Python数据分析实战-根据索引合并两个dataframe
Python数据分析实战-根据索引合并两个dataframe
·
前面我介绍了可视化的一些方法以及机器学习在预测方面的应用,分为分类问题(预测值是离散型)和回归问题(预测值是连续型)(具体见之前的文章)。
从本期开始,我将做一个数据分析类实战的系列文章,列举一些在平时数据处理中遇到的一些小问题,提供一个解决方案,让读者慢慢理解python数据分析的原理和方法,每一篇文章从实现功能、实现代码、实现效果三个方面进行展示。
实现功能:
使用pandas提供的join函数,根据索引合并两个dataframe。
实现代码:
import pandas as pd
from pandas import Series,DataFrame
# 创建一个dataframe
left1 = DataFrame({'水果':['苹果','梨','草莓'],
'价格':[3,4,5],
'数量':[9,8,7]})
# 将dataframe中的某一列设置为索引
left1=left1.set_index('水果')
# 创建一个dataframe
right1 = DataFrame({'水果':['苹果','草莓','梨'],
'产地':['美国','中国','法国']})
# 将dataframe中的某一列设置为索引,
# 这里水果单独占一行,不过后面写入文件保存时会和表头对齐,不用纠结它
right1=right1.set_index('水果')
#打印出两个dataframe
print(left1)
print(right1)
# join函数默认将两个DataFrame的index进行合并
j1=left1.join(right1)
print(j1)
实现效果:
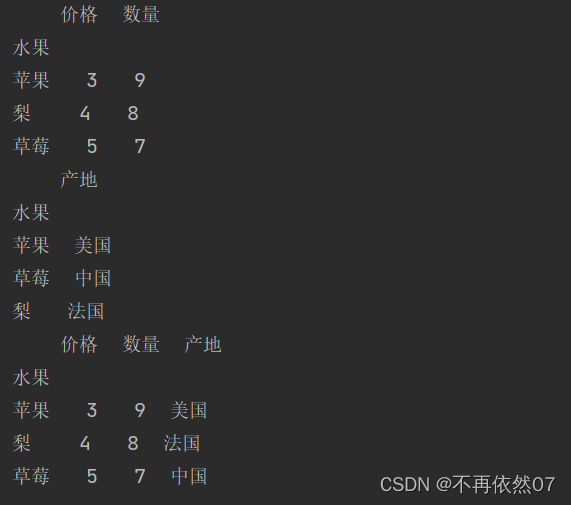
本人读研期间发表5篇SCI数据挖掘相关论文,现在在某研究院从事数据挖掘相关工作,对数据挖掘有一定的认知和理解,会不定期分享一些关于python机器学习、深度学习、数据挖掘基础知识与案例。
致力于只做原创,不追求内容量,只为以最简单的方式让你理解和学习它们,关注数据杂坛与我一起交流成长。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)