知识图谱实战:图数据库-Neo4j:cypher语言学习
一.cypher语言的基本命令和语法一.cypher语言的基本命令和语法1.create命令: 创建图数据中的节点(1)格式一//创建一个节点对象e,节点标签是Employee, 拥有id, name, salary, deptnp四个属性注意:节点名称 e 是当前语句中的临时变量,节点标签 Employee 才真正保存到图数据库中;
一.cypher语言的基本命令和语法
1.create命令: 创建图数据中的节点
(1)格式一
//创建一个节点对象e, 节点标签是Employee, 拥有id, name, salary, deptnp四个属性
CREATE (e:Employee{id:222, name:'Bob', salary:6000, deptnp:12})
注意:节点名称 e 是当前语句中的临时变量,节点标签 Employee 才真正保存到图数据库中;
不对实例对象进行操作可以不写节点名称e,但是只有拿到对象,才能对对象操作,这是必须的.比如下面你要返回检索的结果

(2)格式二
比如:
CREATE (e:Employee) set e.id=222, e.name='Bob', e.salary=6000, e.deptnp=12
2.match命令: 匹配(查询)已有数据
//匹配节点名称:节点标签,return语句返回查询结果
MATCH (e:Employee) RETURN e.id, e.name, e.salary, e.deptno
3.merge命令:(若节点存在, 则等效与match命令; 节点不存在, 则等效于create命令)
//第一次用这个语句跟上面CREATE命令一样,创建这个实例对象;第二次再用这个语句就相当于MATCH命令了,就是查询这些信息
MATCH (e:Employee) RETURN e.id, e.name, e.salary, e.deptno
4.使用create创建关系
//创建一个节点p1到p2的有方向关系, 这个关系r的标签为Buy, 代表p1购买了p2, 方向为p1指向p2 CREATE (p1:Profile1)-[r:Buy]->(p2:Profile2)
5.使用merge创建关系
可以创建有/无方向性的关系
//创建一个节点p1到p2的无方向关系, 这个关系r的标签为miss, 代表p1-miss-p2, 方向为相互的
MERGE (p1:Profile1)-[r:miss]-(p2:Profile2)
6.where命令: 类似于SQL中的添加查询条件
//查询节点Employee中, id值等于123的那个节点
MATCH (e:Employee) WHERE e.id=123 RETURN e
7.delete命令: 删除节点/关系及其关联的属性.
//注意: 删除节点的同时, 也要删除关联的关系边
MATCH (c1:CreditCard)-[r]-(c2:Customer) DELETE c1, r, c2
//快速清空数据库
MATCH (n) DETACH DELETE n
8.sort命令: Cypher命令中的排序使用的是order by
//匹配查询标签Employee, 将所有匹配结果按照id值升序排列后返回结果
MATCH (e:Employee) RETURN e.id, e.name, e.salary, e.deptno ORDER BY e.id
//如果要按照降序排序, 只需要将ORDER BY e.salary改写为ORDER BY e.salary DESC
MATCH (e:Employee) RETURN e.id, e.name, e.salary, e.deptno ORDER BY e.salary DESC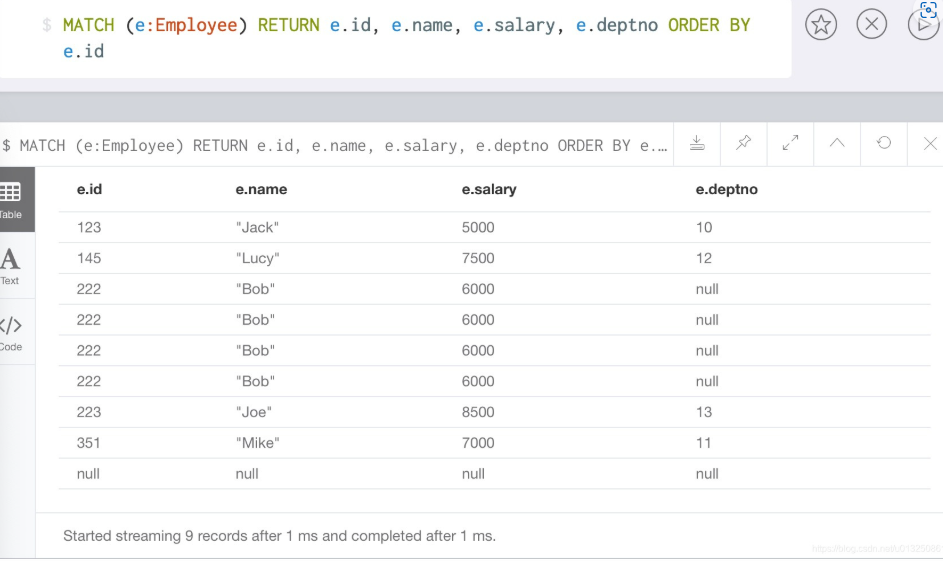
9、字符串函数
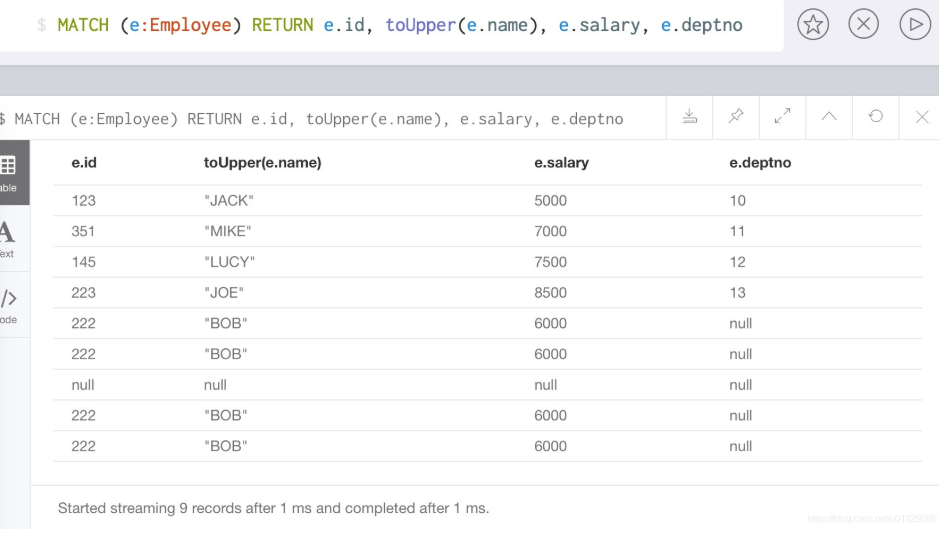
(1)toUpper()函数
//e.name的输入转换为大写字母
MATCH (e:Employee) RETURN e.id, toUpper(e.name), e.salary, e.deptno
 (2)toLower()函数
(2)toLower()函数
//将e.name的输入转换为小写字母
MATCH (e:Employee) RETURN e.id, toLower(e.name), e.salary, e.deptno
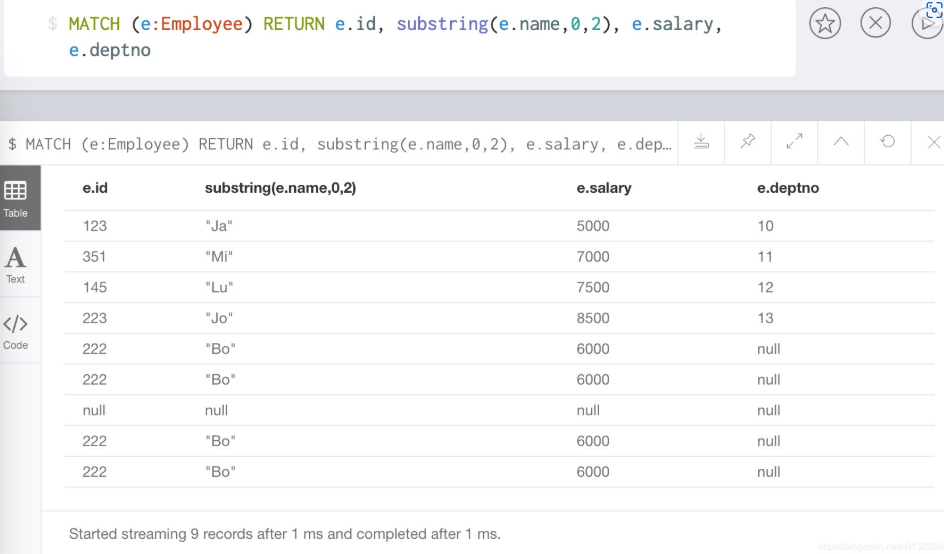
(3)substring()函数
//输入字符串为input_str, 返回从索引start_index开始, 到end_index-1结束的子字符串
substring(input_str, start_index, end_index)
//示例代码, 返回员工名字的前两个字母
MATCH (e:Employee) RETURN e.id, substring(e.name,0,2), e.salary, e.deptno
 (4)replace()函数
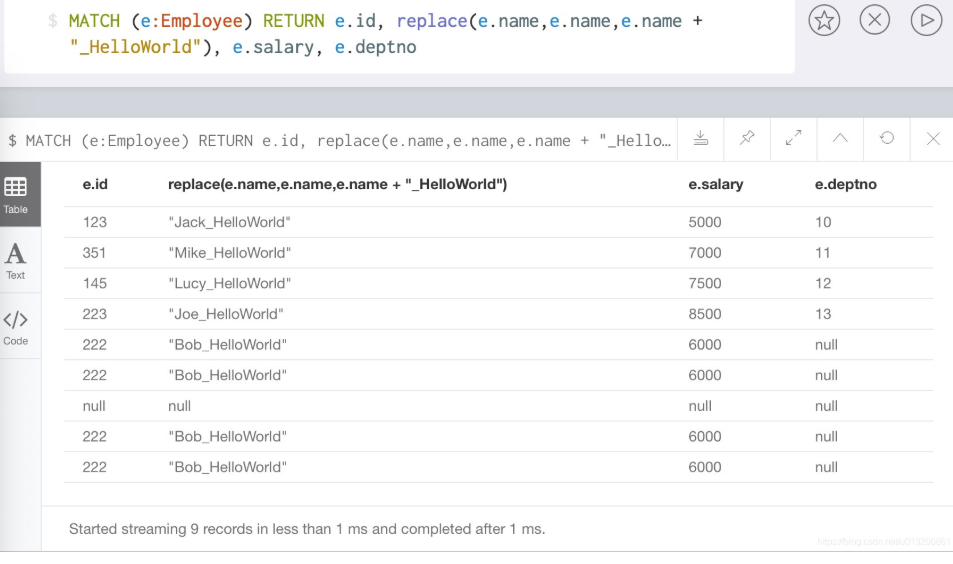
(4)replace()函数
//输入字符串为input_str, 将输入字符串中符合origin_str的部分, 替换成new_str
replace(input_str, origin_str, new_str)
//示例代码, 将员工名字替换为添加后缀_HelloWorld
MATCH (e:Employee) RETURN e.id, replace(e.name,e.name,e.name + "_HelloWorld"), e.salary, e.deptno
 10.聚合函数
10.聚合函数
(1)count()函数
//返回匹配标签Employee成功的记录个数
MATCH (e:Employee) RETURN count( * )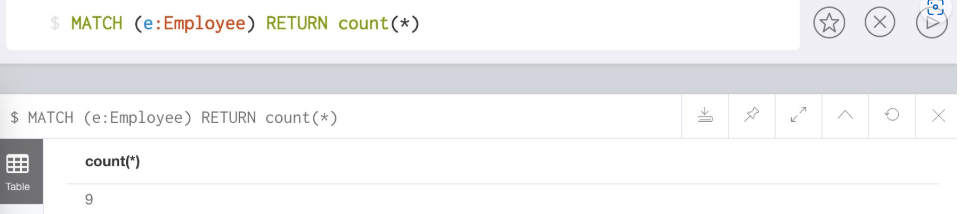
(2)max()函数
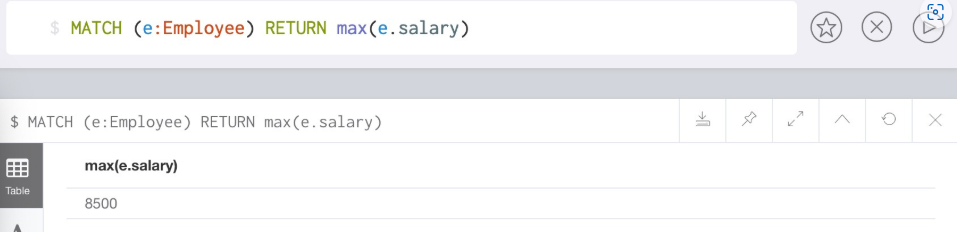
//返回匹配标签Employee成功的记录中, 最高的工资数字
MATCH (e:Employee) RETURN max(e.salary)
 (3)min()函数
(3)min()函数
//返回匹配标签Employee成功的记录中, 最低的工资数字
MATCH (e:Employee) RETURN min(e.salary)
(4)sum()函数
//返回匹配标签Employee成功的记录中, 所有员工工资的和
MATCH (e:Employee) RETURN sum(e.salary)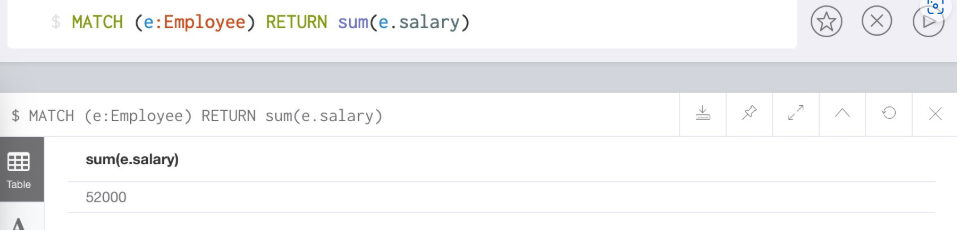
(5)avg()函数
//返回匹配标签Employee成功的记录中, 所有员工工资的平均值
MATCH (e:Employee) RETURN avg(e.salary)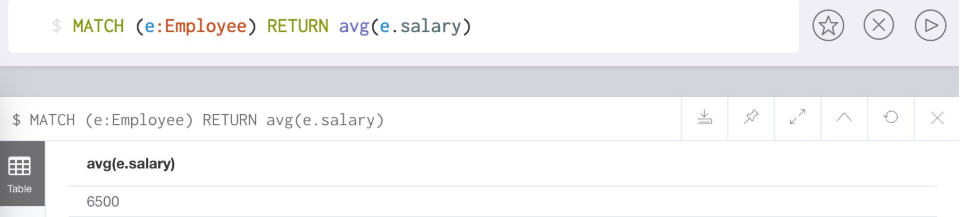
11.索引index
(1)创建索引
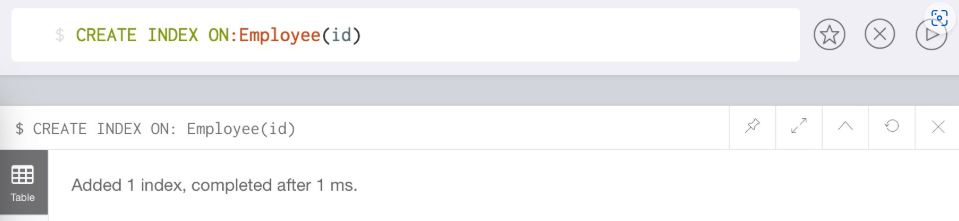
//创建节点Employee上面属性id的索引
CREATE INDEX ON:Employee(id)
(2)删除索引
# 删除节点Employee上面属性id的索引
DROP INDEX ON:Employee(id)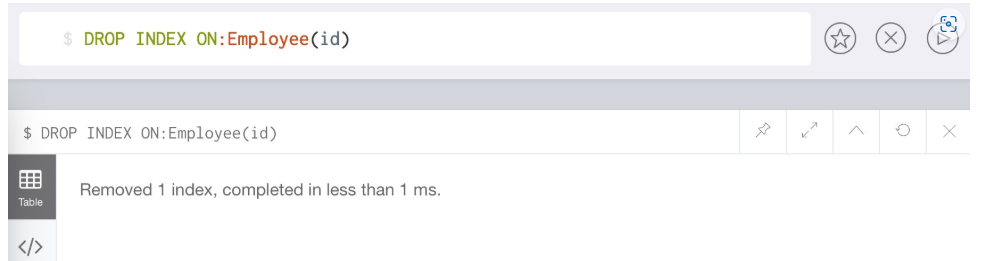
参考资料:图数据库-Neo4j(二):Cypher语法-CSDN博客

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)