mysql 回表查询优化_MySQL优化:如何避免回表查询
InnoDB有两大类索引:聚集索引(clustered index)和普通索引(secondary index)nnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:(1)如果表定义了PK,则PK就是聚集索引;(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;InnoD
InnoDB有两大类索引:聚集索引(clustered index)和普通索引(secondary index)
nnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
InnoDB普通索引的叶子节点存储主键值。

两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。
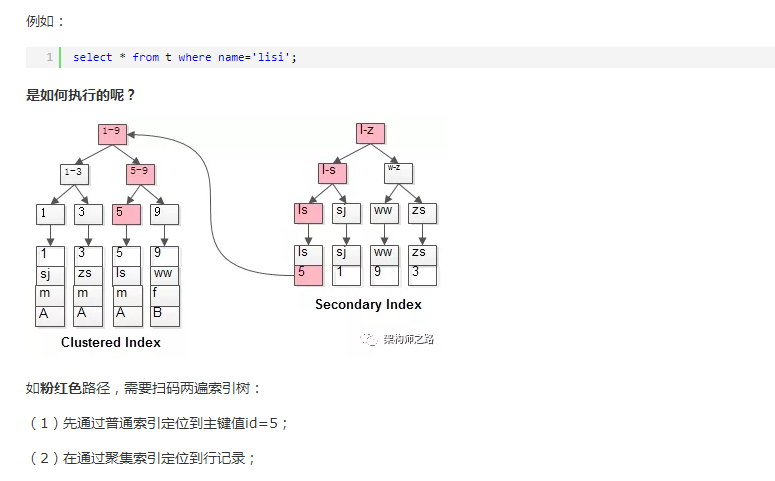
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
总结:回表查询就是查询时先定位主键值,再定位行记录,会查询2次索引树。
如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
如将下面第二个查询中sex加入到联合索引中,就不需要回表了。
select id,name from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
explain sql 显示 Extra:Using index。说明没有回表
select id,name,sex from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
explain sql 显示Extra:Using index condition。说明需要回表
详细描述见本文第一行引用的链接

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)