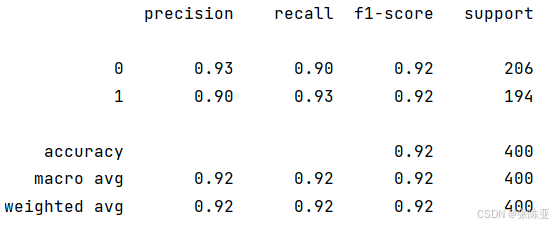
从上图可以看出,分类为0的F1分值为0.92;分类为1的F1分值为0.92。
7.3 混淆矩阵
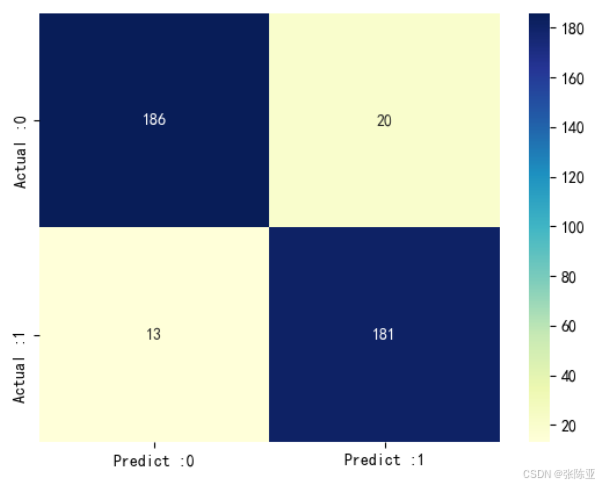
从上图可以看出,实际为0预测不为0的 有20个样本,实际为1预测不为1的 有13个样本,模型效果较好。
8.结论与展望
综上所述,本文采用了通过XGBoost进行特征选择,然后使用SSA麻雀搜索算法寻找MLP算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 40
40 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)