MKR:协同过滤算法效果不佳,知识图谱来帮忙
协同过滤算法效果不佳怎么办?知识图谱来帮忙啦!Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(WWW2019)Paper:https://arxiv.org/pdf/1901.08907.pdf作者:一元,炼丹笔记小编背景协同过滤在真实推荐场景中经常会受到稀疏性和冷启动问题的影响,为了缓解此类问题,我们
协同过滤算法效果不佳怎么办?知识图谱来帮忙啦!
Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(WWW2019)
Paper:https://arxiv.org/pdf/1901.08907.pdf
作者:一元,炼丹笔记小编
背景
协同过滤在真实推荐场景中经常会受到稀疏性和冷启动问题的影响,为了缓解此类问题,我们使用附带信息(side infomation)来处理。本文,作者使用知识图谱作为附带信息并采用多任务学习的方式来处理该问题。
问题定义模型介绍
1. 问题形式
1.1 符号定义 & 案例解释
我们有一个MMM个用户的集合,U={u1,u2,…,uM}U=\left\{u_{1}, u_{2}, \ldots, u_{M}\right\}U={u1,u2,…,uM},以及NNN个商品的集合, V={v1,v2,…,vN}V=\left\{v_{1}, v_{2}, \ldots, v_{N}\right\}V={v1,v2,…,vN},以及用户和商品的交互集合,Y∈RM∗NY \in R^{M * N}Y∈RM∗N。如果用户uuu和商品vvv有交叉,例如点击,观看,购买等,那么yuv=1y_{u v}=1yuv=1,反之则为0。
除此之外,我们还有知识图谱G\mathcal{G}G, 它由实体关系实体(entity-relation-entity)的三元组(h,r,t)(h, r, t)(h,r,t)组成,其中分别表示head,relation,和tail。例如(Quentin Tarantino, film.director.film, Pulp Fiction)就表示Quentin Tarantino监制了电影Pulp Fiction。而在推荐场景中, 一个商品v∈Vv \in \mathcal{V}v∈V可能和G\mathcal{G}G中的一个或者多个实体关联。例如在电影推荐中, Pulp Fiction可能和它一个同名的关联,但是在新闻推荐中,标题名字为”Trump pledges aid to Silicon Valley during tech meeting”在知识图谱中就和实体"Donald Trump"以及"Silicon Valley"相关联。
1.2. 问题定义
给定用户和商品的交互矩阵YYY以及知识图谱G\mathcal{G}G,我们希望预测用户对于之前从未有交互的商品是否存在潜在的兴趣?所以我们的目标就是:
- yˉuv=F(u,v∣Θ,Y,G)\bar{y}_{u v}=\mathcal{F}(u, v \mid \Theta, Y, \mathcal{G})yˉuv=F(u,v∣Θ,Y,G)
其中yˉuv\bar{y}_{u v}yˉuv为用户uuu和商品vvv交互的Θ\ThetaΘ概率,F\mathcal{F}F为函数的参数,
2. 模型框架
本文的整体模型框架如下:
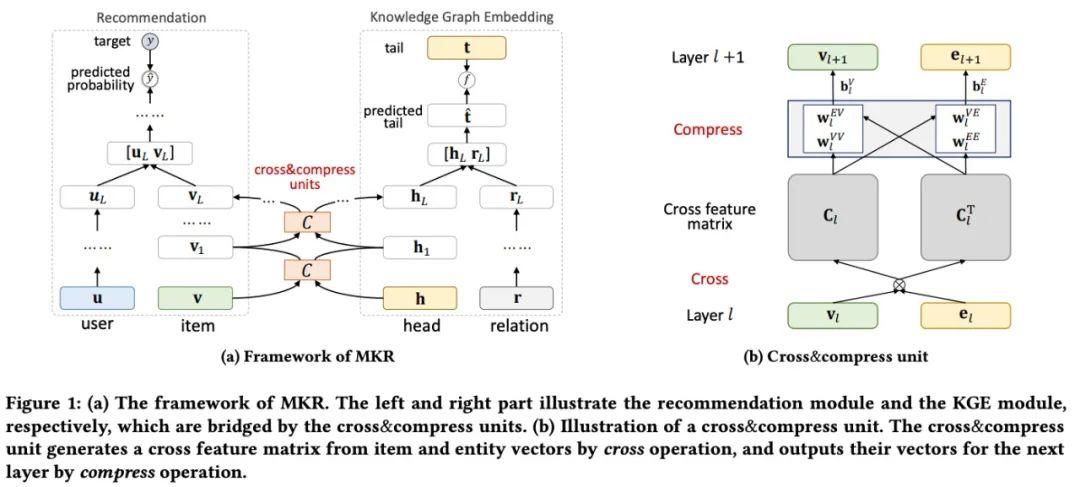
MKR由三个模块组成:
- 推荐模块:使用用户和商品作为输入并且使用MLP和cross&compress单元分别抽取dense的用户和商品特征;抽取的特征然后输入到另一个MLP并输出预测概率;
- 右侧的KGE模型也使用了多层从head和知识三元组中抽取特征并且输出在分数函数fff和实际尾部监督下的尾部预测的表示;
- 推荐模块和KGE模块通过特殊设计的cross&compress单元进行连接。提出的单元还可以学习在推荐系统和KG中实体的高阶交叉信息。
2.1 Cross & compress 单元
为了建模商品和实体的特征交叉,我们设计了一个cross&compress单元。对于商品以及它所关联的实体,我们先构建影隐藏特征vl∈Rdv_{l} \in R^{d}vl∈Rd以及el∈Rde_{l} \in R^{d}el∈Rd的d∗dd * dd∗d个成对交叉。
Cl=vlelT=[vl(1)el(1)…vl(1)el(d)………vl(d)el(1)…vl(d)el(d)]∈Rd∗d C_{l}=v_{l} e_{l}^{T}=\left[\begin{array}{ccc} v_{l}^{(1)} e_{l}^{(1)} & \ldots & v_{l}^{(1)} e_{l}^{(d)} \\ \ldots & \ldots & \ldots \\ v_{l}^{(d)} e_{l}^{(1)} & \ldots & v_{l}^{(d)} e_{l}^{(d)} \end{array}\right] \in R^{d * d} Cl=vlelT=⎣⎢⎡vl(1)el(1)…vl(d)el(1)………vl(1)el(d)…vl(d)el(d)⎦⎥⎤∈Rd∗d
ClC_{l}Cl是在第lll层的特征交叉矩阵, ddd是隐藏层的维度。
然后我们通过交叉特征矩阵将下一层的商品和实体特征向量映射到它们的潜在表示空间。
- vl+1=ClwlVV+ClTwlEV+blV=vlelTwlVV+elvlTwlEV+blVv_{l+1}=C_{l} w_{l}^{V V}+C_{l}^{T} w_{l}^{E V}+b_{l}^{V}=v_{l} e_{l}^{T} w_{l}^{V V}+e_{l} v_{l}^{T} w_{l}^{E V}+b_{l}^{V}vl+1=ClwlVV+ClTwlEV+blV=vlelTwlVV+elvlTwlEV+blV
- el+1=ClwlVE+ClTwlEE+blE=vlelTwlVE+elvlTwlEE+blEe_{l+1}=C_{l} w_{l}^{V E}+C_{l}^{T} w_{l}^{E E}+b_{l}^{E}=v_{l} e_{l}^{T} w_{l}^{V E}+e_{l} v_{l}^{T} w_{l}^{E E}+b_{l}^{E}el+1=ClwlVE+ClTwlEE+blE=vlelTwlVE+elvlTwlEE+blE
其中, wl∈Rdw_{l} \in R^{d}wl∈Rd,bl∈Rdb_{l} \in R^{d}bl∈Rd是训练的权重和偏差向量。这个称为compress操作,因为我们将Rd∗dR^{d * d}Rd∗d投影到RdR^{d }Rd上。通过上面的操作,我们从水平和垂直方向进行了压缩。
cross&compress单元:[vl+1,el+1]=C(vl,el)\left[v_{l+1}, e_{l+1}\right]=C\left(v_{l}, e_{l}\right)[vl+1,el+1]=C(vl,el)
通过该操作,MKR可以自适应地调整知识迁移的权重并且学习两个任务的相关性。
注意:交叉压缩单元应该只存在于MKR的底层。在深层结构中,特征通常沿网络从广义(general)到特定(special)的转换,并且随着任务的不同性的增加,特征在更高层次的移植性会显著下降。因此,共享高层的信息有可能导致负迁移,特别是对于MKR中的异构任务。在MKR的高层中,商品的特征与用户特征混合,实体特征与关系特征混合。混合特征不适合共享,因为它们没有明确的关联。
2.2 推荐模块
MKR中的推荐模块由两个原始输入特征向量uuu和vvv组成, 给定用户uuu的原始特征向量,我们使用LLL层的MLP对其深层的语义信息进行抽取。
- uL=M(M(…M(u)))=ML(u)u_{L}=\mathcal{M}(\mathcal{M}(\ldots \mathcal{M}(u)))=\mathcal{M}^{L}(u)uL=M(M(…M(u)))=ML(u)
其中M(x)=σ(Wx+b)\mathcal{M}(x)=\sigma(W x+b)M(x)=σ(Wx+b)是全连接网络层, 对于商品vvv,我们使用LLL个cross&compress的单元抽取它的特征:
- vL=Ee∼S(v)[CL(v,e)[v]]v_{L}=E_{e \sim \mathcal{S}(v)}\left[C^{L}(v, e)[v]\right]vL=Ee∼S(v)[CL(v,e)[v]]
其中S(v)\mathcal{S}(v)S(v)是商品vvv的相关实体集合。
在获得用户uuu的潜在特征uLu_{L}uL以及商品vvv的潜在特征vLv_{L}vL之后,我们使用下面的方式对其进行预估:
- yˉuv=σ(fRS(uL,vL))\bar{y}_{u v}=\sigma\left(f_{R S}\left(u_{L}, v_{L}\right)\right)yˉuv=σ(fRS(uL,vL))
2.3 知识图谱Embedding模块
知识图谱embedding将实体以及关系embed到某个连续的向量空间中,和推荐模块类似, 对于给定的知识三元组(h,r,t)(h, r, t)(h,r,t),我们首先使用多个KaTeX parse error: Expected '}', got '&' at position 13: \text {cross&̲compress} 的单元以及非线性层来处理head hhh以及关系rrr的原始特征向量,最终它们的潜在向量被concatenate到一起, 之后再接上上K层的MLP预测ttt,
hL=Ev∼S(h)[CL(v,h)[e]]rL=ML(r)tˉ=MK(hLrL) h_{L}=E_{v \sim \mathcal{S}(h)}\left[\mathcal{C}^{L}(v, h)[e]\right] r_{L}=\mathcal{M}^{L}(r) \bar{t}=\mathcal{M}^{K}\left(\begin{array}{l} h_{L} \\ r_{L} \end{array}\right) hL=Ev∼S(h)[CL(v,h)[e]]rL=ML(r)tˉ=MK(hLrL)
其中S\mathcal{S}S是和实体hhh相关的商品集合, tˉ\bar{t}tˉ是尾部的预测向量,最终,(h,r,t)(h, r, t)(h,r,t)三元组通过得分函数fKGf_{K G}fKG计算得到:
- score(h,r,t)=fKG(t,tˉ)\operatorname{score}(h, r, t)=f_{K G}(t, \bar{t})score(h,r,t)=fKG(t,tˉ)
我们使用正则化的内积fKG(t,tˉ)=σ(tTtˉ)f_{K G}(t, \bar{t})=\sigma\left(t^{T} \bar{t}\right)fKG(t,tˉ)=σ(tTtˉ)作为得分函数。
2.4 学习算法
MKR的最终Loss为:
L=LRS+LKG+LREG=∑u∈U,v∈VJ(yˉuv,yuv)−λ1(∑(h,r,t)∈Gscore(h,r,t)−∑(h′,r′,t′)∉Gscore(h′,r,t′))+λ2∥W∥22 \mathcal{L}=\mathcal{L}_{R S}+\mathcal{L}_{K G}+\mathcal{L}_{R E G}=\sum_{u \in U, v \in V} \mathcal{J}\left(\bar{y}_{u v}, y_{u v}\right)-\lambda_{1}\left(\sum_{(h, r, t) \in \mathcal{G}} \operatorname{score}(h, r, t)-\sum_{\left(h^{\prime}, r^{\prime}, t^{\prime}\right) \notin \mathcal{G}} \operatorname{score}\left(h^{\prime}, r, t^{\prime}\right)\right)+\lambda_{2}\|W\|_{2}^{2} L=LRS+LKG+LREG=u∈U,v∈V∑J(yˉuv,yuv)−λ1⎝⎛(h,r,t)∈G∑score(h,r,t)−(h′,r′,t′)∈/G∑score(h′,r,t′)⎠⎞+λ2∥W∥22
上面式子中, J\mathcal{J}J是交叉熵函数, 用来计算推荐模块的损失; 第二项计算KGE模块的损失, 其中我们希望增加所有正的三元组的分数同时减少所有负的三元组的分数。最后一项是正则项。

3. 理论分析
cross&compress的单元有足够的多项式近似的能力。证明略。
1. 和Baseline比较
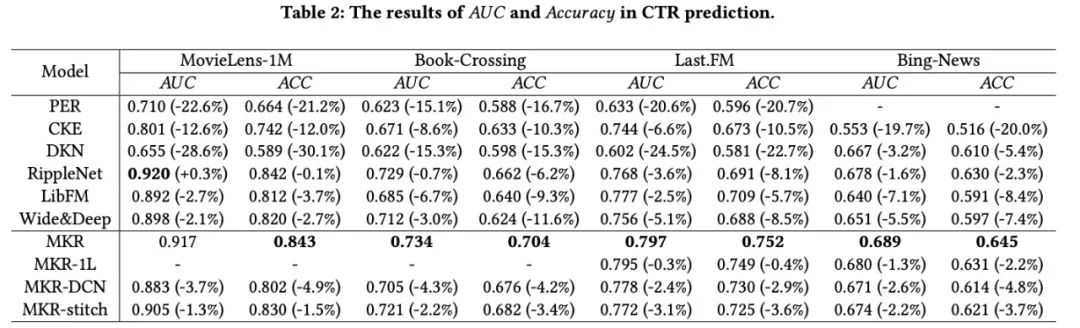
- MKR在四个数据集上对比其他所有方法都取得了最好的效果;
2. 和MKR的变种比较
- MKR中设计的交叉策略可以学习到更加高阶的信息,取得更好的效果
3. 在稀疏场景下的情况
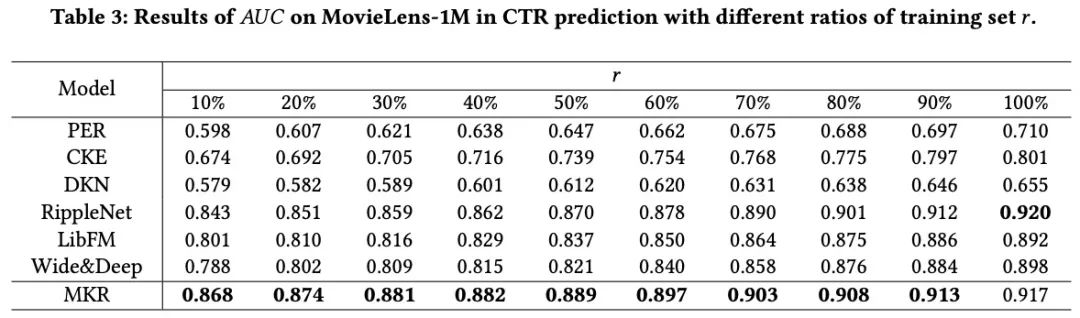
- 和其他模型对比, MKR在数据稀疏的情况下下降是最少的,这也验证了模型MKR当用户商品交叉较少的情况下依然可以取得不错的效果;
4. KGE side的结果
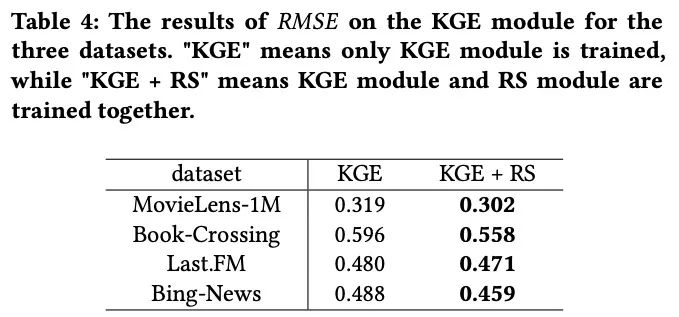
- RS的任务也可以帮助KGE任务,这也说明了multi-task learning可以利用共享信息帮助提升所有任务的效果。
5. 参数敏感度(KG:Knowledge Graph, KGE:Knowledge Graph Embedding)
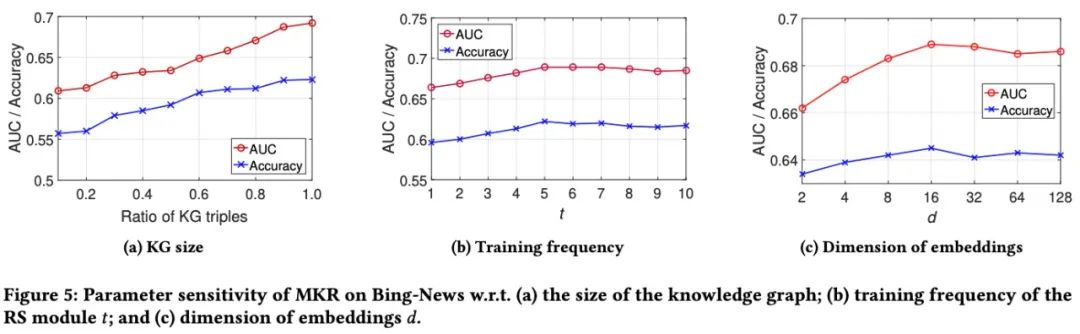
- KG大小的影响: Bing-News的效果随着KG size的变大而稳定变好;
- RS的训练频率: MKR前期会随着训练频次的增加而变好,但是到达某个值t=5之后,效果会略有下降,这可能是因为KGE模块的高训练频率会误导MKR的目标函数,而KGE训练频率太小则无法充分利用KG传递的知识;
- Embedding维度的影响:随着embedding维度的增大, 效果前期会有提升,但是到后面之后会慢慢变差一些,这可能是因为过大的embedding维度会引入噪音的问题;
小结1
训练频率会误导MKR的目标函数,而KGE训练频率太小则无法充分利用KG传递的知识;
- Embedding维度的影响:随着embedding维度的增大, 效果前期会有提升,但是到后面之后会慢慢变差一些,这可能是因为过大的embedding维度会引入噪音的问题;
小结2
提出了一种多任务学习的知识图增强推荐方法MKR。MKR是一个端到端的深度模型框架,由两部分组成:推荐模块和KGE模块。两个模块都采用多个非线性层来提取输入的潜在特征,以适应用户商品和头部关系对之间复杂的交互作用。由于这两个任务不是独立的,而是通过商品和实体联系在一起的,因此我们在MKR中设计了一个交叉压缩单元来关联这两个任务,它可以自动学习项目和实体特征的高阶交互,并在两个任务之间传递知识。在四个推荐场景中进行了大量的实验。结果表明MKR比强基线有显著的优越性和KG的使用效果。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)