python sample函数 frac_Python数据分析--------numpy数据打乱
一、shuffle函数:import numpy.randomdef shuffleData(data):np.random.shufflr(data)cols=data.shape[1]X=data[:,0:cols-1]Y=data[:,cols-1:]return X,Y二、np.random.permutation()函数这个函数的使用来随机排列一个数组的,一维数组: 对多维数组来说,是多
一、shuffle函数:
import numpy.random
def shuffleData(data):
np.random.shufflr(data)
cols=data.shape[1]
X=data[:,0:cols-1]
Y=data[:,cols-1:]
return X,Y
二、np.random.permutation()函数
这个函数的使用来随机排列一个数组的,
一维数组:

对多维数组来说,是多维随机打乱而不是1维,例如:

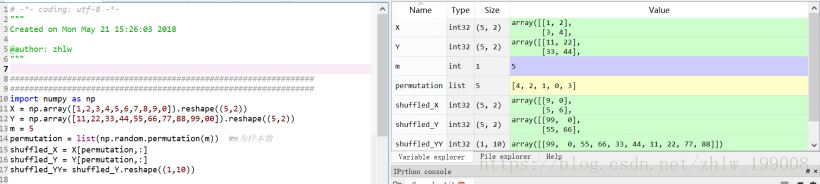
如果要利用次函数对输入数据X、Y进行随机排序,且要求随机排序后的X Y中的值保持原来的对应关系,可以这样处理:
permutation = list(np.random.permutation(m)) #m为样本数
shuffled_X = X[permutation]
shuffled_Y = Y[permutation].reshape((1,m))
图4中的代码是针对一维数组来说的,(图片中右侧为运行结果):

图5中的代码是针对二维数组来说的:
https://blog.csdn.net/zhlw_199008/article/details/80569167
三、sameple函数
sample()参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3
以下代码实现了从“CRASHSEV”中选出1,2,3,4的属性,乱序,然后取出前10000行,按行链接成新的数据,重建索引:
defunbanlance(un_data):
data1= un_data.loc[(data["CRASHSEV"] == 1)].sample(frac=1).iloc[:10000, :]
data2= un_data.loc[(data["CRASHSEV"] == 2)].sample(frac=1).iloc[:10000, :]
data3= un_data.loc[(data["CRASHSEV"] == 3)].sample(frac=1).iloc[:10000, :]
data4= un_data.loc[(data["CRASHSEV"] == 4)].sample(frac=1).iloc[:10000, :]
ba_data= pd.concat([data1,data2,data3,data4], axis=0).sample(frac=1).reset_index(drop=True) #0是按行链接
return ba_data

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)