毕业设计:Vue3+FastApi+Python+Neo4j实现主题知识图谱网页应用——前后端:新闻热点
完整项目资源链接:https://download.csdn.net/download/m0_46573428/87796553项目详细信息请看:https://blog.csdn.net/m0_46573428/article/details/130071302进入新闻热点模块,后台自动爬取各大平台的新闻头条,并返回前端进行渲染。
简介
完整项目资源链接:https://download.csdn.net/download/m0_46573428/87796553
项目详细信息请看:https://blog.csdn.net/m0_46573428/article/details/130071302
项目中比较麻烦的一环是数据,尽管我找到的都是网上公开的数据和资料,但是相关的限制也挺多的。经过筛选,本项目的数据都是网上公开,可以爬虫,不受限制的内容。
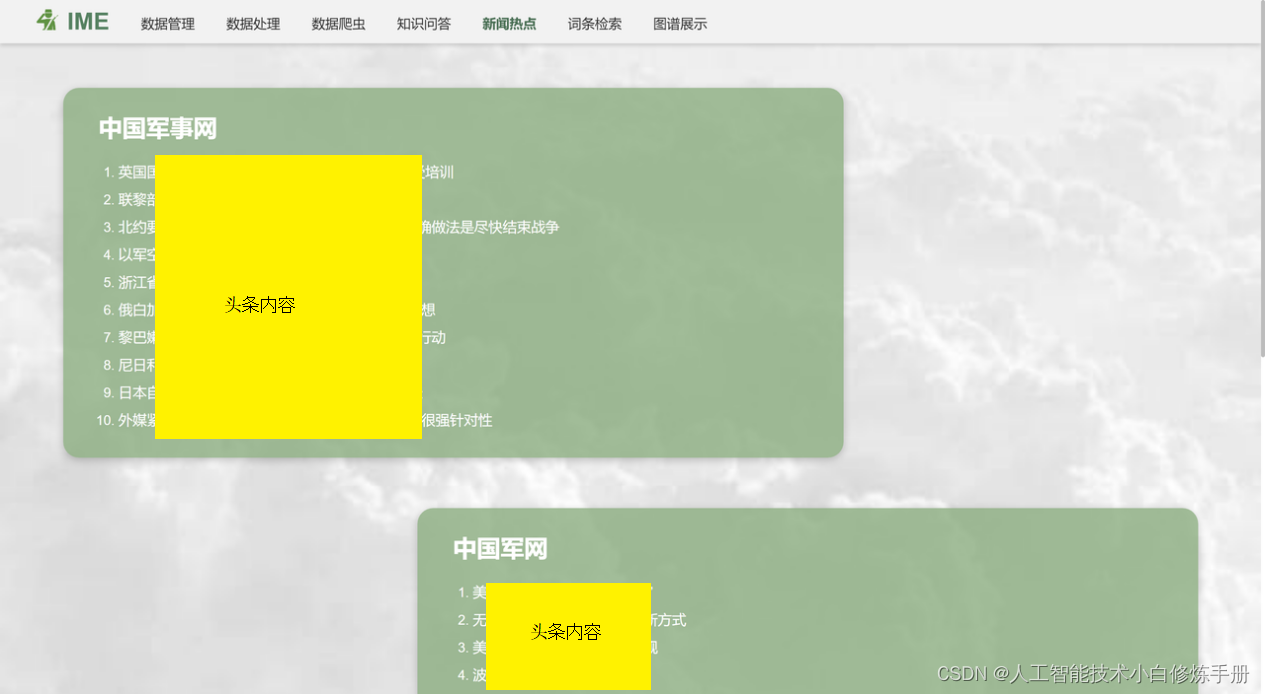
进入新闻热点模块,后台自动爬取“中国JS网”、“中国J网”和“央广JS网”的新闻头条,并返回前端进行渲染,渲染结果如下图所示。
功能设计:①进入网页后自动更新最新的JS新闻、②点击新闻列表的内容,自动跳转到相关新闻页面。
主要代码
前端:News.vue
Html部分
这段代码是一个Vue.js组件的模板(template),包含了一个简单的新闻网站的界面。具体而言,该界面分为三个部分,每个部分都包含了一个标题和一个有序列表,用于展示该网站的新闻列表。
分别从左到右而言,它们依次为:
- "中国XX网",其中
news1定义了一个新闻列表数组,每个元素包含了一个新闻标题和其对应的URL链接。使用了Vue.js的v-for指令进行遍历渲染。 - "中国X网",其中
news2也定义了一个新闻列表。 - "央广XX网",其中
news3也定义了一个新闻列表。
在每个新闻条目(<li>标签)中,使用了绑定语法(:href)来动态设置超链接的目标URL,并使用target="_blank"设置在新标签页中打开链接。
Script部分
这段代码是一个Vue.js组件的定义,主要实现了以下功能:
1. 定义了一个名称为"News"的Vue组件,且不依赖于任何外部数据或属性(props为空对象)。
2. 在data()函数中定义了该组件的局部数据,包括三个新闻列表:news1,news2,news3,它们都是空数组。
3. 在getNews()方法中,使用axios库向服务器发送GET请求"GetNews",并将返回的新闻数据保存在定义的数组中。具体而言,当接收到响应时,该函数将会将服务器返回的数据指定给本地的三个新闻列表。当请求失败时,弹出提示窗口:"GetNews failed!"
4. 生命周期钩子中调用getNews()`方法,以获取新闻数据并渲染界面。
<template>
<div style="padding-top: 3%">
<!-- 中国JS网 -->
<div class="web" style="float: left">
<h1 @click="getNews()">中国JS网</h1>
<ol>
<li v-for="(item, index) in news1" :key="index">
<a :href="item[1]" target="_blank">
{{ item[0] }}
</a>
</li>
</ol>
</div>
<!-- 参考信息网 -->
<div class="web" style="float: right">
<h1>中国J网</h1>
<ol>
<li v-for="(item, index) in news2" :key="index">
<a :href="item[1]" target="_blank">
{{ item[0] }}
</a>
</li>
</ol>
</div>
<!-- 央广JS网 -->
<div class="web" style="float: left; margin-bottom: 4%">
<h1>央广JS网</h1>
<ol>
<li v-for="(item, index) in news3" :key="index">
<a :href="item[1]" target="_blank">
{{ item[0] }}
</a>
</li>
</ol>
</div>
</div>
</template>
<script>
export default {
name: "News",
props: {},
data() {
return {
news1:[],
news2:[],
news3:[]
};
},
methods: {
getNews: function () {
this.axios
.get("http://localhost:8000/GetNews")
.then((res) => {
this.news1 = res.data[0];
// console.log(this.news1);
this.news2 = res.data[1];
// console.log(this.news1);
this.news3 = res.data[2];
// console.log(this.news1);
})
.catch((error) => {
alert("GetNews failed!");
});
},
},
mounted() {
this.getNews();
},
};
</script>
<style scoped>
.web {
background-color: rgba(140, 174, 129, 0.8);
color: white;
padding-left: 70px;
padding-right: 40px;
padding-top: 20px;
width: 55%;
border-radius: 20px;
margin: 4% 5% 0% 5%;
box-shadow: rgb(0 0 0 / 20%) 0px 3px 10px;
}
h1 {
font-size: 30px;
font-weight: bolder;
color: white;
margin-left: -25px;
margin-top: 10px;
margin-right: 40px;
float: left;
}
.web > ol > li {
float: left;
width: 780px;
color: white;
line-height: 35px;
}
.web > ol > li:first-child {
margin-top: 20px;
}
.web > ol > li:last-child {
margin-bottom: 30px;
}
li:hover {
font-weight: bold;
}
.web > ol > li > a {
color: white;
font-size: 18px;
}
</style>后端
工具函数
这段代码定义了两个函数download(url, user_agent='wswp', num_retries=2)和get_content(page_url),用于下载网页HTML并获取页面内容。
具体而言,download()函数实现了:
- 使用
urllib.request.Request()方法创建一个Request对象,并使用指定的User-Agent头部信息发送HTTP请求。 - 发送HTTP请求并获取响应数据。
- 如果出现URLError异常,则打印错误信息并尝试重新下载网页(最多重试2次)。如果服务器返回5xx错误,则同样尝试重新下载网页。
- 返回获得的HTML内容。
而get_content()函数则实现了:
- 调用
download()函数下载指定URL的HTML内容,并对其进行解析,使用了BeautifulSoup模块进行HTML解析。 - 如果下载失败,则打印一条错误消息并退出程序;否则,返回解析后的HTML文档对象。
这两个函数通常用于Web爬虫或网站数据抓取等场景中,用爬取指定页面的HTML内容,进而提取需要的信息和数据。
# 下载网页html
def download(url, user_agent='wswp', num_retries=2):
print('downloading: %', url)
# 防止对方禁用Python的代理,导致forbidden错误
headers = {'User-agent': user_agent}
request = urllib.request.Request(url, headers=headers)
try:
html = urllib.request.urlopen(request).read()
except urllib.error.URLError as e:
print('download error:', e.reason)
html = None
if num_retries > 0:
# URLError是一个上层的类,因此HttpERROR是可以被捕获到的。code是HttpError里面的一个字段
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, num_retries - 1)
return html
# 获得页面内容
def get_content(page_url):
html_result = download(page_url)
if html_result is None:
print('is None')
exit(1)
else:
pass
# 分析得到的结果,从中找到需要访问的内容
soup = BeautifulSoup(html_result, 'html.parser')
return soup请求头配置
headers = {
# 用户代理
'User-Agent': '"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"'
}
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]主要函数
这段代码定义了一个名为GetNews()的函数,用于获取三个新闻网站的头条新闻,并返回一个包含这些新闻数据的二维数组allNews。具体过程如下:
- 声明了一个空数组
allNews,用于存储所有的新闻数据。 - 针对每个网站,调用
get_content()函数获得该网站的HTML文档对象。 - 针对每个网站,通过分析HTML文档对象,获取到该网站的新闻页面中的头条新闻,并提取出这些新闻的标题和URL链接,并将它们以[title, link]的形式添加到
pairs数组中。 - 将每个网站提取到的新闻数据的
pairs数组添加到allNews数组中,形成一个二维数组。 - 返回
allNews数组。 在代码中存在多处占位符'',这里我们并不知道其实际URL值,需要根据实际情况进行替换和确认。
# 获取新闻头条
def GetNews():
allNews = []
# 中国JS网
second_html = get_content('http://military.china.com.cn/')
pairs = []
num_list = second_html.find('div', attrs={'class': "layout_news"})
num_list = num_list.find_all('div', attrs={'class': "plist1"})
for i in num_list[:10]:
# 提取头条文本和链接
pairs.append([i.find('a').text, i.find('a')['href']])
allNews.append(pairs)
# 中国J网
second_html = get_content('http://www.81.cn/bq_208581/index.html')
pairs = []
num_list = second_html.find('ul', attrs={'id': "main-news-list"})
num_list = num_list.find_all('li')
for i in num_list[:10]:
# 提取头条文本和链接
pairs.append([i.find('img')['alt'],i.find('a')['href']])
allNews.append(pairs)
# 央广JS网
second_html = get_content('https://military.cnr.cn/zdgz/')
pairs = []
num_list = second_html.find('div', attrs={'class': "articleList"})
num_list = num_list.find_all('div', attrs={'class': 'item url_http'})
for i in num_list:
# 提取头条文本和链接
pairs.append([i.find('strong').text,i.find('a')['href']])
print(pairs)
allNews.append(pairs)
return allNews

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)