考虑VAE来实现不同条件下的文本生成
题目 Pre-train and Plug-in: Flexible Conditional Text Generation with Variational Auto-Encoders作者: 这是一篇由阿里,武汉大学,芝加哥大学,美国亚马逊联合出品**前言:**应该是真大佬之间的合作,哎十分羡慕啊。言归正传,我之前基本一直没怎么接触VAE,最多只是看过一些博客介绍,这篇文章应该算是我对VAE的一
题目 Pre-train and Plug-in: Flexible Conditional Text Generation with Variational Auto-Encoders
作者: 这是一篇由阿里,武汉大学,芝加哥大学,美国亚马逊联合出品
**前言:**应该是真大佬之间的合作,哎十分羡慕啊。言归正传,我之前基本一直没怎么接触VAE,最多只是看过一些博客介绍,这篇文章应该算是我对VAE的一次全面了解,初始感觉,VAE强啊,本文做的是有条件的文本生成任务,基于VAE去做文本隐含分布映射,然后通过给出的条件能够实现针对文本隐含分布的映射,从而完成文本生成,不得不说,这个东西很酷,在实现工业界应该很有意义。
**摘要:**条件文本生成作为文本生成领域的重要课题。当前的条件文本模型不能在不完全训练的条件下去做到添加新的限制。本论文提出的PPVAE技术能够做到在只对轻权重网络做修改,然后即可实现添加新条件。当新的条件出现时,只需要train轻量级网络作为附加部分放入网络即可。
任务形式:
train形式:
- 利用大量无标签文本做VAE训练,获取潜在的语义空间分布
- 给定有标签(条件)的少量有监督文本做P LUGIN VAE训练,帮助确定VAE的编码和译码形式
predict:
- 将数据映射到VAE生成的指定语义空间分布后,然后短文本。
前述VAE: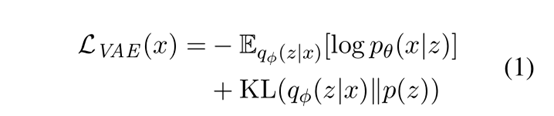
其实作者默认大量的无标签文本库中应该包含了所有条件的数据,基于这个假设做的实验。
主体框架: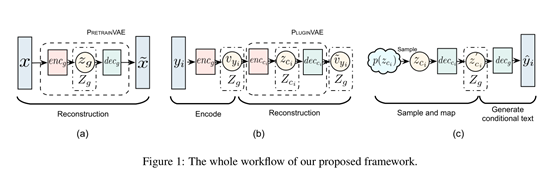
PretrainVAE: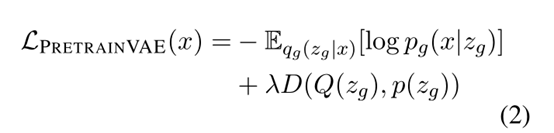
编码器:单层的Bi_GRU+2层全连接
译码器:transformers
PluginVAE: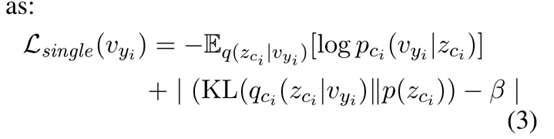
论文阐述:超参很重要,后面给出说上面超参几乎确定了准确率和多样性的平衡点。
编码器:2层全连接
译码器:2层全连接
trick:
这个可以理解为专门去设计了一些错误样本然后放入数据集中,让PluginVAE模型进行训练,这个还是很牛的,后面实验体现出来了。
数据集:
作者选取了两个数据集Yelp和News Titles数据集,然后分别考虑三个任务,分别实情感分类,长度控制,和主题限定。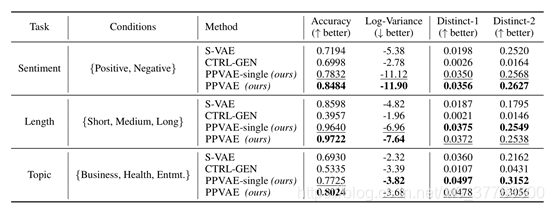

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)