基于Python+大数据的王者荣耀战队的数据分析系统设计与实现(精品源码+论文+答辩PPT)
摘要: 本文设计并实现了一款基于Python与MySQL的王者荣耀战队数据分析系统,涵盖大数据处理、爬虫技术(Scrapy)、数据可视化等功能。系统采用前后端分离架构(Vue+Django),支持用户登录、比赛信息管理、数据爬取与智能分析,助力电竞战队优化战术决策。开发过程包括功能设计、数据库建模、代码实现及测试,提供论文辅导、降重等一站式毕设服务。系统通过Hadoop处理海量比赛数据,结合机器学
技术范围:大数据、物联网、SpringBoot、Vue、SSM、HLMT、小程序、PHP、Nodejs、Python、爬虫、数据可视化、安卓App、机器学习等设计与开发。
主要内容:功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
精彩专栏推荐订阅:见下方专栏👇🏻
【2026计算机毕业设计选题】10套易过的精品毕设项目分享-CSDN博客
2025-2026年 最新计算机毕业设计 本科 选题大全 汇总版-CSDN博客
🍅文末获取源码联系🍅
在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
一、开发背景
科学技术日新月异,人们的生活都发生了翻天覆地的变化,王者荣耀战队的数据分析当然也不例外。过去的信息管理都使用传统的方式实行,既花费了时间,又浪费了精力。在信息如此发达的今天,我们可以通过网络这个媒介,快速的查找自己想要的信息,更加全方面的了解自己的网站信息。而且人们也可以突破传统信息管理的僵硬模式,制定属于自己的个性化的管理方案。基于现代人们的需求,设计并开发了一款王者荣耀战队的数据分析系统。
本篇文章使用Python与MYSQL技术搭建了一个王者荣耀战队的数据分析系统。对用户提出的功能进行合理分析,然后搭建开发平台以及配置计算机软硬件;通过对数据流图以及系统结构的设计,创建相应的数据库;进行详细的设计,实现主要功能。最后测试网站,并分析测试结果,完善系统,得出系统使用说明书,方便日后的维护以及更新。
作为用户,本系统可以在线搜索,查看并且网站信息;也可以在线互动交流。作为系统的管理员,可以及时的更新数据,也可以随时随地的处理网站信息。便捷的操作界面以及全新的功能会让人们耳目一新。
王者荣耀作为一款流行的多人在线战术竞技游戏,在全球范围内拥有庞大的玩家群体。随着电子竞技的兴起,王者荣耀不仅成为了休闲娱乐的手段,更是许多专业电竞战队展示实力和争夺荣誉的平台。随之而来的是对于游戏内战队管理和数据分析需求的显著增长。一个高效的战队数据分析系统能够为战队提供强大的支持,帮助教练员和队员深入理解每场比赛的表现,优化战略布局,提升团队协作效率,从而在激烈的竞技中取得优势。然而,目前市面上关于王者荣耀战队的数据分析多集中在基础的数据记录与展示,缺乏深入的数据挖掘和分析功能,这限制了战队性能的进一步提升。因此,开发一个具有先进分析功能的数据分析系统显得尤为重要,它不仅能为战队带来量身定做的数据解决方案,同时也推动了整个王者荣耀电竞生态的技术进步。
深入研究并开发王者荣耀战队的数据分析系统,对于提升电竞战队的竞争力有着不可忽视的重要性。一个功能全面的数据分析系统能够准确评估队员的个人技术、战术执行、团队配合等多方面能力,使教练团队能够科学地制定训练计划和比赛策略。其次,通过数据的深度挖掘可以发现非直观的游戏规律和对手特点,为战队提供战略性的决策支持。再者,随着大数据和人工智能技术的发展,数据分析系统的准确性和智能水平有望进一步提升,这将极大地推动电竞行业的数据化和智能化进程。最后,该系统的开发和应用将有助于促进电竞教育的发展,为培养专业的电竞人才提供实战平台和科学工具。从这些角度来看,构建和完善王者荣耀战队的数据分析系统不仅是对特定游戏领域的技术创新,也是对整个电子竞技生态系统的重要贡献。
在此基础上,进一步探索数据分析系统在提升战队协作效率、制定个性化训练方案、增进粉丝互动体验等方面的应用潜能,无疑将推动传统游戏领域向更加专业化、数据驱动型的电竞行业转变。因此,本研究旨在围绕王者荣耀战队的数据分析系统进行深入探讨,以期为电竞战队提供科技赋能,同时为整个电竞生态注入新的活力。
二.技术环境
2.2 PYTHON技术概述
Python技术是一种广泛使用的计算机编程语言,具有跨平台、面向对象、安全性高等特点。Python技术的核心是Python虚拟机(JVM),它使得Python程序可以在任何支持JVM的平台上运行,从而实现了真正的跨平台。Python技术的面向对象特性使得程序员可以更加方便地编写和维护大型软件项目,提高了开发效率。Python技术还具有丰富的类库和API,可以帮助开发者快速实现各种功能。在企业级应用开发中得到了广泛应用,如Web应用、移动应用、大数据处理等。Python技术还广泛应用于云计算、物联网等领域,为这些领域的发展提供了强大的技术支持。Python技术凭借其优秀的性能和广泛的应用前景,成为了当今软件开发领域不可或缺的一部分。
2.6 Hadoop介绍
Hadoop是一个由Apache基金会维护的开源框架,它允许分布式处理大数据集在计算集群中的大规模数据。它的核心设计哲学是将应用程序带到数据所在的位置,而不是将大量数据传输到应用程序所在的服务器。Hadoop主要由两个组件组成:Hadoop Distributed File System(HDFS)和MapReduce。HDFS提供了高度可靠、高吞吐量的数据存储解决方案,而MapReduce则是一个编程模型,用于处理这些大量数据。Hadoop的优势在于其可扩展性、经济性和灵活性,使其成为大数据分析的首选工具。
2.7 Scrapy介绍
Scrapy是一个开源且强大的Python爬虫框架,用于快速高效地从网站和互联网上提取结构化数据。它可用于广泛的目的,从数据挖掘到监控和自动化测试。Scrapy的核心是其引擎,它负责调度、下载、解析和处理请求以及项目管道的清理和持久化。Scrapy能够处理登录、cookies、session、用户代理切换等一系列复杂任务。其优势在于可扩展性、中间件支持、内建的下载器和爬虫管理等。通过使用Twisted异步网络库和丰富的API,Scrapy可以高效地处理并发请求,并且具有很好的性能表现。
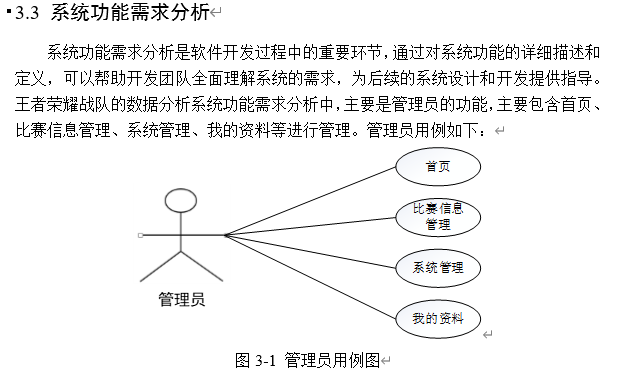
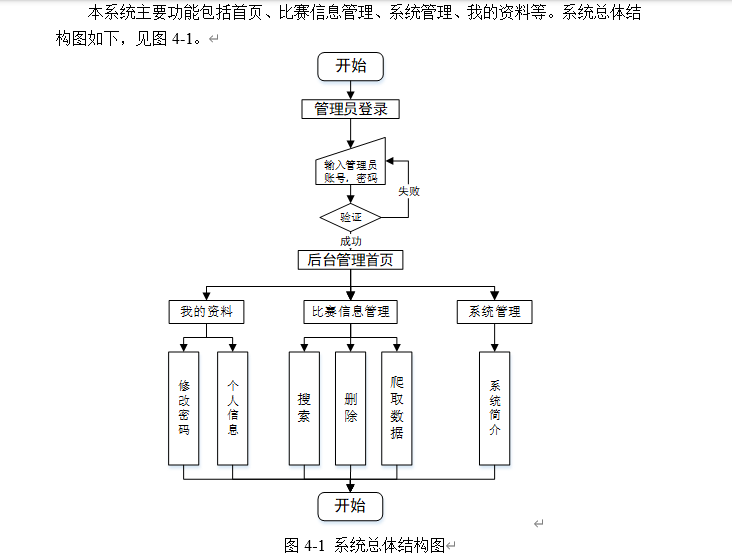
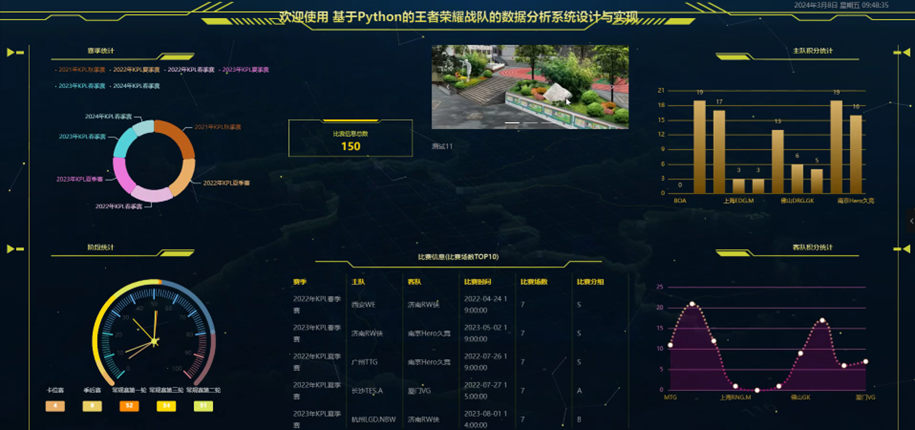
系统实现效果
5.1系统登录实现
在登录流程中,用户首先在Vue前端界面输入用户名和密码。这些信息通过HTTP请求发送到Python后端。后端接收请求,通过与MySQL数据库交互验证用户凭证。如果认证成功,后端会返回给前端,允许用户访问系统。这个过程涵盖了从用户输入到系统验证和响应的全过程。系统登录页面如图5-1所示。
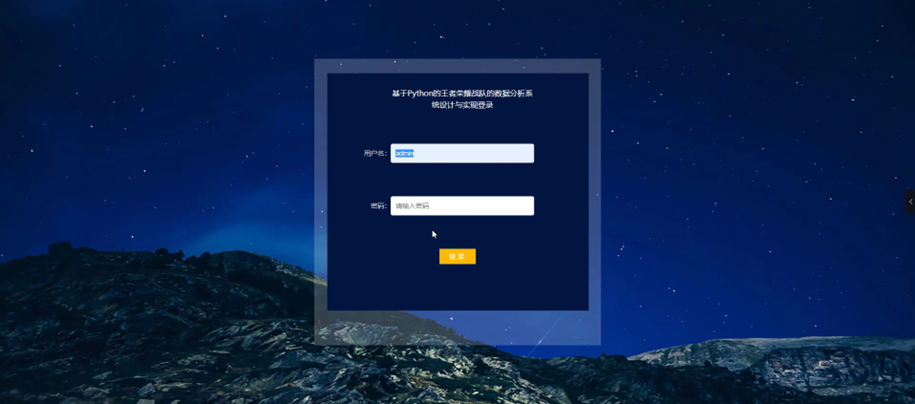
图5-1 系统登录界面
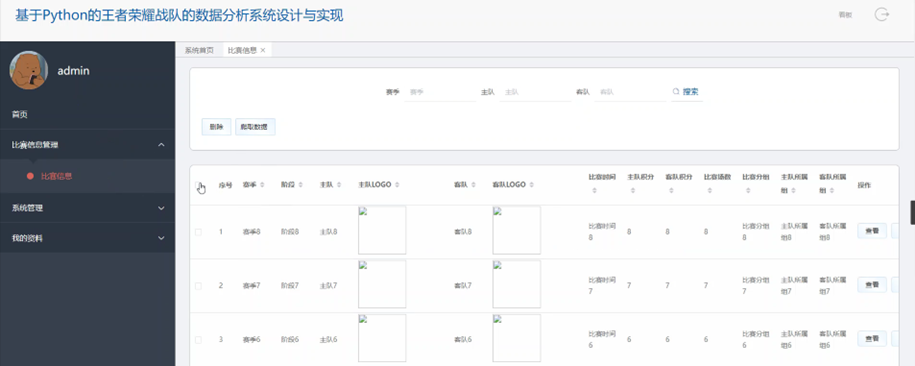
比赛信息管理功能实现是在Django后端部分,您需要创建一个新的应用,然后在该应用下创建一个模型(models.py)来定义比赛信息的数据结构,使用Django的ORM来处理与MySQL数据库的交互,包括比赛信息的搜索、删除或爬取数据等操作。接着,在views.py中编写视图逻辑来处理前端请求,使用Django的URL路由(urls.py)将请求映射到相应的视图函数。对于数据的验证和序列化,可以使用Django的表单或序列化器来实现。在前端Vue.js部分,将创建相应的Vue组件,在这些组件中使用axios或其他HTTP库与Django后端的API进行交互,实现比赛信息的查看、编辑或删除等功能。状态管理可以通过Vuex来维护,比如在store目录下定义比赛信息模块的状态、突变、动作和获取器。如图5-3所示:
文档部分参考
精彩专栏推荐订阅:见下方专栏👇🏻
【2026计算机毕业设计选题】10套易过的精品毕设项目分享-CSDN博客
源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)