如何选择合适的排序算法?
如果要实现一个通用的、高效率的排序函数,我们应该选择哪种排序算法?我们先回顾一下前面讲过的几种排序算法。我们前面讲过,线性排序算法的时间复杂度比较低,适用场景比较特殊。所以如果要写一个通用的排序函数,不能选择线性排序算法。如果对小规模数据进行排序,可以选择时间复杂度是 O(n^2) 的算法;如果对大规模数据进行排序,时间复杂度是 O(nlogn) 的算法更加高效。所以,为了兼顾任意规模数据的排序,
如果要实现一个通用的、高效率的排序函数,我们应该选择哪种排序算法?我们先回顾一下前面讲过的几种排序算法。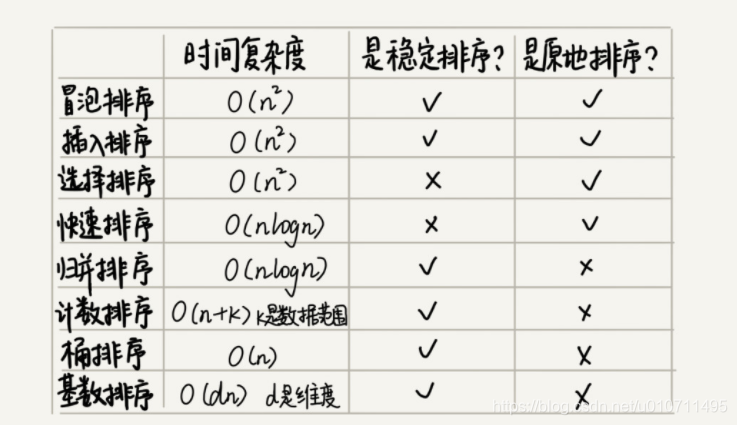
我们前面讲过,线性排序算法的时间复杂度比较低,适用场景比较特殊。所以如果要写一个通用的排序函数,不能选择线性排序算法。
如果对小规模数据进行排序,可以选择时间复杂度是 O(n^2) 的算法;如果对大规模数据进行排序,时间复杂度是 O(nlogn) 的算法更加高效。所以,为了兼顾任意规模数据的排序,一般都会首选时间复杂度是 O(nlogn) 的排序算法来实现排序函数。
时间复杂度是 O(nlogn) 的排序算法不止一个,我们已经讲过的有归并排序、快速排序,后面讲堆的时候我们还会讲到堆排序。堆排序和快速排序都有比较多的应用,比如 Java 语言采用堆排序实现排序函数,C 语言使用快速排序实现排序函数。
不知道你有没有发现,使用归并排序的情况其实并不多。我们知道,快排在最坏情况下的时间复杂度是 O(n^2),而归并排序可以做到平均情况、最坏情况下的时间复杂度都是 O(nlogn),从这点上看起来很诱人,那为什么它还是没能得到“宠信”呢?
归并排序并不是原地排序算法,空间复杂度是 O(n)。所以,粗略点、夸张点讲,如果要排序 100MB 的数据,除了数据本身占用的内存之外,排序算法还要额外再占用 100MB 的内存空间,空间耗费就翻倍了。
总结
- 实际生产中一般采用
快排或堆排序,时间复杂度低O(nlogn)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)