sqoop 导hive数据到mysql报错:Job job_1678187301820_35200 failed with state FAILED due to: Task failed task_
明显把 这一条数据当作一个字段处理,解析不了,说明--input-fields-terminated-by '\001' \ 分隔符有问题,我查看了下hive表分隔符使用的是 \t。然后把分割符改为 --input-fields-terminated-by '\t' \问题解决。2.如果上面一致的话,寻找错误需要查看yarn运行日志,因为sqoop是靠yarn调度的。1.首先确保hive表的字段和
首先使用sqoop导hive数据到mysql命令:
/home/data/office/sqoop-1.4.6-cdh5.14.0/bin/sqoop export --connect 'jdbc:mysql://****.com:3306/test' \
--username '**' \
--password '123**' \
--table 'bidata_residents_base_20230410' \
--export-dir /user/hive/warehouse/dwd.db/bidata_residents_base_20230408 \
--input-fields-terminated-by '\001' \
--input-null-string '\\N' \
--input-null-non-string '\\N'
参数说明:
--connect '数据库连接' \
--username '数据库账号' \
--password '数据库密码' \
--table '数据库表名' \
--export-dir 集群hdfs中导出的数据目录 \
--input-fields-terminated-by '分隔符,textfile类型默认\001' \
--input-null-string '空值处理:\\N' \
--input-null-non-string '空值处理:\\N'1.首先确保hive表的字段和数据类型和mysql一致。
2.如果上面一致的话,寻找错误需要查看yarn运行日志,因为sqoop是靠yarn调度的。通过yarn的web页面查看你刚刚运行sqoop的applicationId
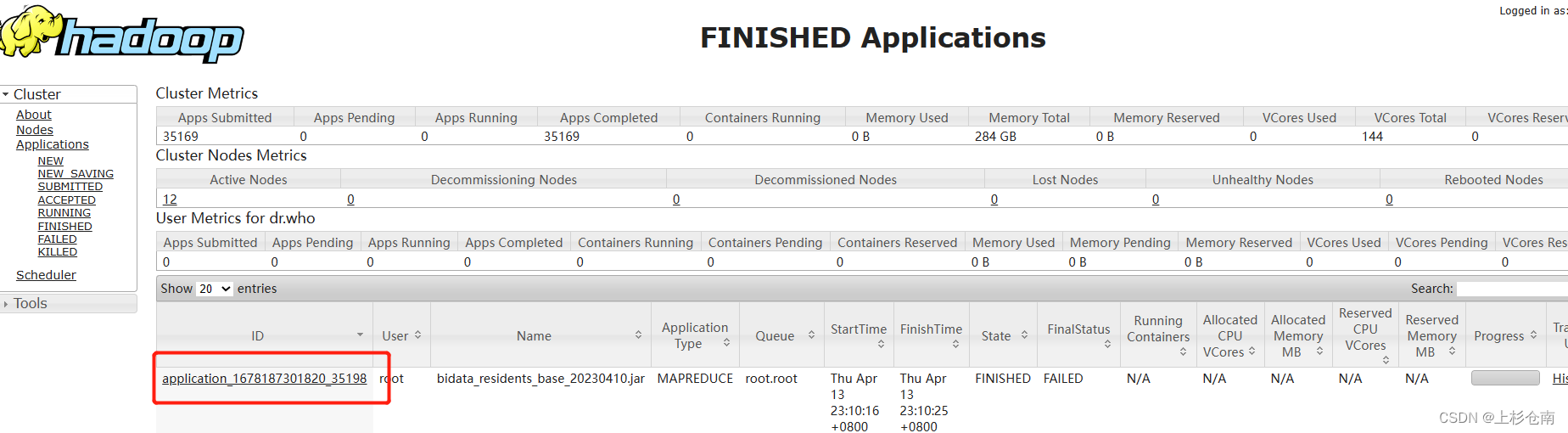
当然也可以使用命令行获取application(这里就不说了)
然后执行下面命令
yarn logs -applicationId application_1678187301820_35198
获取报错日志:
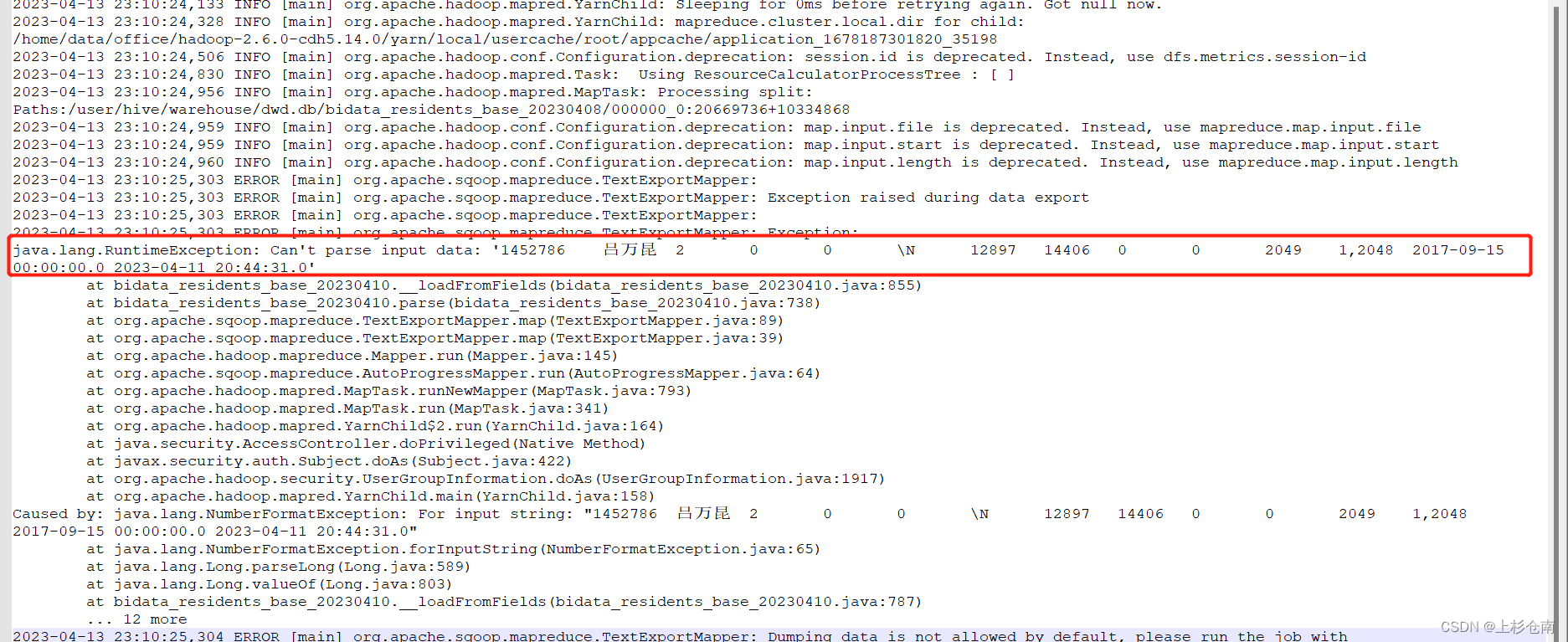
明显把 这一条数据当作一个字段处理,解析不了,说明--input-fields-terminated-by '\001' \ 分隔符有问题,我查看了下hive表分隔符使用的是 \t 。然后把分割符改为 --input-fields-terminated-by '\t' \问题解决。
ps:遇到这些问题别慌,找日志,找到日志就很好解决了。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)