PyTorch 入坑六 数据处理模块Dataloader、Dataset、Transforms
深度学习中的数据处理概述深度学习三要素:数据、算力和算法在工程实践中,数据的重要性越来越引起人们的关注。在数据科学界流传着一种说法,“数据决定了模型的上限,算法决定了模型的下限”,因此在这个“说法”中,明确的表明了,只有好的数据才能够有好的模型,数据才是决定了模型的关键因素。数据很重要简单来说,就是找到好的数据,拿给模型“吃”。但是怎么找到“好”的数据,什么样才算是“好”的数据,给模型吃了后模型性
深度学习中的数据处理概述
深度学习三要素:数据、算力和算法
在工程实践中,数据的重要性越来越引起人们的关注。在数据科学界流传着一种说法,“数据决定了模型的上限,算法决定了模型的下限”,因此在这个“说法”中,明确的表明了,只有好的数据才能够有好的模型,数据才是决定了模型的关键因素。
数据很重要
简单来说,就是找到好的数据,拿给模型“吃”。
但是,什么样才算是“好”的数据,怎么找到“好”的数据,给模型吃了后模型性能有没有变化等等问题是一个非常庞大的课题,本文并不深入探讨,首先从特征工程的角度抛出一张图,另外总结一下深度学习中最常用的几个数据处理过程。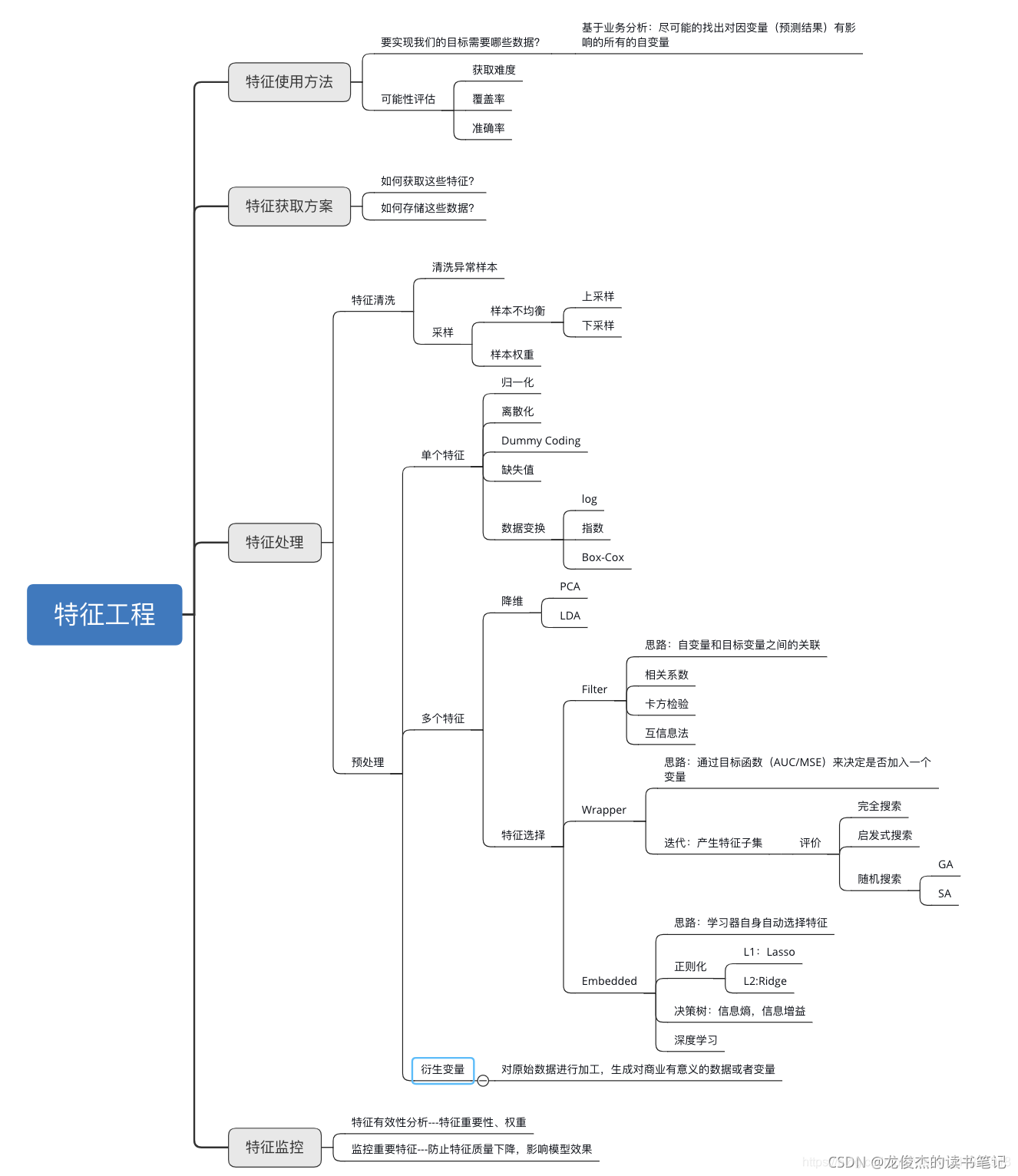
ML/DL的数据处理基本步骤
收集
在进行实验之前,需要收集数据,数据包括原始样本和标签。标签信息一般有收集公开数据集数据、人工标注、自动化/半自动化标注、仿真模拟平台生成等几种方法。
划分
有了原始数据之后,需要对数据集进行划分,把数据集划分为训练集、验证集和测试集
- 训练集:训练模型
- 验证集:验证集用于验证模型是否过拟合,通过比较算法在验证集的性能挑选模型的超参数(学习率、优化算法、网络结构等)
- 测试集: 测试模型的性能,测试模型的泛化能力(往往测试话指标由第三方出,算法同学不接触测试数据和标签)
数据读取
pytorch中数据读取的核心是DataLoader。
DataLoader还会细分为两个子模块,Sampler和DataSet;Sample的功能是生成索引,也就是样本的序号;Dataset是根据索引去读取图片以及对应的标签
数据预处理
比如说数据的中心化,标准化,旋转或者翻转等
pytorch中数据预处理是通过transforms进行处理的
PyTorch中的数据读取模块
torch.utils.data.DataLoader
DataLoader(dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_works=0,
clollate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None)
- 功能:构建可迭代的数据装载器;
- dataset:Dataset类,决定数据从哪里读取及如何读取;
- batchsize:批大小;
- num_works:是否多进程读取数据;
- shuffle:每个epoch是否乱序;
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据;
torch.utils.data.Dataset
class Dataset(object):
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other)
return ConcatDataset([self,other])
- Dataset是用来定义数据从哪里读取,以及如何读取的问题;
- 功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__();
- 函数__getitem__() 作用:接收一个索引,返回一个样本
一个分类任务的数据读取例子
详情见
这里是引用分类任务DataLoader例子
核心代码:
# 构建MyDataset实例,MyDataset必须是用户自己构建的
train_data = RMBDataset(data_dir=train_dir, transform=train_transform) # data_dir是数据的路径,transform是数据预处理
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform) # 一个用于训练,一个用于验证
#构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) # shuffle=True,每一个epoch中样本都是乱序的
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
其中,DataLoader会传入一个参数Dataset,也就是前面构建好的RMBDataset;第二个参数是batch_size,shuffle=True,它的作用是每一个epoch中样本都是乱序的
代码中跟踪RMBDataset构建了两个Dataset,一个用于训练,一个用于验证。
核心为重写了函数
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
数据预处理模块Transforms
torchvision
是pytorch的计算机视觉工具包
主要有三个模块:
- torchvision.transforms,常用的图像预处理方法,在transforms中提供了一系列的图像预处理方法,例如数据的标准化,中心化,旋转,翻转等等;
- torchvision.datasets,定义了一系列常用的公开数据集的datasets,比如常用的MNIST,CIFAR-10,ImageNet等等;
- torchvision.model,提供大量常用的预训练模型,例如AlexNet,VGG,ResNet,GoogLeNet等等;
torchvision.transforms
常用的图像预处理方法:
- 数据中心化
- 数据标准化
- 缩放
- 裁剪
- 旋转
- 翻转
- 填充
- 噪声添加
- 灰度变换
- 线性变换
- 仿射变换
- 亮度、饱和度及对比度变换
transforms.Compose的功能是将一系列的transforms方法进行有序的组合包装,在具体实现的时候,会依次按顺序对图像进行操作
使用:
#设置数据标准化的均值和标准差
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)), #Resize,将图像缩放到32*32的大小
transforms.RandomCrop(32, padding=4), #RandomCrop,对数据进行随机的裁剪
transforms.ToTensor(), #ToTensor,将图片转成张量的形式同时会进行归一化操作,把像素值的区间从0-255归一化到0-1
transforms.Normalize(norm_mean, norm_std), #标准化操作,将数据的均值变为0,标准差变为1
]) # Resize的功能是缩放,RandomCrop的功能是裁剪,ToTensor的功能是把图片变为张量
(1) transforms.Normalize
- 功能:逐channel的对图像进行标准化,即数据的均值变为0,标准差变为1。逐通道的意思是,以GRB图像为例,计算训练集的所有图片的R通道之和,并除以 (图像N x W x H)
- 标准化的计算公式为 o u t p u t = ( i n p u t − m e a n ) / s t d output = (input - mean) /stdoutput=(input−mean)/std
- mean:各通道的均值
- std:各通道的标准差
- inplace:是否原位操作
对数据进行标准化之后可以加快模型的收敛
为什么会呢,这是一个比较大的话题,后续有时间会开一个专栏尝试解答该问题。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)