【数据分析入门】R语言函数入门及常用语句
文章目录一、R函数1. 线性回归2. 概率分布函数3. 生成随机数4. 描述性统计函数5. 频数统计函数一、R函数1. 线性回归state <- as.data.frame(state.x77[,c("Murder" ,"Population","Illiteracy","Income", "Frost")])fit<-lm(Murder~Population+Illiteracy+I
·
一、R函数
1. 线性回归
state <- as.data.frame(state.x77[,c("Murder" ,"Population","Illiteracy","Income", "Frost")])
fit<-lm(Murder~Population+Illiteracy+Income+Frost,data=state)
summary(fit)
可以看出在P<0.001的情况下,Illiteracy的系数显著不为0
其他因子没有显著不为0,判断无相关关系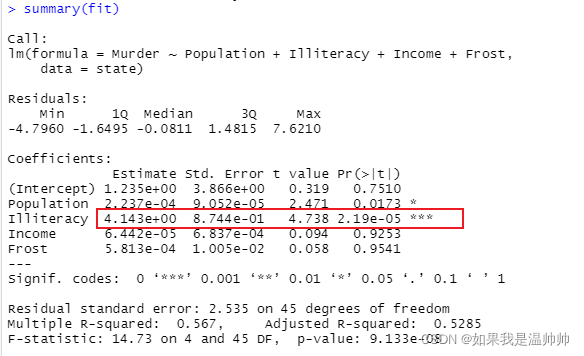
2. 概率分布函数
##正态分布
?Normal
rnorm(50, mean = 0, sd = 1)
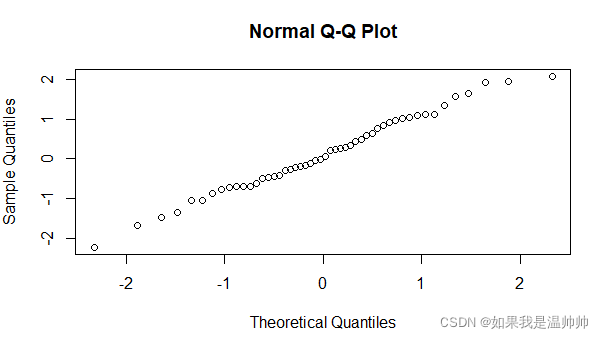
x<-rnorm(50, mean = 0, sd = 1)
qqnorm(x)
##Beta分布
?beta
##Logistic分布
?logis
##二项分布
?binom.test()
##多项分布
?multinom
##柯西分布
cauchy
##负二项分布
?nbinom
##卡方分布
?chisq
##指数分布
?exp
##泊松分布
?pois
##F分布
?f
##符号秩分布
?signrank
##Gamma分布
?gamma
##几何分布
?geom
##均匀分布
?unif
##超几何分布
?hyper
##Weibull分布
?weibull
##对数正态分布
Inorm
##Wilcoxon秩和分布
?wilcox
如何检验数据集满足某种分布
后续更新
3. 生成随机数
?runif
runif(1)
runif(50)
#生成50个,1-100的随机数
runif(50,min=1,max=100)
set.seed(111)
runif(50)
#绑定seed,可以生成相同随机数
set.seed(111)
runif(50)
4. 描述性统计函数
描述分布
summary(myvars)
fivenum(myvars$hp)
tDescriptive stats via stat.desc (pastecs) install.packages("pastecs") library(pastecs)
stat.desc(mtcars[myvars])
stat.desc(mtcars,basic = TRUE,desc=TRUE,norm = TRUE)
library(psych)
describe(mtcars[myvars],trim =0.1) Hmisc::describe(mtcars)
聚合后分布
library(MASS)
aggregate(Cars93[c("Min.Price","Price","Max.Price","MPG.city")],
by=list(Manufacturer=Cars93$Manufacturer),mean)
aggregate(Cars93[c("Min.Price","Price","Max.Price","MDG.city")],
byslist(Manufacturer=Cars93$Manufacturer),sd)
aqareqate(Cars93[c("Min.Price","Price","Max.Price","MPG.city")],
by=list(origin=Cars93$origin),mean)
agqregate(Cars93[c("Min.Price","Price" "Max.Price","MPG.city")],
by=list(origin=Cars93$origin) ,sd)
aggregate(Cars93[c("Min.Price","Price","Max.Price","MPG.city")],
by=list(origin=Cars93$origin,Manufacturer=Cars93$Manufacturer),mean]
根据自变量因子分类后,其他因子分布描述
library(doBy)
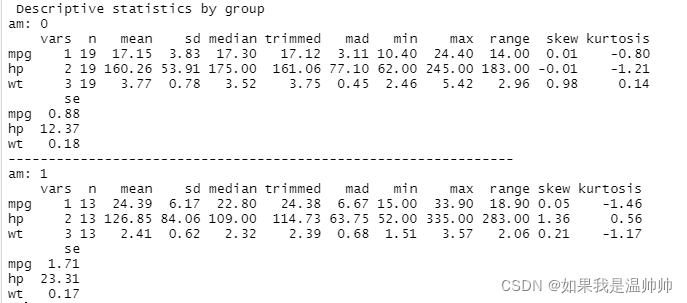
summaryBy(mpg+hp+wt~am,data=mtcars,FUN=mean)
myvars <- c("mpg","hp","wt")
library(psych)
describeBy(mtcars[myvars],list(am=mtcars$am))

5. 频数统计函数
#分组
mtcars$cyl<-as.factor(mtcars$cyl)
split(mtcars,mtcars$cyl)
split(mtcars,as.factor(mtcarsScyl))
#切割
num <-1:100
cut (num,c(seq(0,100,10)))
cut (mtcars$mpg,c(seq(10,50,10)))
##频数统计
table(mtcars$cyl)
table(cut(mtcars$mpg,c(seq(10,50,10))))
##频率函数
prop.table(table(mtcars$cyl))
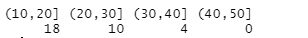
> library("grid")
> library("vcd")
> table(Arthritis$Treatment,Arthritis$Improved)
> ?margin.table
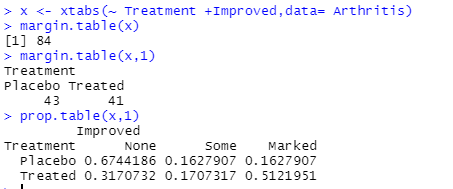
x <- xtabs(~ Treatment +Improved,data= Arthritis)
margin.table(x)
margin.table(x,1)
prop.table(x,1)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)