Anaconda环境配置Python数据分析库Pandas的方法
本文介绍在Anaconda环境中,安装Python语言pandas模块的方法~
本文介绍在Anaconda环境中,安装Python语言pandas模块的方法。
pandas模块是一个基于NumPy的开源数据分析库,提供了快速、灵活、易用的数据结构和数据分析工具。它的主要数据结构是Series和DataFrame,可以处理各种数据格式,如CSV、Excel、SQL数据库等,并且支持数据清洗、缺失值处理、数据重组、数据分析和可视化等功能。在之前的文章中,我们也多次介绍了Python语言pandas库的使用;而这篇文章,就介绍一下在Anaconda环境下,配置这一库的方法。
首先,打开Anaconda Prompt软件,如下图所示。
在这里,由于我是希望在一个名称为py38的Python虚拟环境中配置pandas库,因此首先通过如下的代码进入这一环境;关于虚拟环境的创建与进入,大家可以参考文章Anaconda中Python虚拟环境的创建、使用与删除(https://blog.csdn.net/zhebushibiaoshifu/article/details/128334614)。
activate py38
运行上述代码,即可进入指定的虚拟环境中。随后,我们输入如下的代码。
conda install -c anaconda pandas
运行上述代码,稍等片刻即可出现如下图所示的字样。
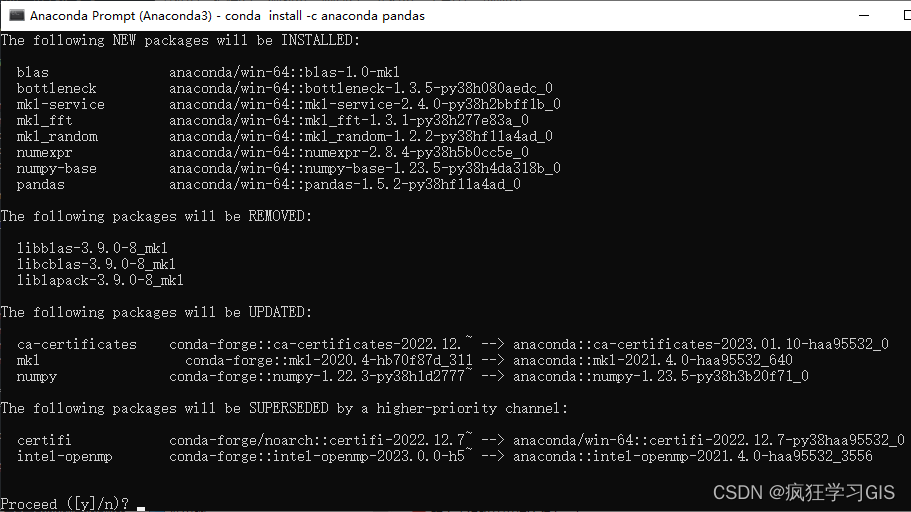
接下来,输入y即可开始pandas库的配置工作。再稍等片刻,出现如下图所示的情况,即说明pandas库已经配置完毕。
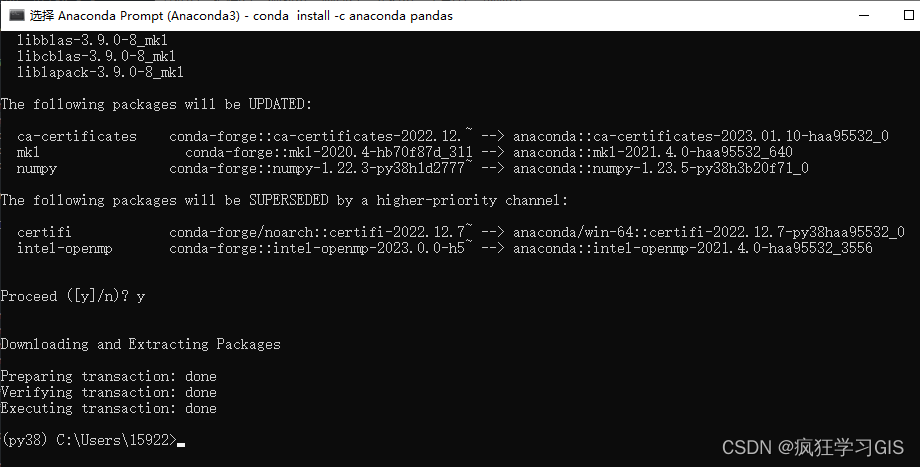
此时,我们可以通过如下图所示的代码,检查是否成功完成pandas库的配置工作。
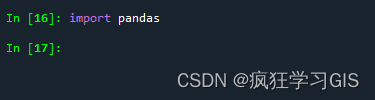
如果没有报错, 说明pandas库已经成功配置。
至此,大功告成。
欢迎关注:疯狂学习GIS

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)