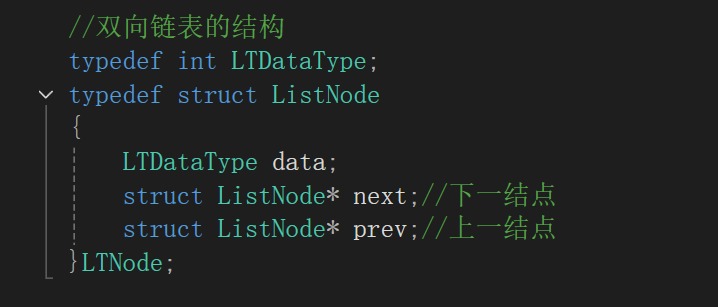
【数据结构】双链表
带头双向循环链表是一种特殊的链表结构,其特点是每个节点都有指向前一个节点和后一个节点的指针(prev和next),且链表头尾相连形成循环。链表的“头结点”实际上是一个哨兵位,不存储有效数据,仅用于简化操作。与单链表相比,双链表在插入和删除操作上更为高效,时间复杂度为O(1)。双链表的实现包括分配空间、初始化、尾插、头插、尾删、头删、查找和销毁等操作。初始化时推荐在函数内部直接创建新空间并返回指针。
一 概念和结构
带头双向循环链表
|一一一一一一 |
[head]=[d1]=[d2]=[d3]
|____________|
注意:这里的“带头”跟前面我们说的“头结点”是两个概念,实际前面的在单链表阶段称呼不严谨,但是为了同学们更好的理解就直接称为单链表的头结点。
带头链表里的头结点,实际为“哨兵位”,哨兵位结点不存储任何有效元素,只是站在这里“放哨的”
与单链表最大的区别就是,双链表多了一份指向上一个结点的指针prev。
二 实现双链表
1.分配空间
与单链表一样,每一个结点都需要分配新的空间
但是此时结点的next prev指针都是指向自身的。

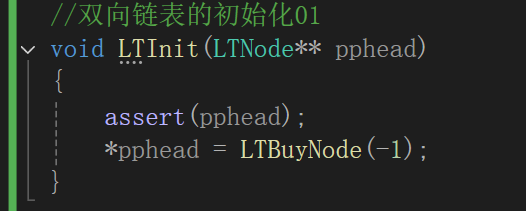
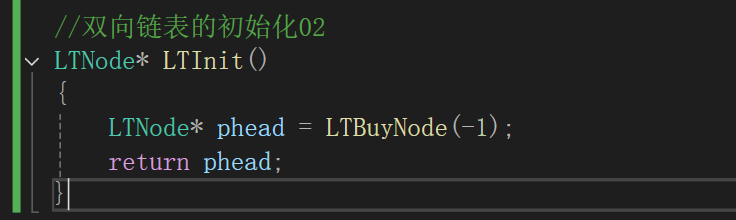
2.初始化
双链表的初始化有两种
第一种就是传入头结点的地址,再创建空间进行数据初始化。
第二种就是,在函数内部直接创建新空间, 然后返回指针类型
这里更推荐第二种,具体原因会在后续介绍。
3.尾插
双链表的尾插相比于单链表会更复杂,但不需要遍历到尾结点,且并不用传入双指针,应为双链表的头结点(哨兵位结点)是不用更改的,所以不用使用传址调用。
注意
要理清各结点的next 和 prev指向的位置。
phead------>(phead->prev)尾节点 所以newnode要插入到尾结点后面。
在更改指针的时候,要先更改newnode的指针,提前更改了原链表的指针会打乱链表顺序(画图一看就很清楚)

时间复杂度O(1)
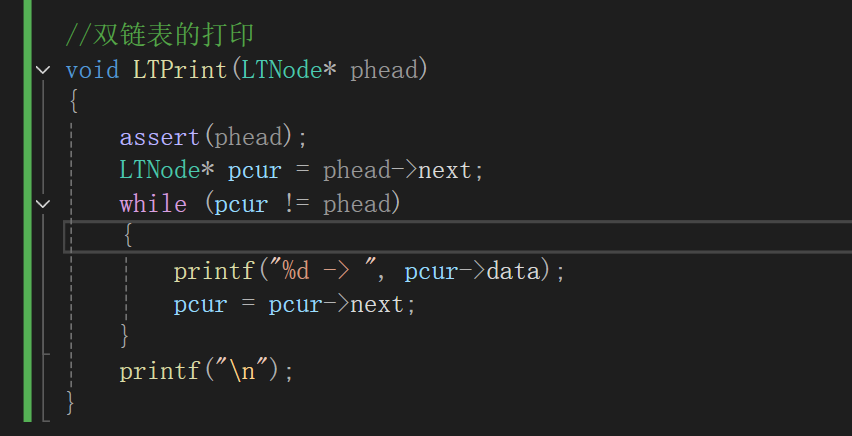
4.双链表的打印
这里值得注意的就是循环的条件
由于该链表是循环链表,所以用传统的!=NULL会陷入死循环,在这里我们改成!=phead
5.头插
与尾插相似,
先理清位置关系phead newnode phead->next
更改指针的时候先更改newnode的指针。

时间复杂度O(1)
6.尾删
同样也是画图理清位置关系即可。

时间复杂度O(1)
7.头删
同尾删

时间复杂度O(1)
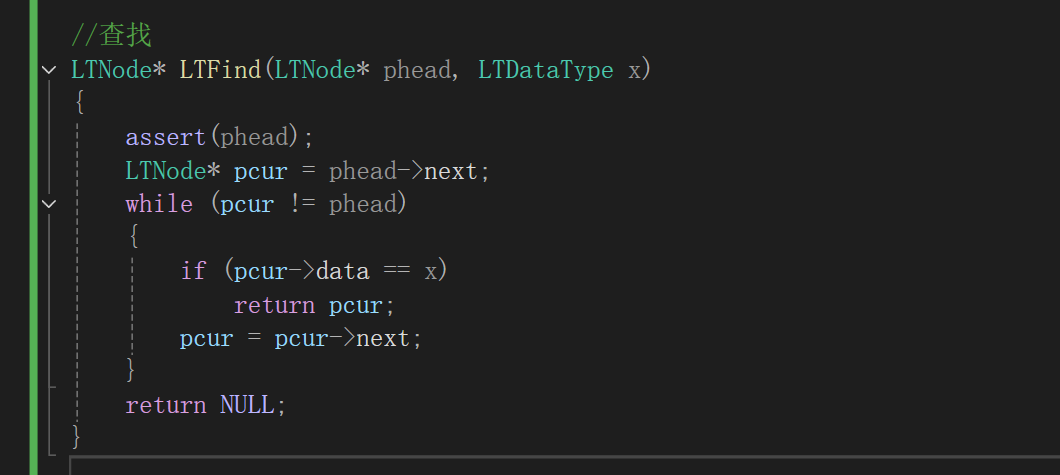
8.查找
注意几点:
pcur 指向的是phead->next
循环条件是pcur!=phead
9.销毁
第一种:传入二级指针
因为此操作需要对头结点进行更改,所以使用传址调用
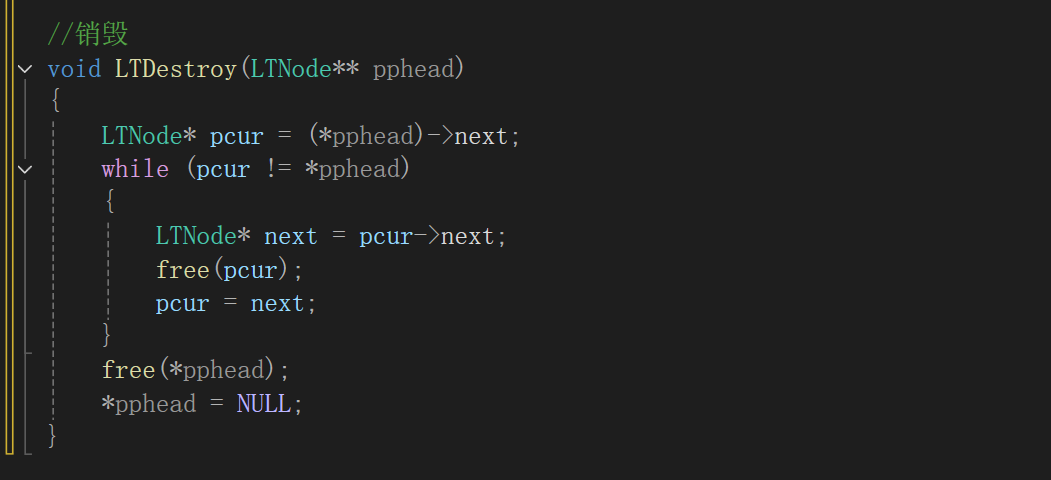
违背了接口一致性(都传一级指针,但这个是二级指针)
第二种:传入一级指
变为一级指针,函数内容不变。
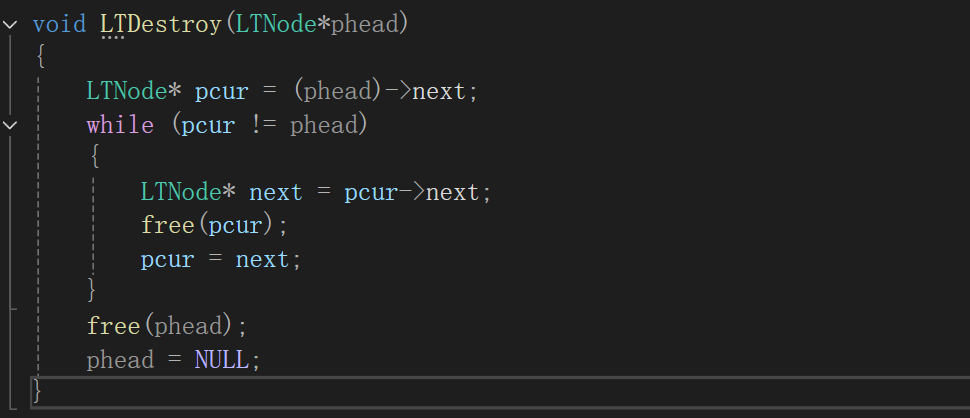
注意:在销毁链表后,需要手动把链表free掉。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)