7、Pandas笔记5-数据处理
在 Pandas 中,可以使用 `fillna()` 方法来对 DataFrame 中的空值进行填充。`fillna()` 函数可以用指定的值、中位数或其他可用数据来填充 DataFrame 中的空值。以下是使用 `fillna()` 函数处理 NaN 缺失值的基本示例:```python# 创建示例 DataFrame# 使用均值填充缺失值```调用 `fillna()` 函数时,我们可以使用不
六、缺失值处理
1、缺失值处理
- 缺失值统计
-
- isnull
- notnull
- 删除缺失值
-
- dropna
- 填充缺失值
-
- fillna
import pandas as pd
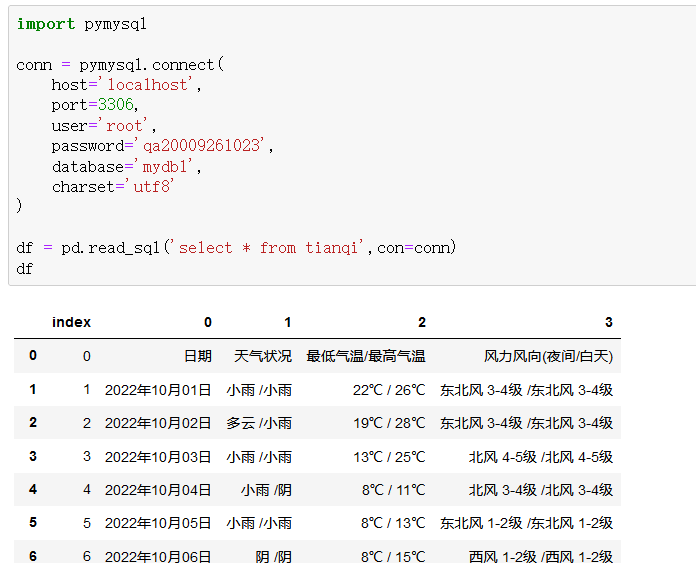
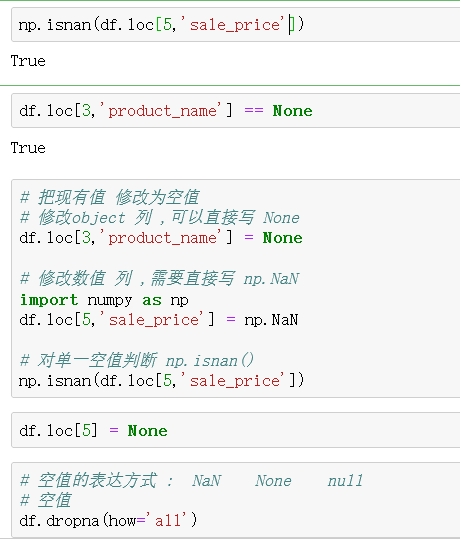
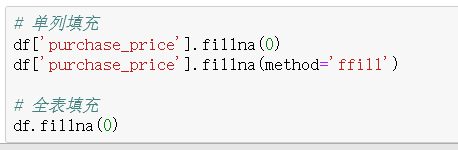
2、缺失值分析
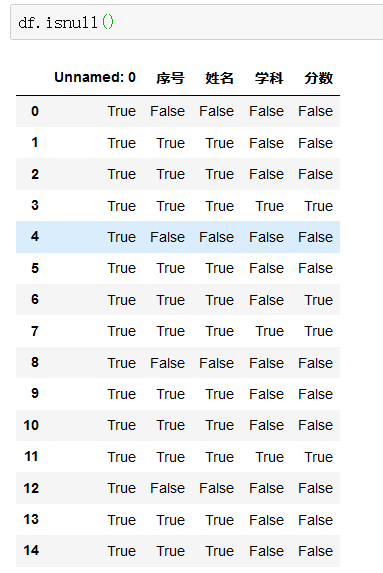
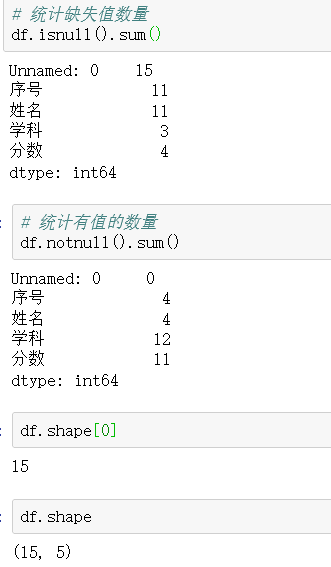
df.shape返回行数,列数
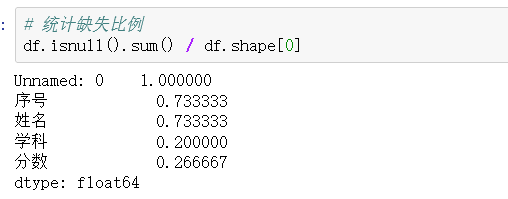
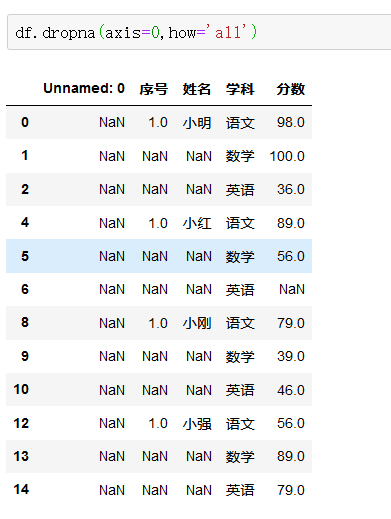
3、缺失值删除
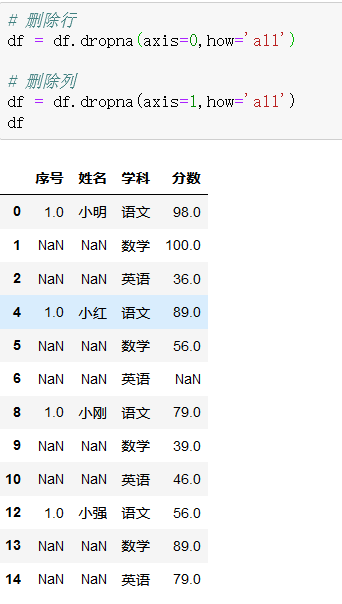
4、缺失值填补
1、总结
在 Pandas 中,可以使用 `fillna()` 方法来对 DataFrame 中的空值进行填充。 `fillna()` 函数可以用指定的值、中位数或其他可用数据来填充 DataFrame 中的空值。
以下是使用 `fillna()` 函数处理 NaN 缺失值的基本示例:
```python
import pandas as pd
import numpy as np
# 创建示例 DataFrame
data = np.array([[1, 2, np.nan, 4], [5, np.nan, 7, 8], [9, 10, 11, np.nan]])
df = pd.DataFrame(data, columns=['A', 'B', 'C', 'D'])
# 使用均值填充缺失值
df.fillna(df.mean(), inplace=True)
```
调用 `fillna()` 函数时,我们可以使用不同的填充值。`df.mean()` 返回了 DataFrame 中每列的均值,将这个均值填充到 DataFrame 的 NaN 缺失值位置。由于我们使用了 `inplace=True` 参数,因此这个操作会直接修改原始 DataFrame,而不是返回一个新的 DataFrame。
此外,我们还可以将 DataFrame 中的 NaN 缺失值填充为某个特定的值,比如:
```python
df.fillna(0, inplace=True)
```
这个代码将所有缺失值替换为 0。
另外,我们还可以使用其他方法来填充缺失值,比如使用前一个有效值向前填充,或者使用后一个有效值向后填充,示例如下:
```python
# 向前填充
df.fillna(method='ffill', inplace=True)
# 向后填充
df.fillna(method='bfill', inplace=True)
```
需要注意的是,填充缺失值的方法取决于数据的类型和本身的特点,不同的策略需要根据实际情况进行选择。
总的来说,`fillna()` 函数是 Pandas 中十分常用的一个方法,可以对 DataFrame 的缺失值进行填充,从而使数据更加完整。
2、fillna具体参数详解
Pandas 的 fillna 函数是缺失值处理中非常重要的函数,它可以用不同的方法来填充 DataFrame 中的缺失值。以下是 fillna 函数的主要参数及其用法:
- value:指定用来填充缺失值的标量值或以字典形式指定需要填充的列名和对应的值。示例如下:
```python
# 将 DataFrame 中的所有缺失值替换为 0
df.fillna(0, inplace=True)
# 将A列中的缺失值替换为 -1,将B列中的缺失值替换为 0
df.fillna({'A': -1, 'B': 0}, inplace=True)
```
- method:指定需要使用的填充方式,常见的有向前填充、向后填充和插值等。示例如下:
```python
# 向前填充
df.fillna(method='ffill', inplace=True)
# 向后填充
df.fillna(method='bfill', inplace=True)
# 插值填充
df.interpolate(method='linear', inplace=True)
```
- limit:此参数只有在 method 为向前/向后填充时有效,用来限制填充的连续 NaN 值的最大数量。示例如下:
```python
# 填充两个连续的 NaN 值
df.fillna(method='ffill', limit=2, inplace=True)
```
- axis:指定是按行操作还是按列操作,默认为按行操作,即向下填充。示例如下:
```python
# 按列填充
df.fillna(method='ffill', axis=1, inplace=True)
```
- inplace:指定是否直接修改原 DataFrame,默认为 False,即返回一个新的 DataFrame。如果设为 True,则在原 DataFrame 上进行修改。示例如下:
```python
# 直接在原 DataFrame 上进行修改
df.fillna(method='ffill', inplace=True)
```
需要注意的是,fillna 方法的不同参数之间是可以组合使用的,通过设置不同的参数,可以实现对不同类型数据的缺失值填充。同时,填充方法也会对原始数据的分布和分析结果产生一定的影响,需要根据实际情况选择合适的方法。
3、笔记
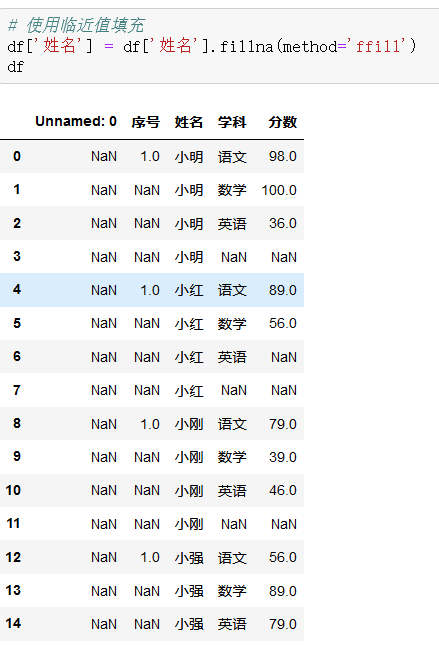
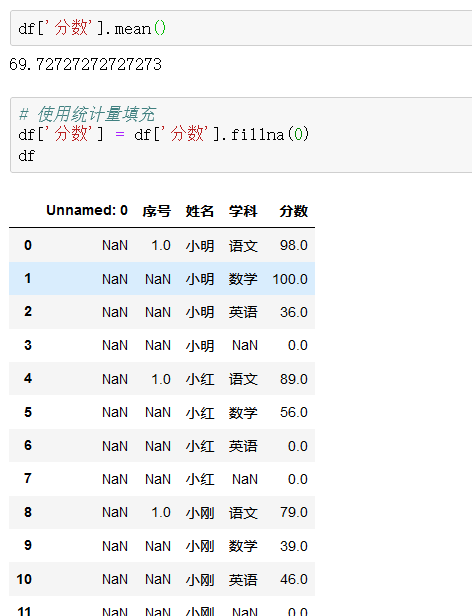
5、获取列名

6、删除列
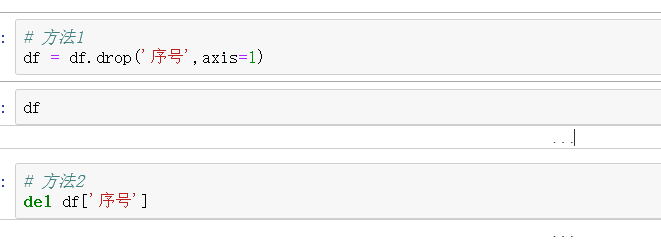
7、修改列名

pandas将一列的大小写统一
8、修改列顺序

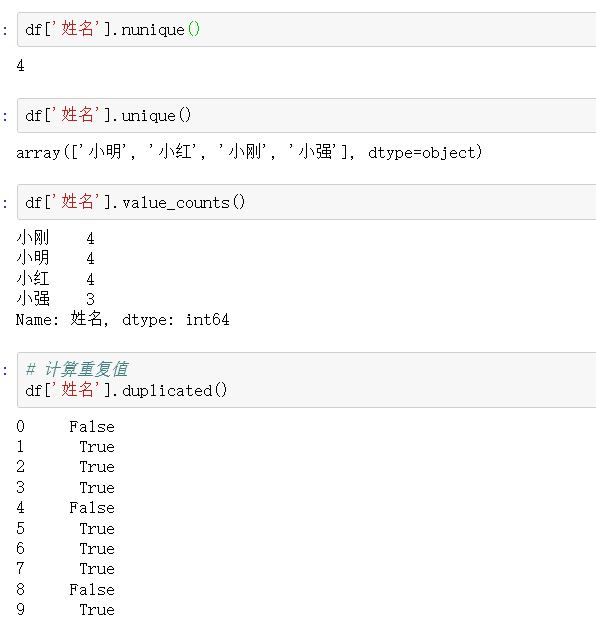
9、重复值处理
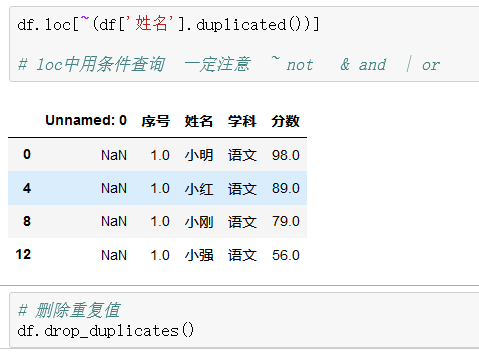
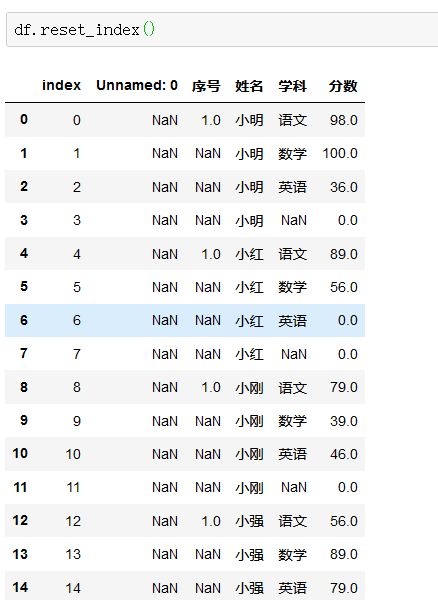
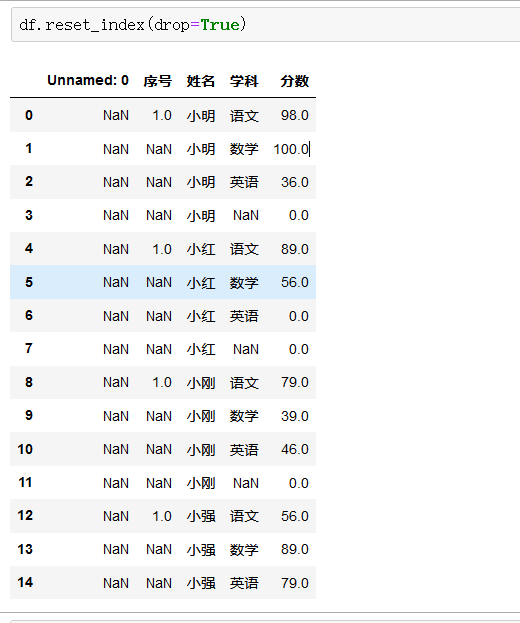
重设索引
删除重复行
在 Pandas 中,可以使用 `drop_duplicates()` 方法删除 DataFrame 中的重复行。该方法默认会判断 DataFrame 中的每一行是否重复,如果是,则会将所有重复的行删除,只保留其中的一个。以下是使用 `drop_duplicates()` 方法删除 DataFrame 中重复行的示例:
```python
import pandas as pd
# 创建示例 DataFrame
data = {'A': [1, 2, 3, 3], 'B': [4, 5, 6, 6], 'C': [7, 8, 9, 9]}
df = pd.DataFrame(data)
# 删除重复的行
df = df.drop_duplicates()
```
在这个代码中,我们首先创建了一个含有重复行的示例 DataFrame,然后使用 `drop_duplicates()` 方法删除了其中的重复行,最后得到了一个不含有重复行的 DataFrame。
需要注意的是,`drop_duplicates()` 方法默认按照所有列进行去重,如果需要只按照某几列进行去重,可以使用 `subset` 参数指定这些列的名称,示例如下:
```python
# 按照 A、B 两列进行去重
df = df.drop_duplicates(subset=['A', 'B'])
```
在指定了 `subset` 参数之后,`drop_duplicates()` 方法只会对指定的列进行去重。
此外,`drop_duplicates()` 方法还有其他参数:
- keep:用于指定保留重复行中的哪一个。默认值是 'first',表示保留第一个出现的行;而 'last' 则表示保留最后一个出现的行。
- inplace:是否在原 DataFrame 上进行操作。默认为 False,表示返回一个新的 DataFrame;如果设为 True,则会直接在原 DataFrame 上进行修改。
总的来说,`drop_duplicates()` 方法是 Pandas 中非常常用的一个方法,可以帮助我们快速删除 DataFrame 中的重复数据行。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)