Python数据分析-合肥市AQI预测(聚类和回归分析)
合肥市AQI预测(聚类和回归分析)
一、研究背景
随着城市化进程的加快和工业化水平的提高,空气污染问题日益严重。工业生产、交通运输和日常生活中的各种排放物都对大气环境造成了不同程度的污染,成为影响公众健康和生活质量的重要因素。因此,空气质量问题已成为亟待解决的环境保护和公共卫生问题。。。
二、研究意义
空气质量指数(AQI)作为衡量空气污染程度的综合指标,能够反映出空气中的多种污染物对人体健康的综合影响。通过对空气质量的分析和预测,可以为环境管理和政策制定提供科学依据,帮助相关部门采取有效措施改善空气质量,保障公众健康。。。。
三、实证分析
首先读取数据集展示数据前五行
import matplotlib.pyplot as plt
import seaborn as snsimport pandas as pd
file_path = '合肥四月份AQI(1).csv'
data = pd.read_csv(file_path)
data.head()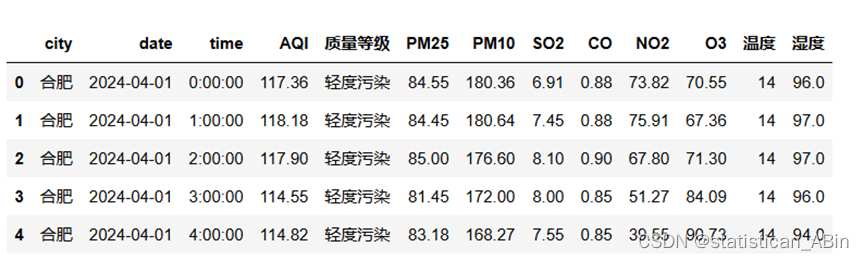 包含城市、日期、时间、AQI(空气质量指数)、质量等级、PM2.5、PM10、SO2、CO、NO2、O3、温度和湿度等指标。
包含城市、日期、时间、AQI(空气质量指数)、质量等级、PM2.5、PM10、SO2、CO、NO2、O3、温度和湿度等指标。
随后检查数据缺失值

从上面结果可以发现数据不存在缺失值
接下来对数据进行描述性统计
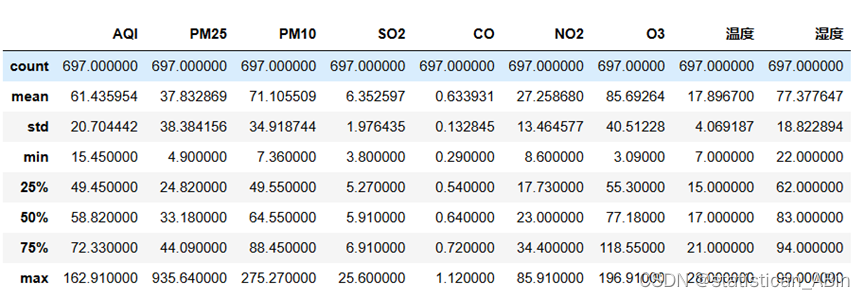
统计量包括总数(count)、平均值(mean)、标准差(std)、最小值(min)、25百分位数(25%)、中位数(50%)、75百分位数(75%)和最大值(max)。AQI的平均值为61.44,表明总体空气质量在轻度污染范围内波动。。。。
接下来可视化数据集
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.figure(figsize=(12, 6),dpi=200)
sns.boxplot(data=data[['AQI']])
plt.title('Boxplot of Air Quality Indicators')
plt.show()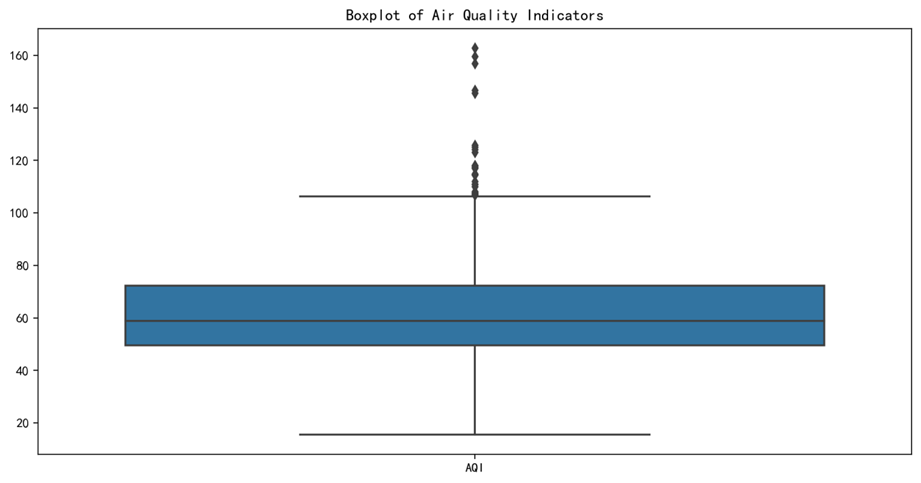
中位数靠近箱体中心,表明数据是相对对称的。箱体的高度适中,显示数据的四分位距(IQR)较小,数据的中间50%的范围不是很宽。上须和下须都显示了一些数据的扩展范围。。。。
# 时间跨度为5天
plt.figure(figsize=(14, 7), dpi=200)
plt.plot(data['datetime'], data['AQI'], label='AQI', color='blue')
plt.title('合肥四月份空气质量指数(AQI)变化', fontsize=14)
plt.xlabel('时间', fontsize=12)
plt.ylabel('AQI', fontsize=12)
plt.xticks(pd.date_range(start=data['datetime'].min(), end=data['datetime'].max(), freq='5D'), rotation=45)
plt.legend()
plt.grid(True)
plt.show()
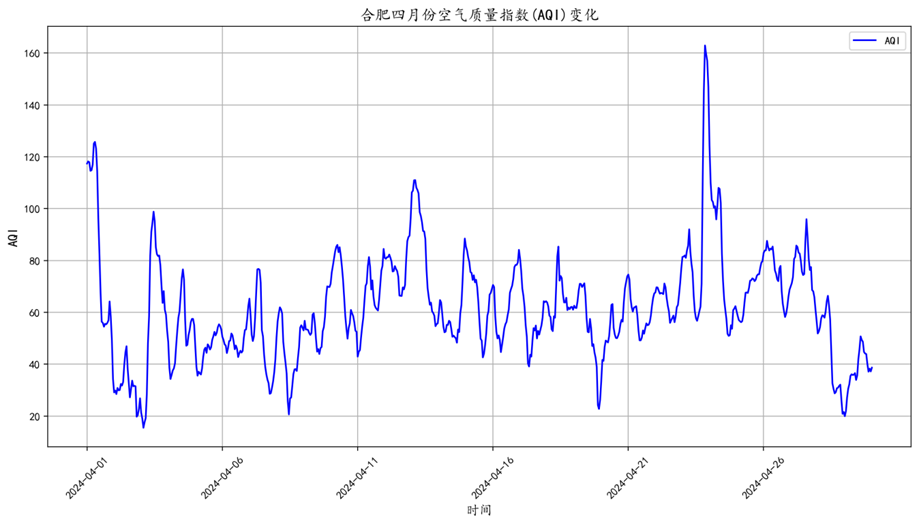
从图中可以看到,AQI值在整个时间段内有较大的波动。在某些时间点,AQI值显著升高,这可能是由于某些污染事件或天气条件的变化所导致的。在某些时间段,AQI值急剧上升,达到了峰值。。。。
相关系数热力图
plt.figure(figsize=(10, 8),dpi=200)
correlation_matrix = data[['AQI', 'PM25', 'PM10', 'SO2', 'CO', 'NO2', 'O3', '温度', '湿度']].corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Heatmap of Correlation Matrix')
plt.show()
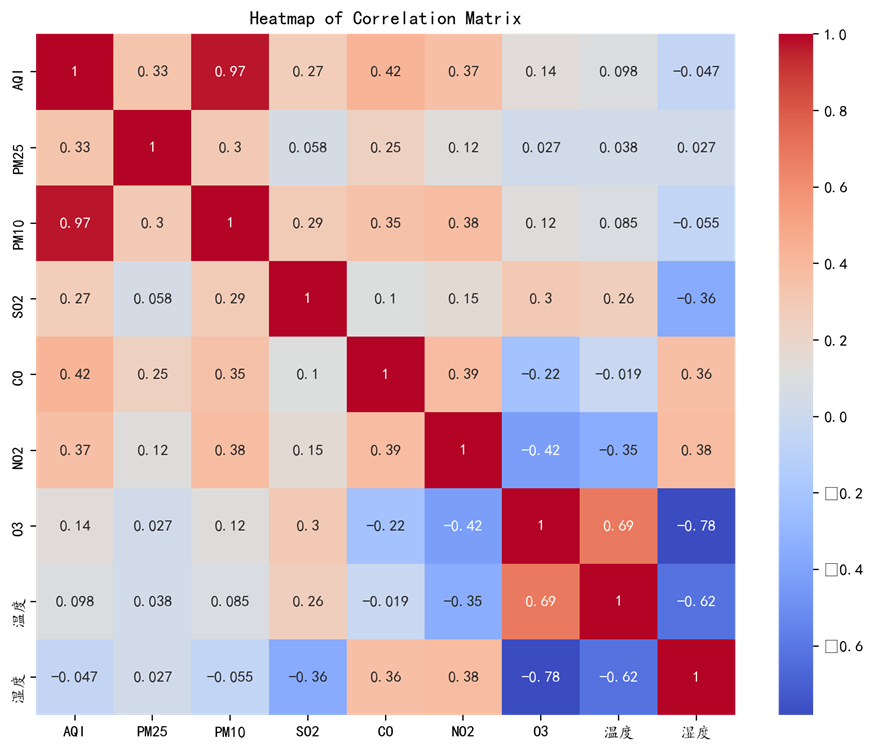
从图中可以看出,PM2.5和PM10之间有非常强的正相关关系(相关系数接近1),这表明这两种污染物通常同时出现。此外,AQI与PM2.5和PM10也有强正相关关系。。
使用K-means聚类分析空气质量数据
手肘法确定聚类数:
# 绘制手肘法图形
plt.figure(figsize=(10, 6),dpi=200)
plt.plot(range(1, 11), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method for Optimal Number of Clusters')
plt.grid(True)
plt.show()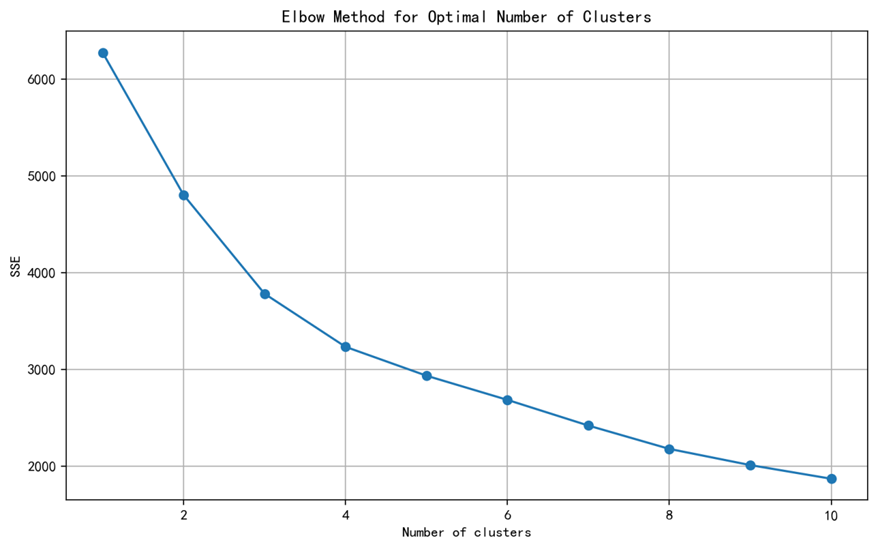
从图中我看到k在5处,其sse逐步放缓
接下来进行聚类,结果如下:
# 添加聚类结果到原始数据
data['Cluster'] = clusters
# 绘制聚类结果
plt.figure(figsize=(12, 6),dpi=200)
sns.scatterplot(x='PM25', y='AQI', hue='Cluster', data=data, palette='viridis')
plt.title('K-means Clustering Results')
plt.show() 从图中可以看到,数据点被分为5个不同的簇(Cluster),分别用不同的颜色标识。大多数数据点集中在左侧,且分布较为密集,而右侧有一个明显的离群点。。。。
从图中可以看到,数据点被分为5个不同的簇(Cluster),分别用不同的颜色标识。大多数数据点集中在左侧,且分布较为密集,而右侧有一个明显的离群点。。。。
接下来利用回归方程进行预测
构建线性回归模型
# 回归模型显著性检验
X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
est2 = est.fit()
print(est2.summary())
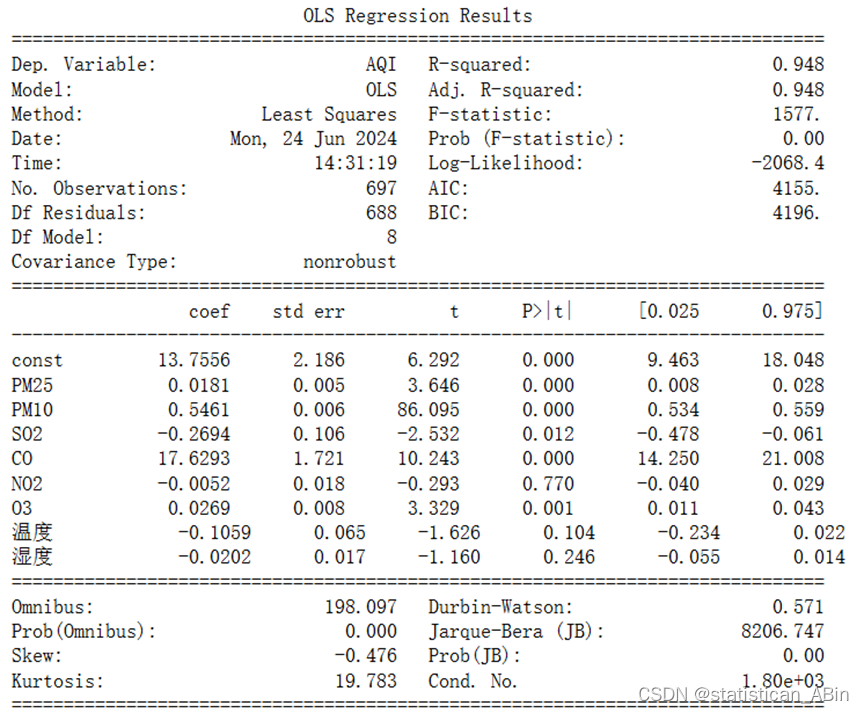
回归模型显著性检验结果表明,该模型在总体上是显著的。F-statistic为1577,Prob (F-statistic)接近0,这意味着模型中的所有自变量对因变量AQI的解释力是显著的。模型的R-squared值为0.948,。。
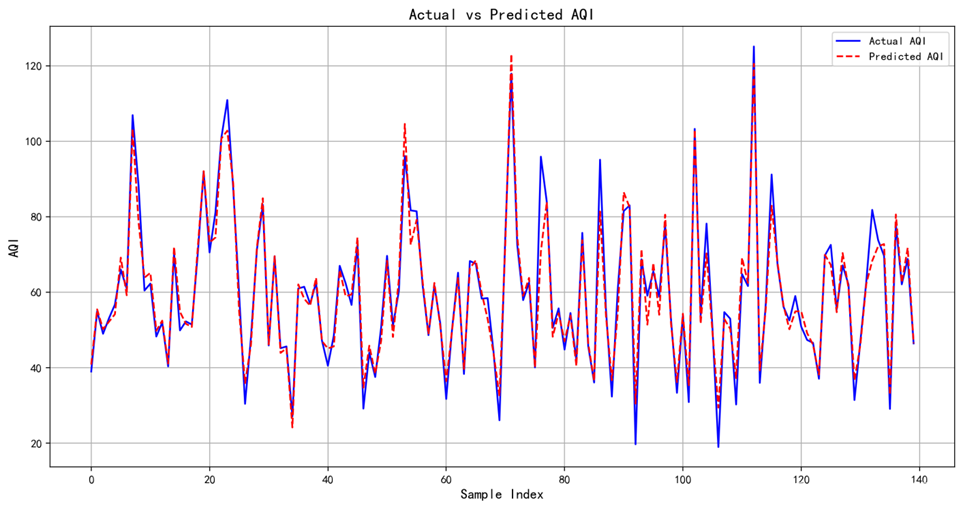
计算误差和R2
Mean Squared Error: 19.124052795347676
R2 Score: 0.9494537895583317、
模型检验
residuals = y_test - y_pred
dw_test = sm.stats.durbin_watson(residuals)
dw_test = sm.stats.durbin_watson(residuals)
dw_test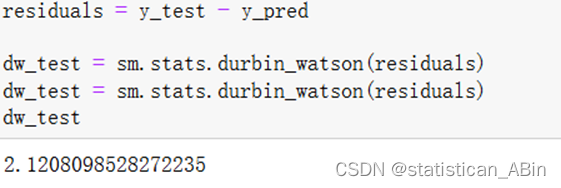
Shapiro-Wilk 检验 正态性
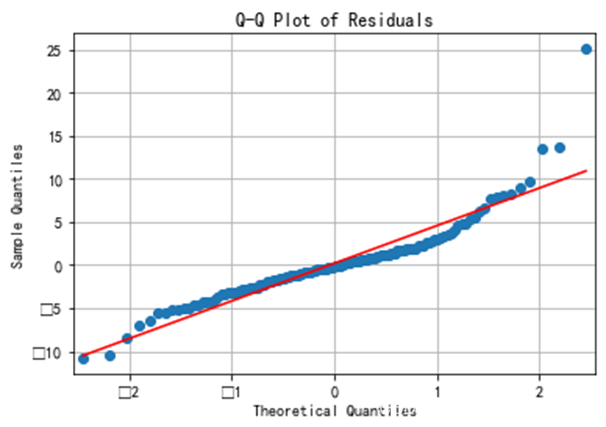
Shapiro-Wilk检验的p值为5.37e-9,远小于0.05,表明残差不服从正态分布。
四、结论
总体来看,本研究为空气质量管理和政策制定提供了有价值的数据支持和科学依据,有助于进一步改善城市环境质量,保障公众健康。研究结果表明,通过科学合理的分析方法和预测模型,可以更准确地掌握空气质量的变化.。。。。
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 25
25 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)