Spark_SQL-DataFrame数据写出以及读写数据库(以MySQl为例)_dataframe mysql option
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
appName('write').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
# 1.读取文件
schema = StructType().add('user_id', StringType(), nullable=True).\
add('movie_id', IntegerType(), nullable=True).\
add('rank', IntegerType(), nullable=True).\
add('ts', StringType(), nullable=True)
df = spark.read.format('csv').\
option('sep', '\t').\
option('header', False).\
option('encoding', 'utf-8').\
schema(schema=schema).\
load('../input/u.data')
# write text 写出,只能写出一个列的数据,需要将df转换为单列df
df.select(F.concat_ws('---', 'user_id', 'movie_id', 'rank', 'ts')).\
write.\
mode('overwrite').\
format('text').\
save('../output/sql/text')
# write csv
df.write.mode('overwrite').\
format('csv').\
option('sep',';').\
option('header', True).\
save('../output/sql/csv')
# write json
df.write.mode('overwrite').\
format('json').\
save('../output/sql/json')
# write parquet
df.write.mode('overwrite').\
format('parquet').\
save('../output/sql/parquet')

#### 二、写出MySQL数据库
API写法:

**注意:**
①jdbc连接字符串中,建议使用useSSL=false 确保连接可以正常连接( 不使用SSL安全协议进行连接)
②jdbc连接字符串中,建议使用useUnicode=true 来确保传输中不出现乱码
③save()不要填参数,没有路径,是写出数据库
④dbtable属性:指定写出的表名
cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType
import pyspark.sql.functions as F
if name == ‘main’:
spark = SparkSession.builder.
appName(‘write’).
master(‘local[*]’).
getOrCreate()
sc = spark.sparkContext
# 1.读取文件
schema = StructType().add('user_id', StringType(), nullable=True).\
add('movie_id', IntegerType(), nullable=True).\
add('rank', IntegerType(), nullable=True).\
add('ts', StringType(), nullable=True)
df = spark.read.format('csv').\
option('sep', '\t').\
option('header', False).\
option('encoding', 'utf-8').\
schema(schema=schema).\
load('../input/u.data')
# 2.写出df到MySQL数据库
df.write.mode('overwrite').\
format('jdbc').\
option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=false&useUnicode=true&serverTimezone=GMT%2B8').\
option('dbtable', 'movie_data').\
option('user', 'root').\
option('password', '123456').\
save()
# 读取
df2 = spark.read.format('jdbc'). \
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
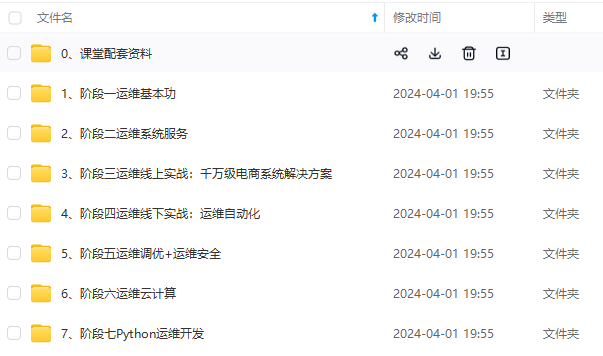
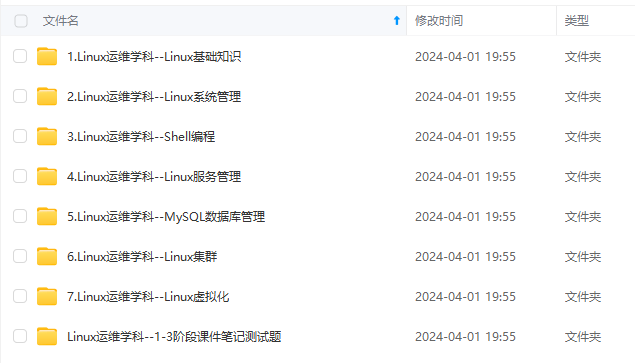
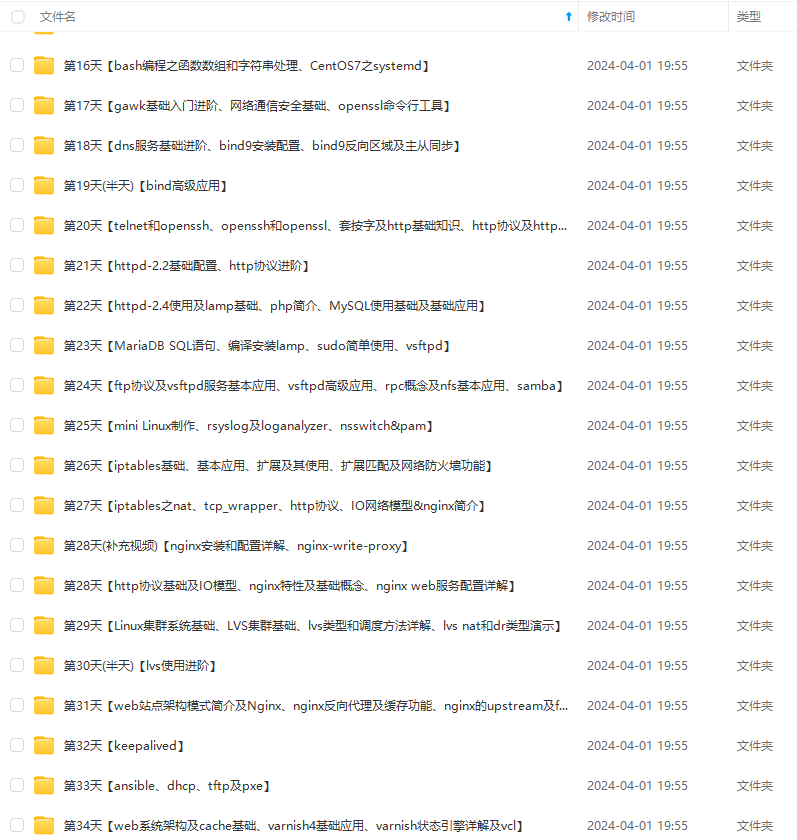
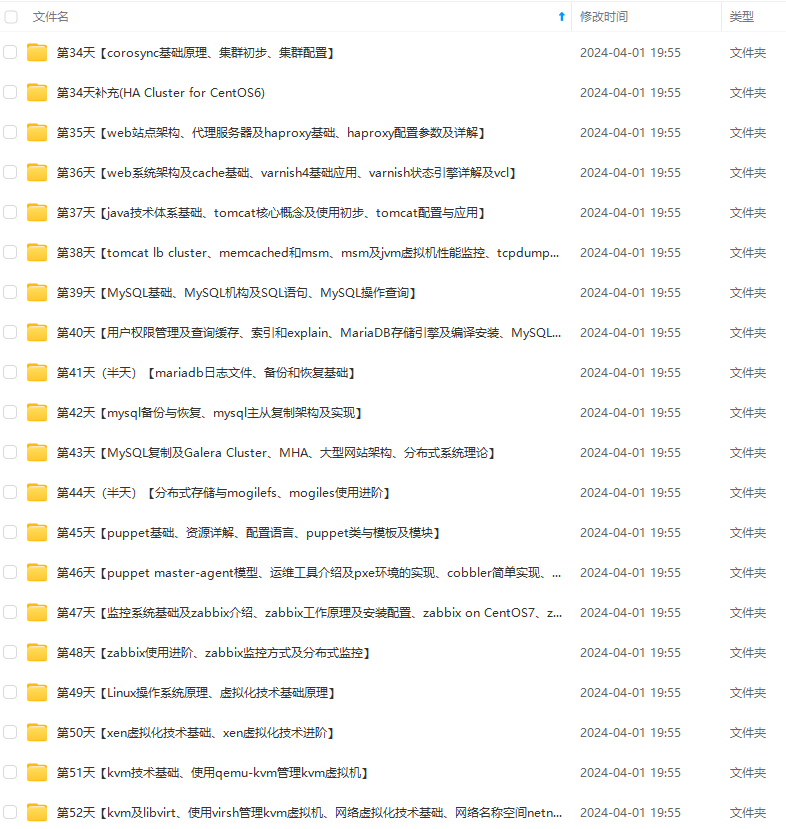
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)
最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
**
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-0IM26MBI-1713073268570)]

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)