Dify+GraphRAG实现知识图谱智能问答,大模型入门到精通,收藏这篇就足够了!
相信各位点进这篇博客的朋友或多或少有与题目相关的需求,目前我的需求是需要将graphrag和dify集成,实现一个大模型根据知识图谱生成回答的功能
前情提要
相信各位点进这篇博客的朋友或多或少有与题目相关的需求,目前我的需求是需要将graphrag和dify集成,实现一个大模型根据知识图谱生成回答的功能,那么本篇要求读者拥有以下基础:
- GraphRAG:本篇使用Graph-Local-Ollama,项目较轻,适合测试
- Dify
- FastAPI
先看结果
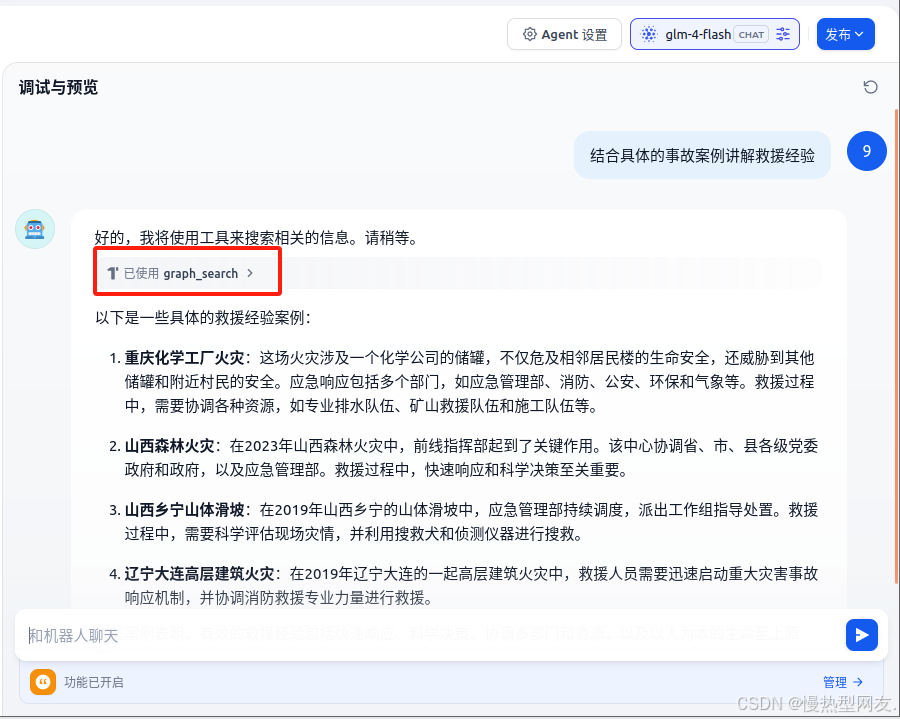
1、问题
最近在研究知识图谱方面,正好目前有个需求是如何将GraphRAG与Dify集成,能让大模型根据知识图谱返回答案,那么就开始在网上搜集资料,在B站上看到一个UP主讲解了一下,感觉还不错,但是因为GraphRAG更新迭代太快,项目结构一直在变,导致不能适配当前我的项目,评论区也有跟我同样诉求的,但是这位UP主的思路可以借鉴,源码地址 ↓https://github.com/brightwang/graphrag-dify
2、思路
(1)获取GraphRAG的上下文
因为GraphRAG的查询整体流程是:首先从构建好的parquent文件中索引出社区报告、节点、边、以及原文分块,然后将这些上下文内容传给大模型,让它生成答案。 那么,我们可以不要生成答案的部分,只要graphrag检索出 的上下文。
(2)将上下文通过api方式传递给dify
在第一步生成的上下文,用fastapi写一个接口,在dify里创建工作流,去使用http请求节点去返回上下文,再走大模型回答步骤。
3、尝试
(1)正常执行查询步骤,从中截断上下文并且输出
a.查询步骤
正常的查询命令是这样的,生成的答案也是只有大模型返回的答案,所以需要去源码里找到输出答案的部分,让它把上下文也输出。
python -m graphrag.query --root /to/your/path --method local "your question"
b.输出上下文
在下面的py文件中添加一行,输出上下文,并且手动添加分隔符
# graphrag-local-ollama\graphrag\query\cli.py search_engine = get_local_search_engine( config, reports=read_indexer_reports( final_community_reports, final_nodes, community_level ), text_units=read_indexer_text_units(final_text_units), entities=entities, relationships=read_indexer_relationships(final_relationships), covariates={ "claims" : covariates}, description_embedding_store=description_embedding_store, response_type=response_type, ) result = search_engine.search(query=query) #添加上下文输出,并且手动添加分隔符,方便后期分割 reporter.success( "---datasets---" +result.context_text + "---END---" ) reporter.success( f"Local Search Response: {result.response}" ) return result.response
c.将执行的查询命令封装成api,并且截取特定部分输出
try : # 执行命令并捕获输出 result = subprocess.run(command, capture_output= True , text= True , encoding= "utf-8" ,check= True ) # 检查输出是否为 None if result.stdout is None : print( "No output from the command." ) else : # 使用分隔符截取需要的内容 start_delimiter = "---datasets---" end_delimiter = "---END---" output = result.stdout.strip() # 查找分隔符的位置 start_index = output.find(start_delimiter) end_index = output.find(end_delimiter) if start_index != -1 and end_index != -1 : # 截取分隔符之间的内容 output = output[start_index + len(start_delimiter):end_index].strip() else : output = "Delimiter not found in the output." return { "output" : output}
(2)添加LocalSearch API模块
方法1的话,我们会发现,他还是要走大模型那一步,只是最后截取了需要的部分,响应时间还是受影响,没有达到我们的最终目的。 因为这个项目的api模块作者为了轻量化全部删除,所以我们单独写一个LocalSearchAPI模块即可。
a. 核心思想
resopnse\_type添加一个search\_reponse选项,如果命令走了这个选项,那么大模型的回答设置为空(不走生成回复流程),直接返回上下文。
b. 修改search.py
修改 `graphrag/query/structured_search/local_search/search.py`
async def asearch(
self,
query: str,
conversation_history: ConversationHistory | None = None,
**kwargs,
) -> SearchResult: """Build local search context that fits a single context window and generate answer for the user query.""" start_time = time.time() search_prompt = "" context_text, context_records = self.context_builder.build_context( query=query, conversation_history=conversation_history, **kwargs, **self.context_builder_params, ) log.info( "GENERATE ANSWER: %s. QUERY: %s" , start_time, query) try : if self.response_type == "search_prompt" : # 如果 response_type 是 "search_prompt",直接返回上下文内容 return SearchResult( response= "" , context_data=context_records, context_text=context_text, completion_time=time.time() - start_time, llm_calls= 0 , prompt_tokens= 0 , ) else : search_prompt = self.system_prompt.format( context_data=context_text, response_type=self.response_type) search_messages = [ { "role" : "system" , "content" : search_prompt }, { "role" : "user" , "content" : query }, ] if self.response_type == "search_prompt" : return SearchResult( response=search_prompt, context_data=context_records, context_text=context_text, completion_time=time.time() - start_time, llm_calls= 1 , prompt_tokens=num_tokens(search_prompt, self.token_encoder), ) response = await self.llm.agenerate( messages=search_messages, streaming= True , callbacks=self.callbacks, **self.llm_params, ) return SearchResult( response=response, context_data=context_records, context_text=context_text, completion_time=time.time() - start_time, llm_calls= 1 , prompt_tokens=num_tokens(search_prompt, self.token_encoder), )
c. 添加LocalSearchAPI
`localsearchapi.py` 参考最新GraphRAG版本的api模块修改,作为一个平替,核心代码:
def __init__(self, data_dir: Union[str, None], root_dir: Union[str, None]): self.data_dir, self.root_dir, self.config = self._configure_paths_and_settings( data_dir, root_dir ) self.description_embedding_store = self._get_embedding_description_store() self.agent = self.search_agent( community_level= 2 , response_type= "search_prompt" ) def run_search(self, query: str): result = self.agent.search(query=query) if self.agent.response_type == "search_prompt" : try : # 尝试直接打印 print(result.context_text) print(type(result.context_text)) except UnicodeEncodeError: # 如果直接打印失败,显式处理编码 print(result.context_text.encode( "utf-8" , errors= "replace" ).decode( "gbk" , errors= "replace" )) return result.context_text else : print(result.response) return result.response
d. 封装为api
from fastapi import FastAPI, Query, HTTPException from typing import Optional import os from pathlib import Path # 导入你的 LocalSearchEngine 类 from localsearchapi import LocalSearchEngine # 替换为你的模块路径 app = FastAPI() # 初始化 LocalSearchEngine 实例 local_search_engine = LocalSearchEngine(data_dir= None , root_dir=os.path.dirname(__file__)) @app.get("/search") async def search(query: Optional[str] = Query(None, description="搜索查询")): if not query: raise HTTPException(status_code= 400 , detail= "Query parameter is required" ) result = local_search_engine.run_search(query=query) return { "response" : result} # 启动 FastAPI 应用 if __name__ == "__main__" : import uvicorn uvicorn.run(app, host= "0.0.0.0" , port= 8000 )
4、接入Dify
工作室-创建空白应用-选择工作流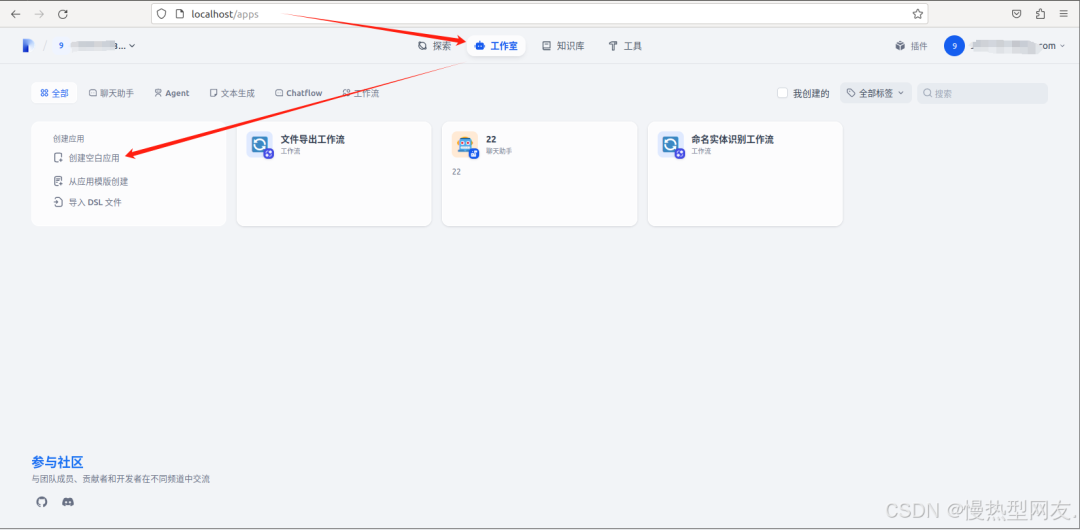
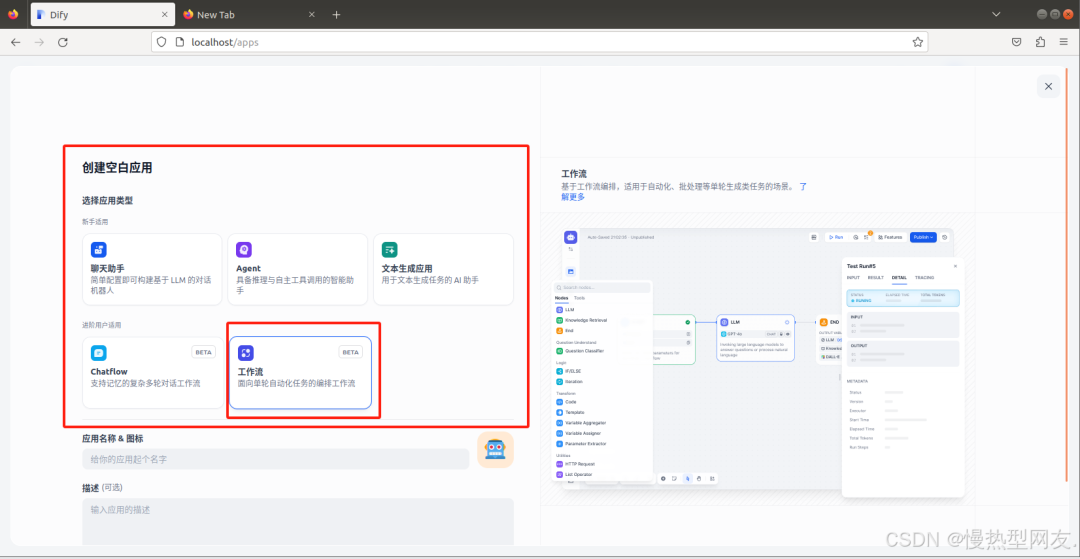
在这里创建了四个节点,开始、结束、HTTP请求节点以及代码执行节点
(1)各节点设计
开始、结束节点就不介绍了,简单介绍中间两个节点
a. HTTP请求节点
此节点的作用主要是调用外部api获取graphrag查询的上下文。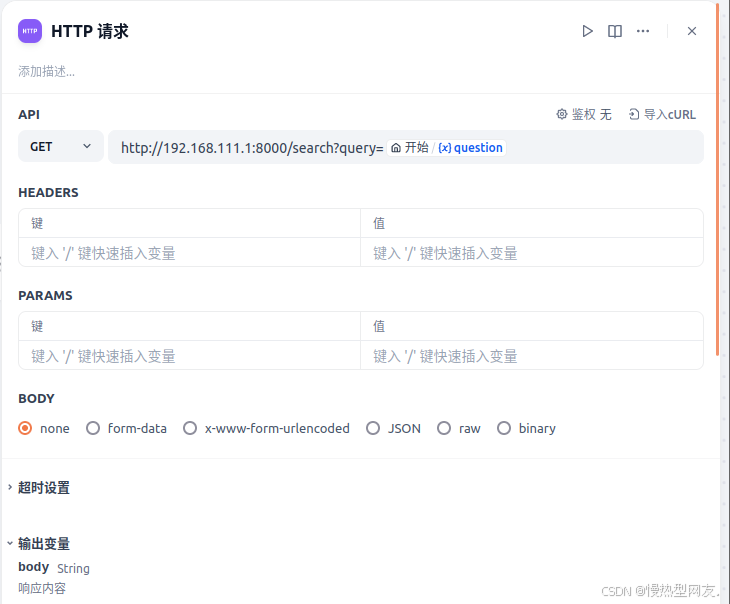
b. 代码节点
主要是获取json信息,提取出response的内容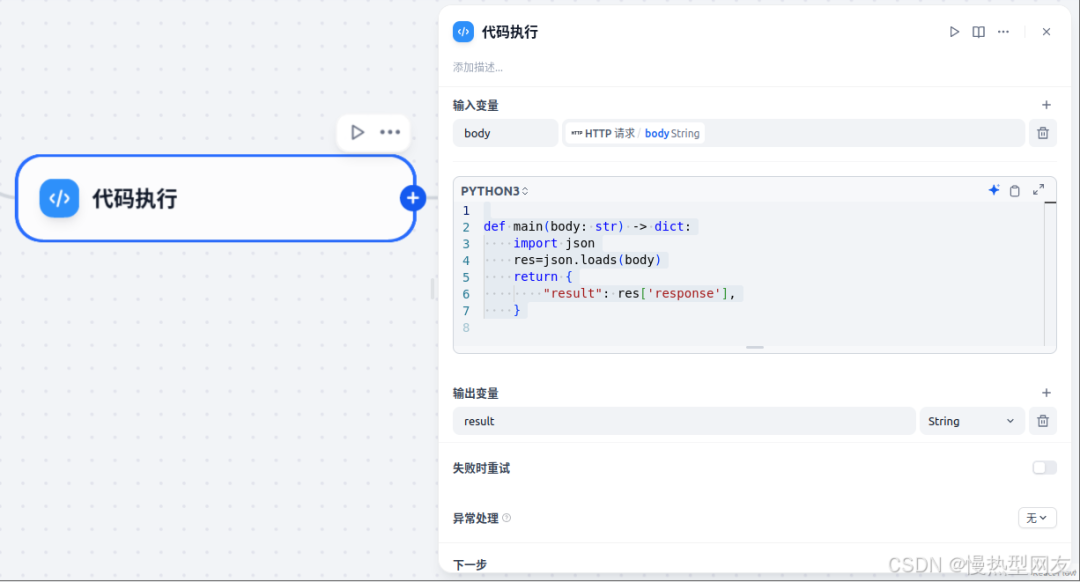
5、结果
运行
在Dify运行工作流,工作流会自动执行,最后生成结果如下: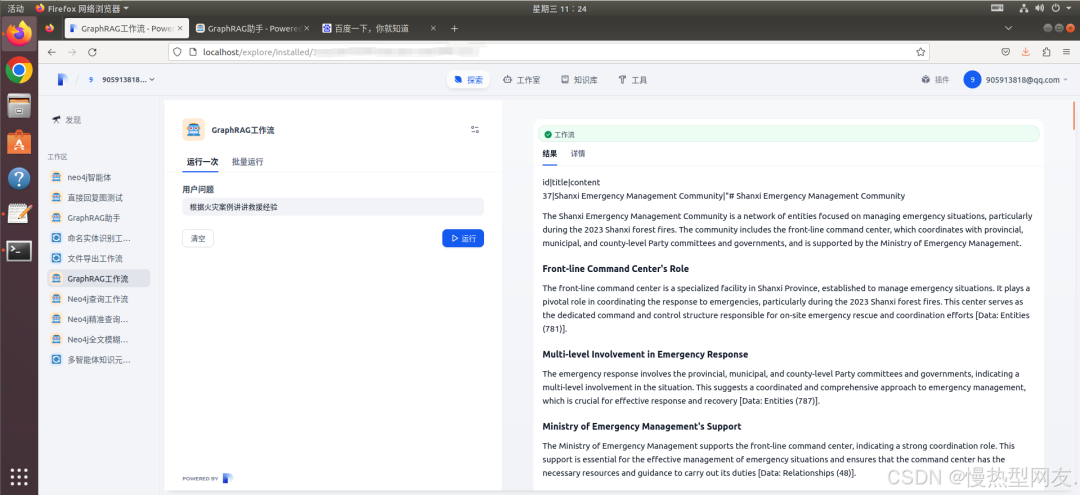
至此,问题解决
目前是可以解决我的需求,那么这只是一个初步探索,目前发现传回来的上下文很长,可能会超出大模型的上下文窗口,预计后期会将上下文根据模块再拆分,交给多智能体去处理,优化结果。 本篇博客也是分享一个思路以及对应的实践,可以根据这个结果继续拓展,比如智能体接入工作流;后面自然会有更好的解决办法,我也希望和大家交流心得,共同进步,欢迎随时与我联系。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础第二不要求准备高配置的电脑第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)